 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAT-Coder-V2 Technical Report
Mar 29, 2026We present KAT-Coder-V2, an agentic coding model developed by the KwaiKAT team at Kuaishou. KAT-Coder-V2 adopts a "Specialize-then-Unify" paradigm that decomposes agentic coding into five expert domains - SWE, WebCoding, Terminal, WebSearch, and General - each undergoing independent supervised fine-tuning and reinforcement learning, before being consolidated into a single model via on-policy distillation. We develop KwaiEnv, a modular infrastructure sustaining tens of thousands of concurrent sandbox instances, and scale RL training along task complexity, intent alignment, and scaffold generalization. We further propose MCLA for stabilizing MoE RL training and Tree Training for eliminating redundant computation over tree-structured trajectories with up to 6.2x speedup. KAT-Coder-V2 achieves 79.6% on SWE-bench Verified (vs. Claude Opus 4.6 at 80.8%), 88.7 on PinchBench (surpassing GLM-5 and MiniMax M2.7), ranks first across all three frontend aesthetics scenarios, and maintains strong generalist scores on Terminal-Bench Hard (46.8) and tau^2-Bench (93.9). Our model is publicly available at https://streamlake.com/product/kat-coder.
Ran Score: a LLM-based Evaluation Score for Radiology Report Generation
Mar 24, 2026Chest X-ray report generation and automated evaluation are limited by poor recognition of low-prevalence abnormalities and inadequate handling of clinically important language, including negation and ambiguity. We develop a clinician-guided framework combining human expertise and large language models for multi-label finding extraction from free-text chest X-ray reports and use it to define Ran Score, a finding-level metric for report evaluation. Using three non-overlapping MIMIC-CXR-EN cohorts from a public chest X-ray dataset and an independent ChestX-CN validation cohort, we optimize prompts, establish radiologist-derived reference labels and evaluate report generation models. The optimized framework improves the macro-averaged score from 0.753 to 0.956 on the MIMIC-CXR-EN development cohort, exceeds the CheXbert benchmark by 15.7 percentage points on directly comparable labels, and shows robust generalization on the ChestX-CN validation cohort. Here we show that clinician-guided prompt optimization improves agreement with a radiologist-derived reference standard and that Ran Score enables finding-level evaluation of report fidelity, particularly for low-prevalence abnormalities.
Plug-and-Play Performance Estimation for LLM Services without Relying on Labeled Data
Oct 10, 2024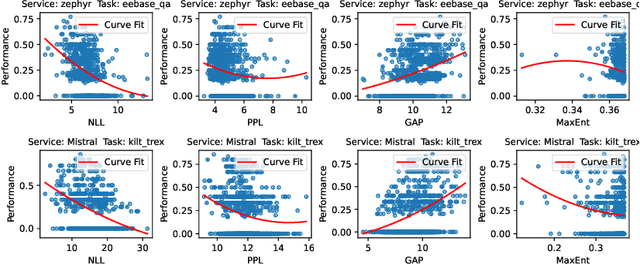
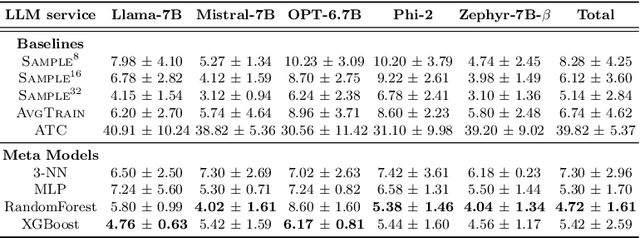
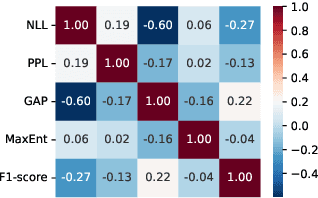
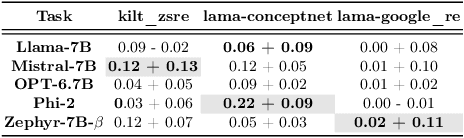
Large Language Model (LLM) services exhibit impressive capability on unlearned tasks leveraging only a few examples by in-context learning (ICL). However, the success of ICL varies depending on the task and context, leading to heterogeneous service quality. Directly estimating the performance of LLM services at each invocation can be laborious, especially requiring abundant labeled data or internal information within the LLM. This paper introduces a novel method to estimate the performance of LLM services across different tasks and contexts, which can be "plug-and-play" utilizing only a few unlabeled samples like ICL. Our findings suggest that the negative log-likelihood and perplexity derived from LLM service invocation can function as effective and significant features. Based on these features, we utilize four distinct meta-models to estimate the performance of LLM services. Our proposed method is compared against unlabeled estimation baselines across multiple LLM services and tasks. And it is experimentally applied to two scenarios, demonstrating its effectiveness in the selection and further optimization of LLM services.