 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Router for Vision-Language Model Selection
Jun 08, 2026Vision-language models (VLMs) with varying performance and resource requirements are widely deployed, making it difficult for users to select the most appropriate one among numerous VLM candidates. Existing work reveals the performance paradox phenomenon in language models and focuses on routing methods to solve it. However, developing a router for VLM selection is still a critical yet challenging problem, which primarily faces: 1) lack of specialized data, 2) ineffective feature representation, and 3) rigid model space and costly adaptation. In this paper, we construct a multimodal dataset for VLM selection, containing the outputs of seven mainstream VLMs on 32,626 unique image-text queries. We then propose ARMS, a router for VLM selection. ARMS enhances input signals with VLM profiles, employs a simple but effective architecture to improve representations of queries and VLM capabilities. To improve ARMS' adaptation to new VLMs, we propose two extension training strategies: incremental training and independent training. Experimental results on both in-distribution and out-of-distribution test sets demonstrate the effectiveness of ARMS. In particular, using our training strategy, ARMs (only 800M in size) can adapt to a broader VLM space and defeat commercial models like GPT-4o that are hundreds of times larger in scale. Our code, models, and datasets are available in the anonymous repository.
Evidence-Based Intelligent Diagnostic and Therapeutic Visualization System with Large Language Models: Multi-Turn Interaction and Multimodal Treatment Plan Generation
Jun 05, 2026Aim: Existing AI-assisted traditional Chinese medicine diagnostic tools suffer from opaque reasoning processes, passive interaction, and limited treatment plan presentation. This study proposes a knowledge-enhanced visual diagnostic system to improve the transparency and interpretability of syndrome differentiation and treatment. Methods: The system is built upon a Neo4j knowledge graph comprising 241 syndromes, 1,263 symptoms, and 2,485 relations. It incorporates a four-stage symptom matching pipeline (exact, semantic, fuzzy, and large language model verification), an information gain-driven proactive questioning strategy optimized with genetic algorithms, and a multimodal treatment presentation integrating artificial intelligence-generated illustrations, three-dimensional meridian-acupoint models, and evidence-based literature. Results: Knowledge graph constraints reduced non-standard outputs by 32%. Case studies validated the effectiveness of the interactive workflow across patient self-assessment, clinician-assisted diagnosis, and traditional Chinese medicine education. Automated paired-comparison evaluation across 30 cases further demonstrated significant improvements in diagnostic trust (Cohen's d = 1.82, p < 0.001), reduced cognitive load (improvements in four of five dimensions), and higher credibility of evidence-based references (4.21 vs. 2.95). Conclusions: The proposed system enhances the transparency of traditional Chinese medicine diagnostic reasoning and the interpretability of treatment plans through knowledge graph-driven visualization and multimodal interaction, offering a practical solution for trustworthy artificial intelligence-assisted traditional Chinese medicine applications.
Multi-proposal Collaboration and Multi-task Training for Weakly-supervised Video Moment Retrieval
May 14, 2026This study focuses on weakly-supervised Video Moment Retrieval (VMR), aiming to identify a moment semantically similar to the given query within an untrimmed video using only video-level correspondences, without relying on temporal annotations during training. Previous methods either aggregate predictions for all instances in the video, or indirectly address the task by proposing reconstructions for the query. However, these methods often produce low-quality temporal proposals, struggle with distinguishing misaligned moments in the same video, or lack stability due to a reliance on a single auxiliary task. To address these limitations, we present a novel weakly-supervised method called Multi-proposal Collaboration and Multi-task Training (MCMT). Initially, we generate multiple proposals and derive corresponding learnable Gaussian masks from them. These masks are then combined to create a high-quality positive sample mask, highlighting video clips most relevant to the query. Concurrently, we classify other clips in the same video as the easy negative sample and the entire video as the hard negative sample. During training, we introduce forward and inverse masked query reconstruction tasks to impose more substantial constraints on the network, promoting more robust and stable retrieval performance. Extensive experiments on two standard benchmarks affirm the effectiveness of the proposed method in VMR.
* 26 pages, 4 figures. Preprint version of the article published in International Journal of Machine Learning and Cybernetics
ODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks
Aug 11, 2025
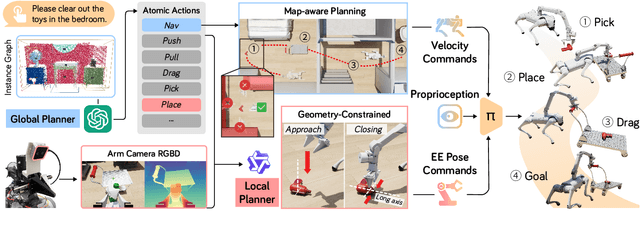


Language-guided long-horizon mobile manipulation has long been a grand challenge in embodied semantic reasoning, generalizable manipulation, and adaptive locomotion. Three fundamental limitations hinder progress: First, although large language models have improved spatial reasoning and task planning through semantic priors, existing implementations remain confined to tabletop scenarios, failing to address the constrained perception and limited actuation ranges of mobile platforms. Second, current manipulation strategies exhibit insufficient generalization when confronted with the diverse object configurations encountered in open-world environments. Third, while crucial for practical deployment, the dual requirement of maintaining high platform maneuverability alongside precise end-effector control in unstructured settings remains understudied. In this work, we present ODYSSEY, a unified mobile manipulation framework for agile quadruped robots equipped with manipulators, which seamlessly integrates high-level task planning with low-level whole-body control. To address the challenge of egocentric perception in language-conditioned tasks, we introduce a hierarchical planner powered by a vision-language model, enabling long-horizon instruction decomposition and precise action execution. At the control level, our novel whole-body policy achieves robust coordination across challenging terrains. We further present the first benchmark for long-horizon mobile manipulation, evaluating diverse indoor and outdoor scenarios. Through successful sim-to-real transfer, we demonstrate the system's generalization and robustness in real-world deployments, underscoring the practicality of legged manipulators in unstructured environments. Our work advances the feasibility of generalized robotic assistants capable of complex, dynamic tasks. Our project page: https://kaijwang.github.io/odyssey.github.io/
Temporal-Aware Spiking Transformer Hashing Based on 3D-DWT
Jan 12, 2025With the rapid growth of dynamic vision sensor (DVS) data, constructing a low-energy, efficient data retrieval system has become an urgent task. Hash learning is one of the most important retrieval technologies which can keep the distance between hash codes consistent with the distance between DVS data. As spiking neural networks (SNNs) can encode information through spikes, they demonstrate great potential in promoting energy efficiency. Based on the binary characteristics of SNNs, we first propose a novel supervised hashing method named Spikinghash with a hierarchical lightweight structure. Spiking WaveMixer (SWM) is deployed in shallow layers, utilizing a multilevel 3D discrete wavelet transform (3D-DWT) to decouple spatiotemporal features into various low-frequency and high frequency components, and then employing efficient spectral feature fusion. SWM can effectively capture the temporal dependencies and local spatial features. Spiking Self-Attention (SSA) is deployed in deeper layers to further extract global spatiotemporal information. We also design a hash layer utilizing binary characteristic of SNNs, which integrates information over multiple time steps to generate final hash codes. Furthermore, we propose a new dynamic soft similarity loss for SNNs, which utilizes membrane potentials to construct a learnable similarity matrix as soft labels to fully capture the similarity differences between classes and compensate information loss in SNNs, thereby improving retrieval performance. Experiments on multiple datasets demonstrate that Spikinghash can achieve state-of-the-art results with low energy consumption and fewer parameters.
Plug-and-Play Performance Estimation for LLM Services without Relying on Labeled Data
Oct 10, 2024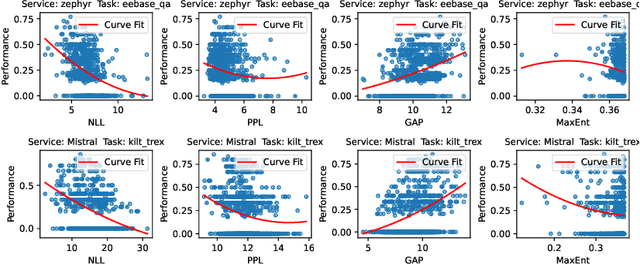
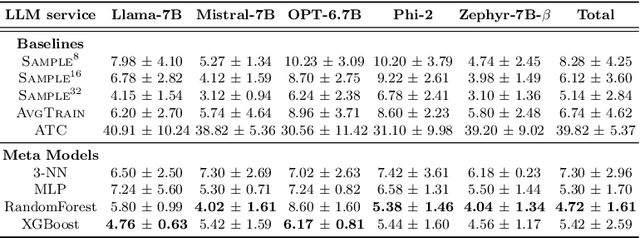
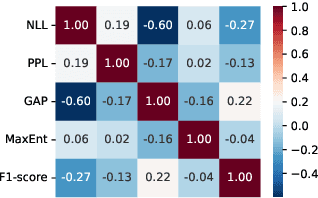
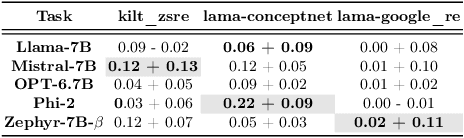
Large Language Model (LLM) services exhibit impressive capability on unlearned tasks leveraging only a few examples by in-context learning (ICL). However, the success of ICL varies depending on the task and context, leading to heterogeneous service quality. Directly estimating the performance of LLM services at each invocation can be laborious, especially requiring abundant labeled data or internal information within the LLM. This paper introduces a novel method to estimate the performance of LLM services across different tasks and contexts, which can be "plug-and-play" utilizing only a few unlabeled samples like ICL. Our findings suggest that the negative log-likelihood and perplexity derived from LLM service invocation can function as effective and significant features. Based on these features, we utilize four distinct meta-models to estimate the performance of LLM services. Our proposed method is compared against unlabeled estimation baselines across multiple LLM services and tasks. And it is experimentally applied to two scenarios, demonstrating its effectiveness in the selection and further optimization of LLM services.
HBot: A Chatbot for Healthcare Applications in Traditional Chinese Medicine Based on Human Body 3D Visualization
Aug 01, 2024


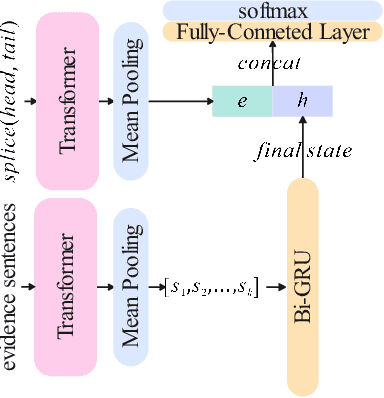
The unique diagnosis and treatment techniques and remarkable clinical efficacy of traditional Chinese medicine (TCM) make it play an important role in the field of elderly care and healthcare, especially in the rehabilitation of some common chronic diseases of the elderly. Therefore, building a TCM chatbot for healthcare application will help users obtain consultation services in a direct and natural way. However, concepts such as acupuncture points (acupoints) and meridians involved in TCM always appear in the consultation, which cannot be displayed intuitively. To this end, we develop a \textbf{h}ealthcare chat\textbf{bot} (HBot) based on a human body model in 3D and knowledge graph, which provides conversational services such as knowledge Q\&A, prescription recommendation, moxibustion therapy recommendation, and acupoint search. When specific acupoints are involved in the conversations between user and HBot, the 3D body will jump to the corresponding acupoints and highlight them. Moreover, Hbot can also be used in training scenarios to accelerate the teaching process of TCM by intuitively displaying acupuncture points and knowledge cards. The demonstration video is available at https://www.youtube.com/watch?v=UhQhutSKkTU . Our code and dataset are publicly available at Gitee: https://gitee.com/plabrolin/interactive-3d-acup.git
A Survey on Data Selection for LLM Instruction Tuning
Feb 04, 2024



Instruction tuning is a vital step of training large language models (LLM), so how to enhance the effect of instruction tuning has received increased attention. Existing works indicate that the quality of the dataset is more crucial than the quantity during instruction tuning of LLM. Therefore, recently a lot of studies focus on exploring the methods of selecting high-quality subset from instruction datasets, aiming to reduce training costs and enhance the instruction-following capabilities of LLMs. This paper presents a comprehensive survey on data selection for LLM instruction tuning. Firstly, we introduce the wildly used instruction datasets. Then, we propose a new taxonomy of the data selection methods and provide a detailed introduction of recent advances,and the evaluation strategies and results of data selection methods are also elaborated in detail. Finally, we emphasize the open challenges and present new frontiers of this task.
HeroNet: A Hybrid Retrieval-Generation Network for Conversational Bots
Feb 08, 2023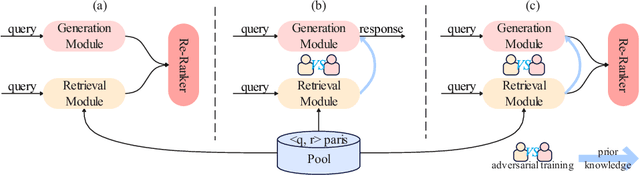

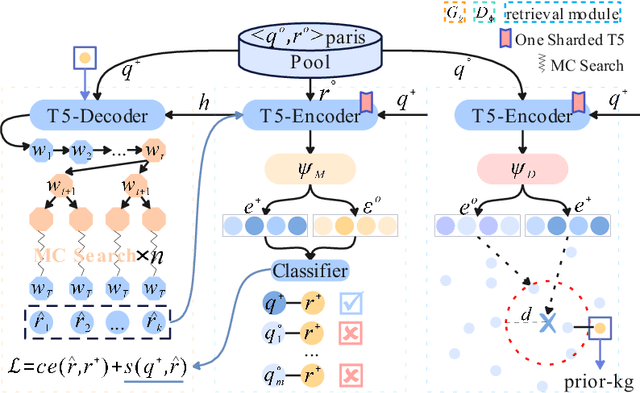
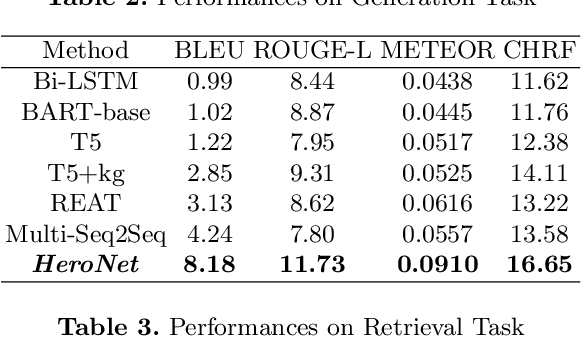
Using natural language, Conversational Bot offers unprecedented ways to many challenges in areas such as information searching, item recommendation, and question answering. Existing bots are usually developed through retrieval-based or generative-based approaches, yet both of them have their own advantages and disadvantages. To assemble this two approaches, we propose a hybrid retrieval-generation network (HeroNet) with the three-fold ideas: 1). To produce high-quality sentence representations, HeroNet performs multi-task learning on two subtasks: Similar Queries Discovery and Query-Response Matching. Specifically, the retrieval performance is improved while the model size is reduced by training two lightweight, task-specific adapter modules that share only one underlying T5-Encoder model. 2). By introducing adversarial training, HeroNet is able to solve both retrieval\&generation tasks simultaneously while maximizing performance of each other. 3). The retrieval results are used as prior knowledge to improve the generation performance while the generative result are scored by the discriminator and their scores are integrated into the generator's cross-entropy loss function. The experimental results on a open dataset demonstrate the effectiveness of the HeroNet and our code is available at https://github.com/TempHero/HeroNet.git
Requirements Elicitation in Cognitive Service for Recommendation
Mar 29, 2022

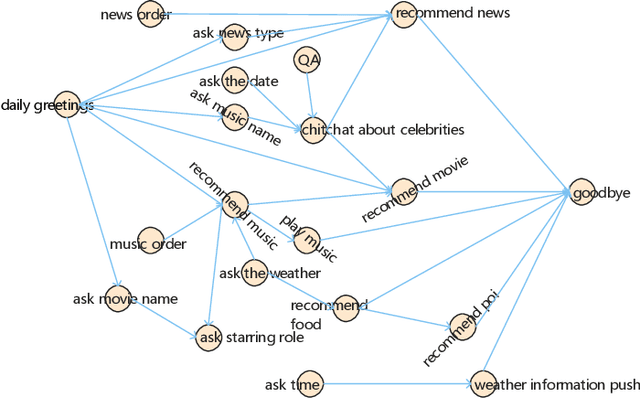
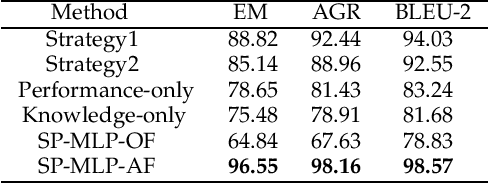
Nowadays, cognitive service provides more interactive way to understand users' requirements via human-machine conversation. In other words, it has to capture users' requirements from their utterance and respond them with the relevant and suitable service resources. To this end, two phases must be applied: I.Sequence planning and Real-time detection of user requirement, II.Service resource selection and Response generation. The existing works ignore the potential connection between these two phases. To model their connection, Two-Phase Requirement Elicitation Method is proposed. For the phase I, this paper proposes a user requirement elicitation framework (URef) to plan a potential requirement sequence grounded on user profile and personal knowledge base before the conversation. In addition, it can also predict user's true requirement and judge whether the requirement is completed based on the user's utterance during the conversation. For the phase II, this paper proposes a response generation model based on attention, SaRSNet. It can select the appropriate resource (i.e. knowledge triple) in line with the requirement predicted by URef, and then generates a suitable response for recommendation. The experimental results on the open dataset \emph{DuRecDial} have been significantly improved compared to the baseline, which proves the effectiveness of the proposed methods.