 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Grounded Responses to Counter Misinformation via Learning Efficient Fine-Grained Critiques
Jun 06, 2025Fake news and misinformation poses a significant threat to society, making efficient mitigation essential. However, manual fact-checking is costly and lacks scalability. Large Language Models (LLMs) offer promise in automating counter-response generation to mitigate misinformation, but a critical challenge lies in their tendency to hallucinate non-factual information. Existing models mainly rely on LLM self-feedback to reduce hallucination, but this approach is computationally expensive. In this paper, we propose MisMitiFact, Misinformation Mitigation grounded in Facts, an efficient framework for generating fact-grounded counter-responses at scale. MisMitiFact generates simple critique feedback to refine LLM outputs, ensuring responses are grounded in evidence. We develop lightweight, fine-grained critique models trained on data sourced from readily available fact-checking sites to identify and correct errors in key elements such as numerals, entities, and topics in LLM generations. Experiments show that MisMitiFact generates counter-responses of comparable quality to LLMs' self-feedback while using significantly smaller critique models. Importantly, it achieves ~5x increase in feedback generation throughput, making it highly suitable for cost-effective, large-scale misinformation mitigation. Code and LLM prompt templates are at https://github.com/xxfwin/MisMitiFact.
COutfitGAN: Learning to Synthesize Compatible Outfits Supervised by Silhouette Masks and Fashion Styles
Feb 12, 2025



How to recommend outfits has gained considerable attention in both academia and industry in recent years. Many studies have been carried out regarding fashion compatibility learning, to determine whether the fashion items in an outfit are compatible or not. These methods mainly focus on evaluating the compatibility of existing outfits and rarely consider applying such knowledge to 'design' new fashion items. We propose the new task of generating complementary and compatible fashion items based on an arbitrary number of given fashion items. In particular, given some fashion items that can make up an outfit, the aim of this paper is to synthesize photo-realistic images of other, complementary, fashion items that are compatible with the given ones. To achieve this, we propose an outfit generation framework, referred to as COutfitGAN, which includes a pyramid style extractor, an outfit generator, a UNet-based real/fake discriminator, and a collocation discriminator. To train and evaluate this framework, we collected a large-scale fashion outfit dataset with over 200K outfits and 800K fashion items from the Internet. Extensive experiments show that COutfitGAN outperforms other baselines in terms of similarity, authenticity, and compatibility measurements.
Teaching Large Language Models Number-Focused Headline Generation With Key Element Rationales
Feb 05, 2025Number-focused headline generation is a summarization task requiring both high textual quality and precise numerical accuracy, which poses a unique challenge for Large Language Models (LLMs). Existing studies in the literature focus only on either textual quality or numerical reasoning and thus are inadequate to address this challenge. In this paper, we propose a novel chain-of-thought framework for using rationales comprising key elements of the Topic, Entities, and Numerical reasoning (TEN) in news articles to enhance the capability for LLMs to generate topic-aligned high-quality texts with precise numerical accuracy. Specifically, a teacher LLM is employed to generate TEN rationales as supervision data, which are then used to teach and fine-tune a student LLM. Our approach teaches the student LLM automatic generation of rationales with enhanced capability for numerical reasoning and topic-aligned numerical headline generation. Experiments show that our approach achieves superior performance in both textual quality and numerical accuracy.
Enhancing the Traditional Chinese Medicine Capabilities of Large Language Model through Reinforcement Learning from AI Feedback
Nov 01, 2024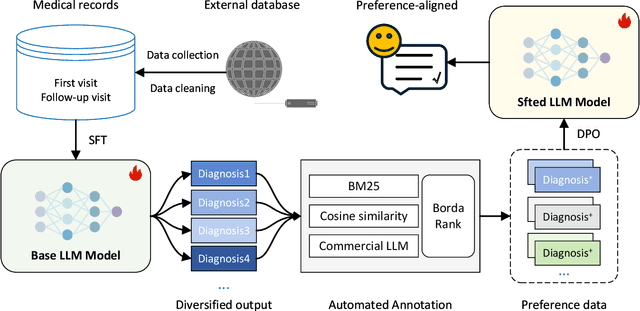
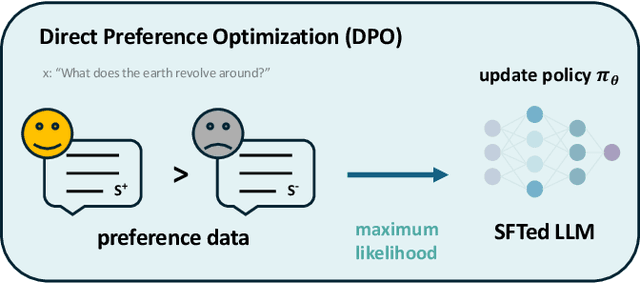


Although large language models perform well in understanding and responding to user intent, their performance in specialized domains such as Traditional Chinese Medicine (TCM) remains limited due to lack of expertise. In addition, high-quality data related to TCM is scarce and difficult to obtain, making large language models ineffective in handling TCM tasks. In this work, we propose a framework to improve the performance of large language models for TCM tasks using only a small amount of data. First, we use medical case data for supervised fine-tuning of the large model, making it initially capable of performing TCM tasks. Subsequently, we further optimize the model's performance using reinforcement learning from AI feedback (RLAIF) to align it with the preference data. The ablation study also demonstrated the performance gain is attributed to both supervised fine-tuning and the direct policy optimization. The experimental results show that the model trained with a small amount of data achieves a significant performance improvement on a representative TCM task.
Harnessing Network Effect for Fake News Mitigation: Selecting Debunkers via Self-Imitation Learning
Jan 28, 2024This study aims to minimize the influence of fake news on social networks by deploying debunkers to propagate true news. This is framed as a reinforcement learning problem, where, at each stage, one user is selected to propagate true news. A challenging issue is episodic reward where the "net" effect of selecting individual debunkers cannot be discerned from the interleaving information propagation on social networks, and only the collective effect from mitigation efforts can be observed. Existing Self-Imitation Learning (SIL) methods have shown promise in learning from episodic rewards, but are ill-suited to the real-world application of fake news mitigation because of their poor sample efficiency. To learn a more effective debunker selection policy for fake news mitigation, this study proposes NAGASIL - Negative sampling and state Augmented Generative Adversarial Self-Imitation Learning, which consists of two improvements geared towards fake news mitigation: learning from negative samples, and an augmented state representation to capture the "real" environment state by integrating the current observed state with the previous state-action pairs from the same campaign. Experiments on two social networks show that NAGASIL yields superior performance to standard GASIL and state-of-the-art fake news mitigation models.
Who Should I Engage with At What Time? A Missing Event Aware Temporal Graph Neural Network
Jan 20, 2023Temporal graph neural network has recently received significant attention due to its wide application scenarios, such as bioinformatics, knowledge graphs, and social networks. There are some temporal graph neural networks that achieve remarkable results. However, these works focus on future event prediction and are performed under the assumption that all historical events are observable. In real-world applications, events are not always observable, and estimating event time is as important as predicting future events. In this paper, we propose MTGN, a missing event-aware temporal graph neural network, which uniformly models evolving graph structure and timing of events to support predicting what will happen in the future and when it will happen.MTGN models the dynamic of both observed and missing events as two coupled temporal point processes, thereby incorporating the effects of missing events into the network. Experimental results on several real-world temporal graphs demonstrate that MTGN significantly outperforms existing methods with up to 89% and 112% more accurate time and link prediction. Code can be found on https://github.com/HIT-ICES/TNNLS-MTGN.
Requirements Elicitation in Cognitive Service for Recommendation
Mar 29, 2022

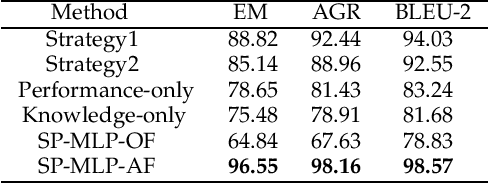
Nowadays, cognitive service provides more interactive way to understand users' requirements via human-machine conversation. In other words, it has to capture users' requirements from their utterance and respond them with the relevant and suitable service resources. To this end, two phases must be applied: I.Sequence planning and Real-time detection of user requirement, II.Service resource selection and Response generation. The existing works ignore the potential connection between these two phases. To model their connection, Two-Phase Requirement Elicitation Method is proposed. For the phase I, this paper proposes a user requirement elicitation framework (URef) to plan a potential requirement sequence grounded on user profile and personal knowledge base before the conversation. In addition, it can also predict user's true requirement and judge whether the requirement is completed based on the user's utterance during the conversation. For the phase II, this paper proposes a response generation model based on attention, SaRSNet. It can select the appropriate resource (i.e. knowledge triple) in line with the requirement predicted by URef, and then generates a suitable response for recommendation. The experimental results on the open dataset \emph{DuRecDial} have been significantly improved compared to the baseline, which proves the effectiveness of the proposed methods.
DySR: A Dynamic Representation Learning and Aligning based Model for Service Bundle Recommendation
Aug 07, 2021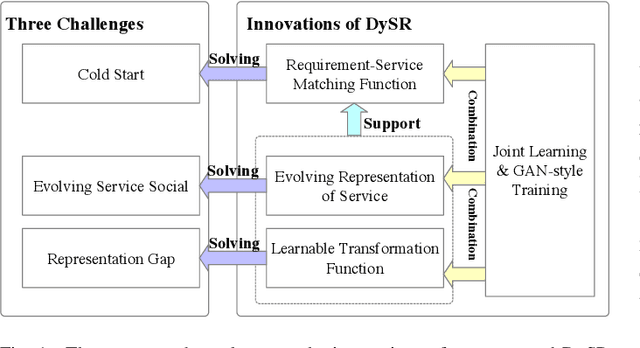
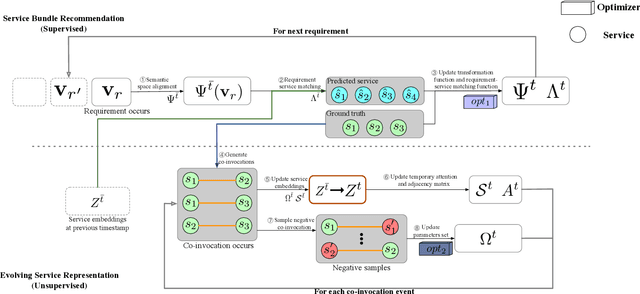
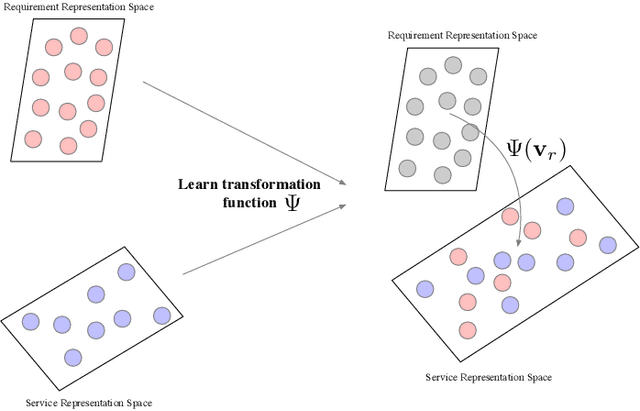
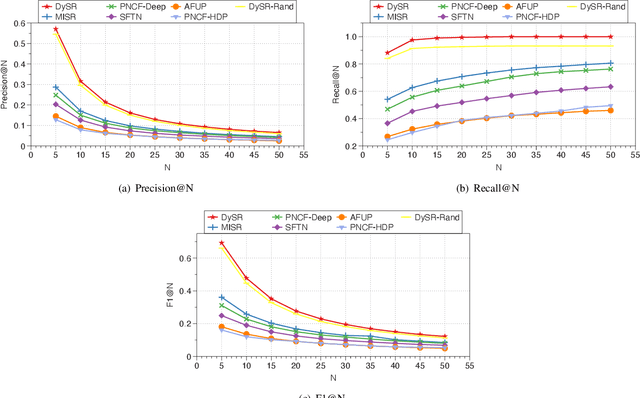
An increasing number and diversity of services are available, which result in significant challenges to effective reuse service during requirement satisfaction. There have been many service bundle recommendation studies and achieved remarkable results. However, there is still plenty of room for improvement in the performance of these methods. The fundamental problem with these studies is that they ignore the evolution of services over time and the representation gap between services and requirements. In this paper, we propose a dynamic representation learning and aligning based model called DySR to tackle these issues. DySR eliminates the representation gap between services and requirements by learning a transformation function and obtains service representations in an evolving social environment through dynamic graph representation learning. Extensive experiments conducted on a real-world dataset from ProgrammableWeb show that DySR outperforms existing state-of-the-art methods in commonly used evaluation metrics, improving $F1@5$ from $36.1\%$ to $69.3\%$.
Learning Representation over Dynamic Graph using Aggregation-Diffusion Mechanism
Jun 03, 2021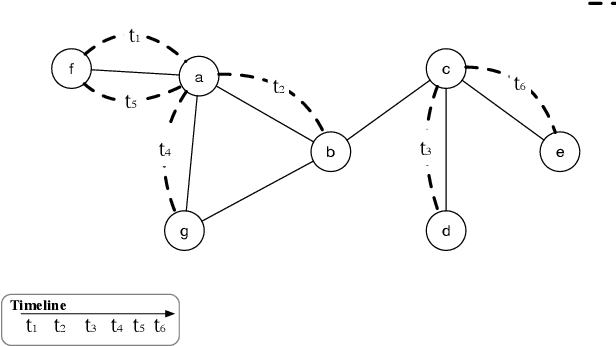
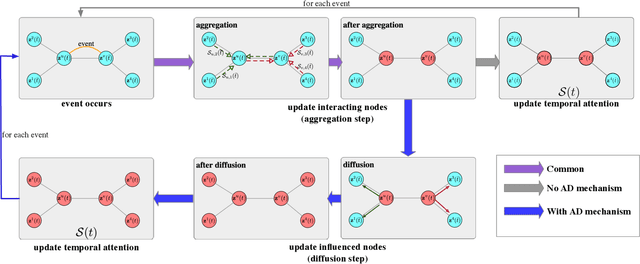
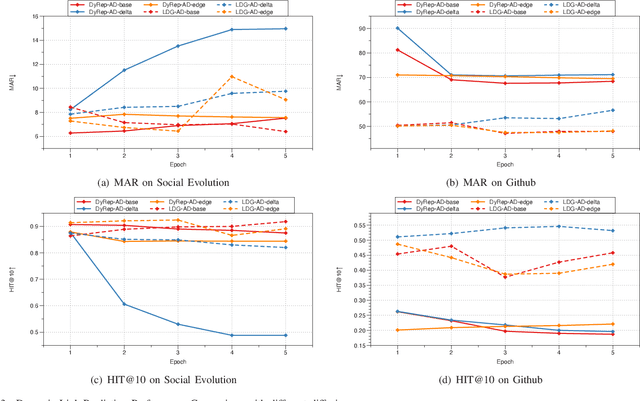
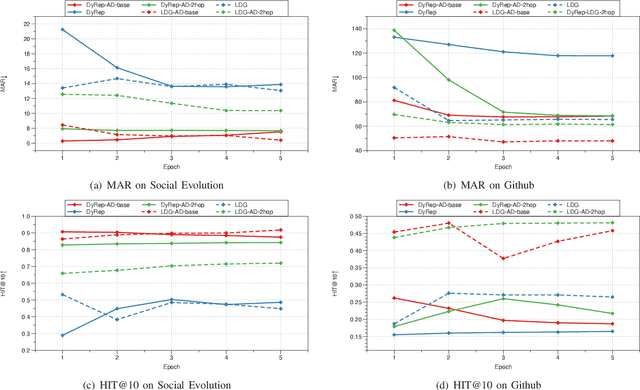
Representation learning on graphs that evolve has recently received significant attention due to its wide application scenarios, such as bioinformatics, knowledge graphs, and social networks. The propagation of information in graphs is important in learning dynamic graph representations, and most of the existing methods achieve this by aggregation. However, relying only on aggregation to propagate information in dynamic graphs can result in delays in information propagation and thus affect the performance of the method. To alleviate this problem, we propose an aggregation-diffusion (AD) mechanism that actively propagates information to its neighbor by diffusion after the node updates its embedding through the aggregation mechanism. In experiments on two real-world datasets in the dynamic link prediction task, the AD mechanism outperforms the baseline models that only use aggregation to propagate information. We further conduct extensive experiments to discuss the influence of different factors in the AD mechanism.
User Intention Recognition and Requirement Elicitation Method for Conversational AI Services
Sep 03, 2020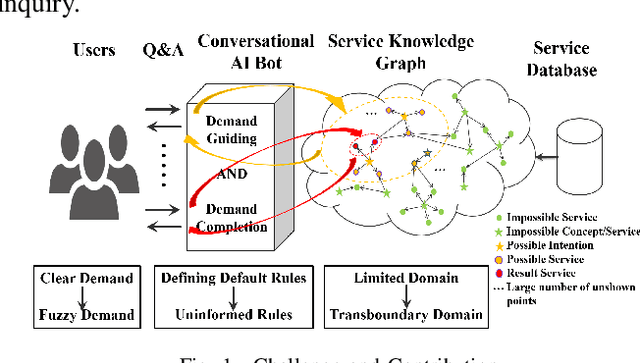
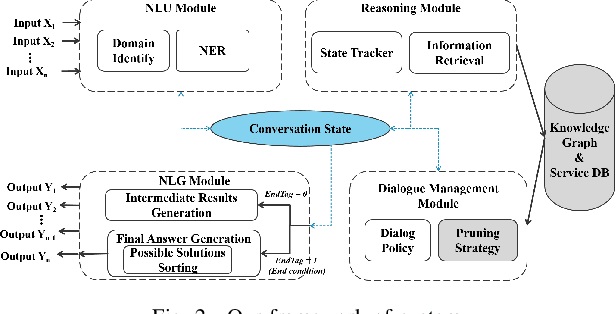
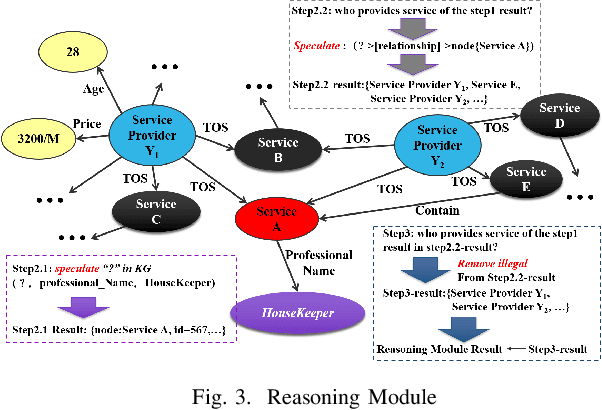
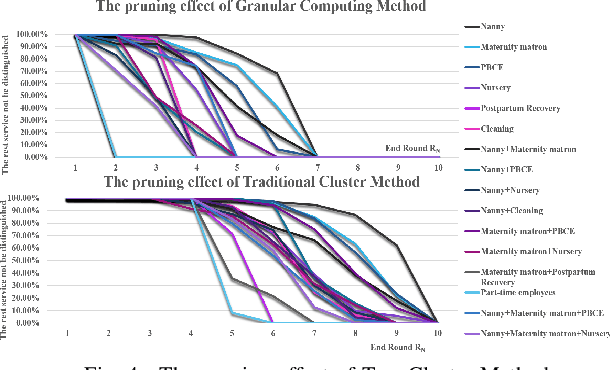
In recent years, chat-bot has become a new type of intelligent terminal to guide users to consume services. However, it is criticized most that the services it provides are not what users expect or most expect. This defect mostly dues to two problems, one is that the incompleteness and uncertainty of user's requirement expression caused by the information asymmetry, the other is that the diversity of service resources leads to the difficulty of service selection. Conversational bot is a typical mesh device, so the guided multi-rounds Q$\&$A is the most effective way to elicit user requirements. Obviously, complex Q$\&$A with too many rounds is boring and always leads to bad user experience. Therefore, we aim to obtain user requirements as accurately as possible in as few rounds as possible. To achieve this, a user intention recognition method based on Knowledge Graph (KG) was developed for fuzzy requirement inference, and a requirement elicitation method based on Granular Computing was proposed for dialog policy generation. Experimental results show that these two methods can effectively reduce the number of conversation rounds, and can quickly and accurately identify the user intention.