 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLGIB: Multi-Label Graph Information Bottleneck for Expressive and Robust Message Passing
May 14, 2026Graph Neural Networks (GNNs) suffer from over-squashing in deep message passing, where information from exponentially growing neighborhoods is compressed into fixed-dimensional representations. We show that this issue becomes a distinct failure mode in multi-label graphs: neighboring nodes often share only limited labels while differing across many irrelevant ones, causing predictive signals to be diluted by noisy label information. To address this challenge, we propose the Multi-Label Graph Information Bottleneck (MLGIB), which formulates multi-label message passing as constrained information transmission under irrelevant label noise. MLGIB balances expressiveness and robustness by preserving predictive label signals while suppressing irrelevant noise. Specifically, it constructs a Markovian dependence space and derives tractable variational bounds, where the lower bound maximizes mutual information with target labels and the upper bound constrains redundant source information. These bounds lead to an end-to-end label-aware message-passing architecture. Extensive experiments on multiple benchmarks demonstrate consistent improvements over existing methods, validating the effectiveness and generality of the proposed framework.
GRACE: Gradient-aligned Reasoning Data Curation for Efficient Post-training
May 13, 2026Existing reasoning data curation pipelines score whole samples, treating every intermediate step as equally valuable. In reality, steps within a trace contribute very unevenly, and selecting reasoning data well requires assessing them individually. We present GRACE, a gradient-aligned curation method that views each reasoning trace as a sequence of optimization events and scores every step by two complementary signals: its alignment with the answer-oriented gradient direction, and its consistency with the preceding reasoning trajectory. Step-level scores are aggregated into a sample-level value for subset selection, using only the model's internal optimization signals and no external reward models or step annotations. To make this scalable, GRACE introduces a representation-level gradient proxy that estimates step-level alignment from token-level upstream signals in a single forward pass. Post-training Qwen3-VL-2B-Instruct on MMathCoT-1M, GRACE reaches 108.8% of the full-data performance with 20% of the data and retains 100.2% with only 5%, with subsets that transfer effectively across model backbones.
Category-based and Popularity-guided Video Game Recommendation: A Balance-oriented Framework
Apr 16, 2026In recent years, the video game industry has experienced substantial growth, presenting players with a vast array of game choices. This surge in options has spurred the need for a specialized recommender system tailored for video games. However, current video game recommendation approaches tend to prioritize accuracy over diversity, potentially leading to unvaried game suggestions. In addition, the existing game recommendation methods commonly lack the ability to establish strict connections between games to enhance accuracy. Furthermore, many existing diversity-focused methods fail to leverage crucial item information, such as item category and popularity during neighbor modeling and message propagation. To address these challenges, we introduce a novel framework, called CPGRec, comprising three modules, namely accuracy-driven, diversity-driven, and comprehensive modules. The first module extends the state-of-the-art accuracy-focused game recommendation method by connecting games in a more stringent manner to enhance recommendation accuracy. The second module connects neighbors with diverse categories within the proposed game graph and harnesses the advantages of popular game nodes to amplify the influence of long-tail games within the player-game bipartite graph, thereby enriching recommendation diversity. The third module combines the above two modules and employs a new negative-sample rating score reweighting method to balance accuracy and diversity. Experimental results on the Steam dataset demonstrate the effectiveness of our proposed method in improving game recommendations. The dataset and source codes are anonymously released at: https://github.com/CPGRec2024/CPGRec.git.
CPGRec+: A Balance-oriented Framework for Personalized Video Game Recommendations
Apr 16, 2026The rapid expansion of gaming industry requires advanced recommender systems tailored to its dynamic landscape. Existing Graph Neural Network (GNN)-based methods primarily prioritize accuracy over diversity, overlooking their inherent trade-off. To address this, we previously proposed CPGRec, a balance-oriented gaming recommender system. However, CPGRec fails to account for critical disparities in player-game interactions, which carry varying significance in reflecting players' personal preferences and may exacerbate over-smoothness issues inherent in GNN-based models. Moreover, existing approaches underutilize the reasoning capabilities and extensive knowledge of large language models (LLMs) in addressing these limitations. To bridge this gap, we propose two new modules. First, Preference-informed Edge Reweighting (PER) module assigns signed edge weights to qualitatively distinguish significant player interests and disinterests while then quantitatively measuring preference strength to mitigate over-smoothing in graph convolutions. Second, Preference-informed Representation Generation (PRG) module leverages LLMs to generate contextualized descriptions of games and players by reasoning personal preferences from comparing global and personal interests, thereby refining representations of players and games. Experiments on \textcolor{black}{two Steam datasets} demonstrate CPGRec+'s superior accuracy and diversity over state-of-the-art models. The code is accessible at https://github.com/HsipingLi/CPGRec-Plus.
* Published in ACM Transactions on Information Systems (TOIS). 43 pages, 9 figures
Diversity Recommendation via Causal Deconfounding of Co-purchase Relations and Counterfactual Exposure
Dec 19, 2025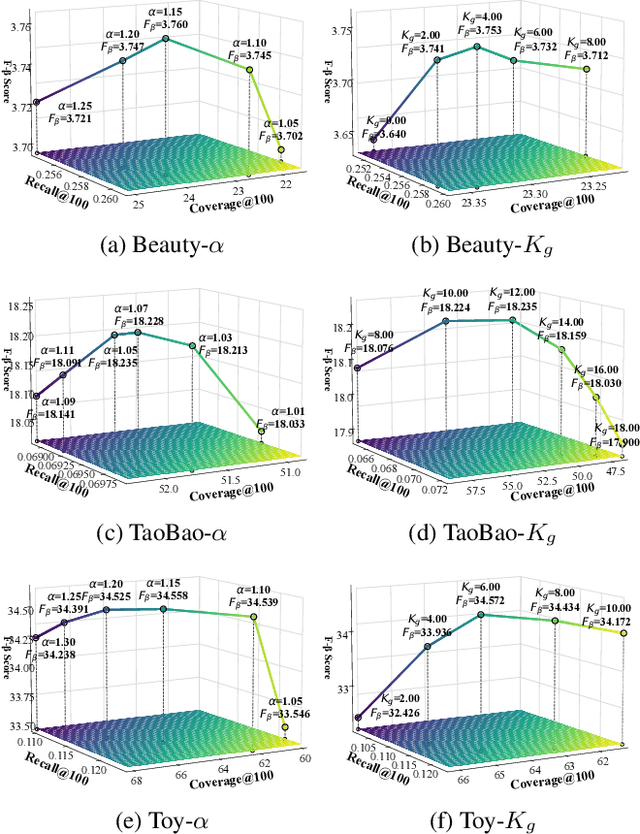

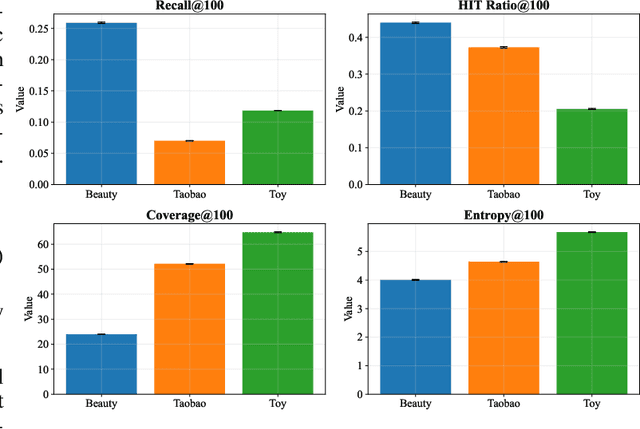
Beyond user-item modeling, item-to-item relationships are increasingly used to enhance recommendation. However, common methods largely rely on co-occurrence, making them prone to item popularity bias and user attributes, which degrades embedding quality and performance. Meanwhile, although diversity is acknowledged as a key aspect of recommendation quality, existing research offers limited attention to it, with a notable lack of causal perspectives and theoretical grounding. To address these challenges, we propose Cadence: Diversity Recommendation via Causal Deconfounding of Co-purchase Relations and Counterfactual Exposure - a plug-and-play framework built upon LightGCN as the backbone, primarily designed to enhance recommendation diversity while preserving accuracy. First, we compute the Unbiased Asymmetric Co-purchase Relationship (UACR) between items - excluding item popularity and user attributes - to construct a deconfounded directed item graph, with an aggregation mechanism to refine embeddings. Second, we leverage UACR to identify diverse categories of items that exhibit strong causal relevance to a user's interacted items but have not yet been engaged with. We then simulate their behavior under high-exposure scenarios, thereby significantly enhancing recommendation diversity while preserving relevance. Extensive experiments on real-world datasets demonstrate that our method consistently outperforms state-of-the-art diversity models in both diversity and accuracy, and further validates its effectiveness, transferability, and efficiency over baselines.
RocketEval: Efficient Automated LLM Evaluation via Grading Checklist
Mar 07, 2025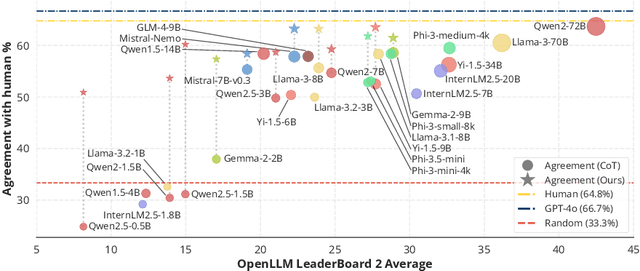
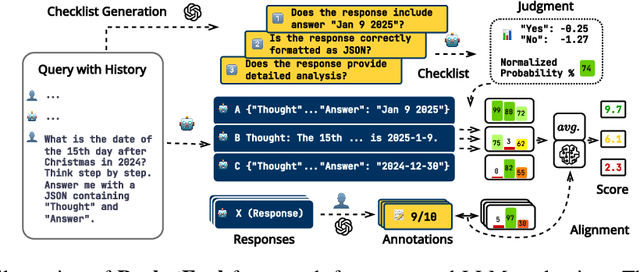
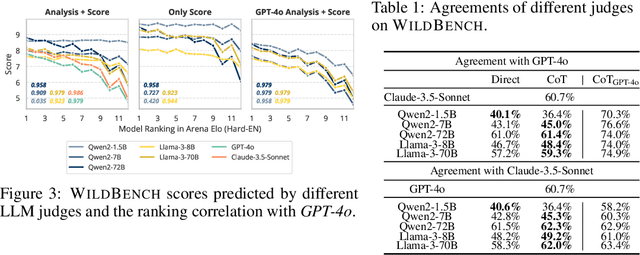
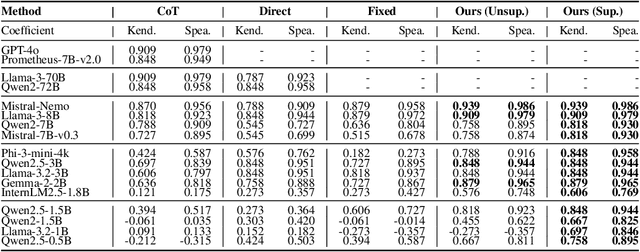
Evaluating large language models (LLMs) in diverse and challenging scenarios is essential to align them with human preferences. To mitigate the prohibitive costs associated with human evaluations, utilizing a powerful LLM as a judge has emerged as a favored approach. Nevertheless, this methodology encounters several challenges, including substantial expenses, concerns regarding privacy and security, and reproducibility. In this paper, we propose a straightforward, replicable, and accurate automated evaluation method by leveraging a lightweight LLM as the judge, named RocketEval. Initially, we identify that the performance disparity between lightweight and powerful LLMs in evaluation tasks primarily stems from their ability to conduct comprehensive analyses, which is not easily enhanced through techniques such as chain-of-thought reasoning. By reframing the evaluation task as a multi-faceted Q&A using an instance-specific checklist, we demonstrate that the limited judgment accuracy of lightweight LLMs is largely attributes to high uncertainty and positional bias. To address these challenges, we introduce an automated evaluation process grounded in checklist grading, which is designed to accommodate a variety of scenarios and questions. This process encompasses the creation of checklists, the grading of these checklists by lightweight LLMs, and the reweighting of checklist items to align with the supervised annotations. Our experiments carried out on the automated evaluation benchmarks, MT-Bench and WildBench datasets, reveal that RocketEval, when using Gemma-2-2B as the judge, achieves a high correlation (0.965) with human preferences, which is comparable to GPT-4o. Moreover, RocketEval provides a cost reduction exceeding 50-fold for large-scale evaluation and comparison scenarios. Our code is available at https://github.com/Joinn99/RocketEval-ICLR .
COutfitGAN: Learning to Synthesize Compatible Outfits Supervised by Silhouette Masks and Fashion Styles
Feb 12, 2025



How to recommend outfits has gained considerable attention in both academia and industry in recent years. Many studies have been carried out regarding fashion compatibility learning, to determine whether the fashion items in an outfit are compatible or not. These methods mainly focus on evaluating the compatibility of existing outfits and rarely consider applying such knowledge to 'design' new fashion items. We propose the new task of generating complementary and compatible fashion items based on an arbitrary number of given fashion items. In particular, given some fashion items that can make up an outfit, the aim of this paper is to synthesize photo-realistic images of other, complementary, fashion items that are compatible with the given ones. To achieve this, we propose an outfit generation framework, referred to as COutfitGAN, which includes a pyramid style extractor, an outfit generator, a UNet-based real/fake discriminator, and a collocation discriminator. To train and evaluate this framework, we collected a large-scale fashion outfit dataset with over 200K outfits and 800K fashion items from the Internet. Extensive experiments show that COutfitGAN outperforms other baselines in terms of similarity, authenticity, and compatibility measurements.
FCBoost-Net: A Generative Network for Synthesizing Multiple Collocated Outfits via Fashion Compatibility Boosting
Feb 03, 2025



Outfit generation is a challenging task in the field of fashion technology, in which the aim is to create a collocated set of fashion items that complement a given set of items. Previous studies in this area have been limited to generating a unique set of fashion items based on a given set of items, without providing additional options to users. This lack of a diverse range of choices necessitates the development of a more versatile framework. However, when the task of generating collocated and diversified outfits is approached with multimodal image-to-image translation methods, it poses a challenging problem in terms of non-aligned image translation, which is hard to address with existing methods. In this research, we present FCBoost-Net, a new framework for outfit generation that leverages the power of pre-trained generative models to produce multiple collocated and diversified outfits. Initially, FCBoost-Net randomly synthesizes multiple sets of fashion items, and the compatibility of the synthesized sets is then improved in several rounds using a novel fashion compatibility booster. This approach was inspired by boosting algorithms and allows the performance to be gradually improved in multiple steps. Empirical evidence indicates that the proposed strategy can improve the fashion compatibility of randomly synthesized fashion items as well as maintain their diversity. Extensive experiments confirm the effectiveness of our proposed framework with respect to visual authenticity, diversity, and fashion compatibility.
BC-GAN: A Generative Adversarial Network for Synthesizing a Batch of Collocated Clothing
Feb 03, 2025



Collocated clothing synthesis using generative networks has become an emerging topic in the field of fashion intelligence, as it has significant potential economic value to increase revenue in the fashion industry. In previous studies, several works have attempted to synthesize visually-collocated clothing based on a given clothing item using generative adversarial networks (GANs) with promising results. These works, however, can only accomplish the synthesis of one collocated clothing item each time. Nevertheless, users may require different clothing items to meet their multiple choices due to their personal tastes and different dressing scenarios. To address this limitation, we introduce a novel batch clothing generation framework, named BC-GAN, which is able to synthesize multiple visually-collocated clothing images simultaneously. In particular, to further improve the fashion compatibility of synthetic results, BC-GAN proposes a new fashion compatibility discriminator in a contrastive learning perspective by fully exploiting the collocation relationship among all clothing items. Our model was examined in a large-scale dataset with compatible outfits constructed by ourselves. Extensive experiment results confirmed the effectiveness of our proposed BC-GAN in comparison to state-of-the-art methods in terms of diversity, visual authenticity, and fashion compatibility.
GiVE: Guiding Visual Encoder to Perceive Overlooked Information
Oct 26, 2024Multimodal Large Language Models have advanced AI in applications like text-to-video generation and visual question answering. These models rely on visual encoders to convert non-text data into vectors, but current encoders either lack semantic alignment or overlook non-salient objects. We propose the Guiding Visual Encoder to Perceive Overlooked Information (GiVE) approach. GiVE enhances visual representation with an Attention-Guided Adapter (AG-Adapter) module and an Object-focused Visual Semantic Learning module. These incorporate three novel loss terms: Object-focused Image-Text Contrast (OITC) loss, Object-focused Image-Image Contrast (OIIC) loss, and Object-focused Image Discrimination (OID) loss, improving object consideration, retrieval accuracy, and comprehensiveness. Our contributions include dynamic visual focus adjustment, novel loss functions to enhance object retrieval, and the Multi-Object Instruction (MOInst) dataset. Experiments show our approach achieves state-of-the-art performance.