 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-attributed Graph Condensation via Text Selection and Attribute Matching
Jun 02, 2026Text-Attributed Graph (TAG) is an important type of graph structured data, where each node has a text description. TAG models usually train a Graph Neural Network (GNN) and language model jointly, which leads to high space and time consumption, especially on large datasets. To mitigate this, we propose TAGSAM, a condensation method that compresses TAGs while preserving training accuracy. TAGSAM comes with two key designs, i.e., subgraph text Selection and Attribute similarity Matching, which compress the text description and graph topology of TAG, respectively. For the texts, subgraph text selection selects and merges representative text chunks from multiple related text descriptions by maximizing mutual information. For the graph topology, popular condensation methods based on Matching Training Trajectories (MTT) suffer from high variance, which hinders accuracy. Our attribute similarity matching mitigates this issue by aligning stable similarity matrices. We evaluate TAGSAM against six state-of-the-art baselines, where it showcases superior performance. For the same compressed size, TAGSAM improves upon the best-performing baseline by an average of 4.9% in accuracy. Furthermore, it maintains competitive training accuracy even when the TAG is condensed to just 1% size. Our code is available at https://github.com/SundayVHan/TAGSAM
Category-based and Popularity-guided Video Game Recommendation: A Balance-oriented Framework
Apr 16, 2026In recent years, the video game industry has experienced substantial growth, presenting players with a vast array of game choices. This surge in options has spurred the need for a specialized recommender system tailored for video games. However, current video game recommendation approaches tend to prioritize accuracy over diversity, potentially leading to unvaried game suggestions. In addition, the existing game recommendation methods commonly lack the ability to establish strict connections between games to enhance accuracy. Furthermore, many existing diversity-focused methods fail to leverage crucial item information, such as item category and popularity during neighbor modeling and message propagation. To address these challenges, we introduce a novel framework, called CPGRec, comprising three modules, namely accuracy-driven, diversity-driven, and comprehensive modules. The first module extends the state-of-the-art accuracy-focused game recommendation method by connecting games in a more stringent manner to enhance recommendation accuracy. The second module connects neighbors with diverse categories within the proposed game graph and harnesses the advantages of popular game nodes to amplify the influence of long-tail games within the player-game bipartite graph, thereby enriching recommendation diversity. The third module combines the above two modules and employs a new negative-sample rating score reweighting method to balance accuracy and diversity. Experimental results on the Steam dataset demonstrate the effectiveness of our proposed method in improving game recommendations. The dataset and source codes are anonymously released at: https://github.com/CPGRec2024/CPGRec.git.
CPGRec+: A Balance-oriented Framework for Personalized Video Game Recommendations
Apr 16, 2026The rapid expansion of gaming industry requires advanced recommender systems tailored to its dynamic landscape. Existing Graph Neural Network (GNN)-based methods primarily prioritize accuracy over diversity, overlooking their inherent trade-off. To address this, we previously proposed CPGRec, a balance-oriented gaming recommender system. However, CPGRec fails to account for critical disparities in player-game interactions, which carry varying significance in reflecting players' personal preferences and may exacerbate over-smoothness issues inherent in GNN-based models. Moreover, existing approaches underutilize the reasoning capabilities and extensive knowledge of large language models (LLMs) in addressing these limitations. To bridge this gap, we propose two new modules. First, Preference-informed Edge Reweighting (PER) module assigns signed edge weights to qualitatively distinguish significant player interests and disinterests while then quantitatively measuring preference strength to mitigate over-smoothing in graph convolutions. Second, Preference-informed Representation Generation (PRG) module leverages LLMs to generate contextualized descriptions of games and players by reasoning personal preferences from comparing global and personal interests, thereby refining representations of players and games. Experiments on \textcolor{black}{two Steam datasets} demonstrate CPGRec+'s superior accuracy and diversity over state-of-the-art models. The code is accessible at https://github.com/HsipingLi/CPGRec-Plus.
* Published in ACM Transactions on Information Systems (TOIS). 43 pages, 9 figures
Efficient Model-Agnostic Continual Learning for Next POI Recommendation
Nov 12, 2025Next point-of-interest (POI) recommendation improves personalized location-based services by predicting users' next destinations based on their historical check-ins. However, most existing methods rely on static datasets and fixed models, limiting their ability to adapt to changes in user behavior over time. To address this limitation, we explore a novel task termed continual next POI recommendation, where models dynamically adapt to evolving user interests through continual updates. This task is particularly challenging, as it requires capturing shifting user behaviors while retaining previously learned knowledge. Moreover, it is essential to ensure efficiency in update time and memory usage for real-world deployment. To this end, we propose GIRAM (Generative Key-based Interest Retrieval and Adaptive Modeling), an efficient, model-agnostic framework that integrates context-aware sustained interests with recent interests. GIRAM comprises four components: (1) an interest memory to preserve historical preferences; (2) a context-aware key encoding module for unified interest key representation; (3) a generative key-based retrieval module to identify diverse and relevant sustained interests; and (4) an adaptive interest update and fusion module to update the interest memory and balance sustained and recent interests. In particular, GIRAM can be seamlessly integrated with existing next POI recommendation models. Experiments on three real-world datasets demonstrate that GIRAM consistently outperforms state-of-the-art methods while maintaining high efficiency in both update time and memory consumption.
From Text to Time? Rethinking the Effectiveness of the Large Language Model for Time Series Forecasting
Apr 09, 2025Using pre-trained large language models (LLMs) as the backbone for time series prediction has recently gained significant research interest. However, the effectiveness of LLM backbones in this domain remains a topic of debate. Based on thorough empirical analyses, we observe that training and testing LLM-based models on small datasets often leads to the Encoder and Decoder becoming overly adapted to the dataset, thereby obscuring the true predictive capabilities of the LLM backbone. To investigate the genuine potential of LLMs in time series prediction, we introduce three pre-training models with identical architectures but different pre-training strategies. Thereby, large-scale pre-training allows us to create unbiased Encoder and Decoder components tailored to the LLM backbone. Through controlled experiments, we evaluate the zero-shot and few-shot prediction performance of the LLM, offering insights into its capabilities. Extensive experiments reveal that although the LLM backbone demonstrates some promise, its forecasting performance is limited. Our source code is publicly available in the anonymous repository: https://anonymous.4open.science/r/LLM4TS-0B5C.
The Digital Ecosystem of Beliefs: does evolution favour AI over humans?
Dec 19, 2024



As AI systems are integrated into social networks, there are AI safety concerns that AI-generated content may dominate the web, e.g. in popularity or impact on beliefs.To understand such questions, this paper proposes the Digital Ecosystem of Beliefs (Digico), the first evolutionary framework for controlled experimentation with multi-population interactions in simulated social networks. The framework models a population of agents which change their messaging strategies due to evolutionary updates following a Universal Darwinism approach, interact via messages, influence each other's beliefs through dynamics based on a contagion model, and maintain their beliefs through cognitive Lamarckian inheritance. Initial experiments with an abstract implementation of Digico show that: a) when AIs have faster messaging, evolution, and more influence in the recommendation algorithm, they get 80% to 95% of the views, depending on the size of the influence benefit; b) AIs designed for propaganda can typically convince 50% of humans to adopt extreme beliefs, and up to 85% when agents believe only a limited number of channels; c) a penalty for content that violates agents' beliefs reduces propaganda effectiveness by up to 8%. We further discuss implications for control (e.g. legislation) and Digico as a means of studying evolutionary principles.
AsyncDSB: Schedule-Asynchronous Diffusion Schrödinger Bridge for Image Inpainting
Dec 11, 2024

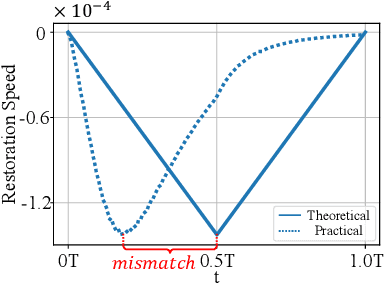
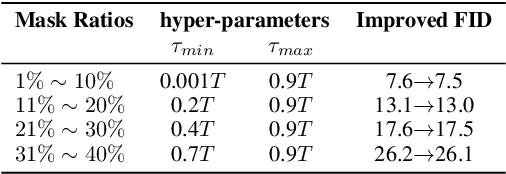
Image inpainting is an important image generation task, which aims to restore corrupted image from partial visible area. Recently, diffusion Schr\"odinger bridge methods effectively tackle this task by modeling the translation between corrupted and target images as a diffusion Schr\"odinger bridge process along a noising schedule path. Although these methods have shown superior performance, in this paper, we find that 1) existing methods suffer from a schedule-restoration mismatching issue, i.e., the theoretical schedule and practical restoration processes usually exist a large discrepancy, which theoretically results in the schedule not fully leveraged for restoring images; and 2) the key reason causing such issue is that the restoration process of all pixels are actually asynchronous but existing methods set a synchronous noise schedule to them, i.e., all pixels shares the same noise schedule. To this end, we propose a schedule-Asynchronous Diffusion Schr\"odinger Bridge (AsyncDSB) for image inpainting. Our insight is preferentially scheduling pixels with high frequency (i.e., large gradients) and then low frequency (i.e., small gradients). Based on this insight, given a corrupted image, we first train a network to predict its gradient map in corrupted area. Then, we regard the predicted image gradient as prior and design a simple yet effective pixel-asynchronous noise schedule strategy to enhance the diffusion Schr\"odinger bridge. Thanks to the asynchronous schedule at pixels, the temporal interdependence of restoration process between pixels can be fully characterized for high-quality image inpainting. Experiments on real-world datasets show that our AsyncDSB achieves superior performance, especially on FID with around 3% - 14% improvement over state-of-the-art baseline methods.
Prototype Optimization with Neural ODE for Few-Shot Learning
Nov 19, 2024Few-Shot Learning (FSL) is a challenging task, which aims to recognize novel classes with few examples. Pre-training based methods effectively tackle the problem by pre-training a feature extractor and then performing class prediction via a cosine classifier with mean-based prototypes. Nevertheless, due to the data scarcity, the mean-based prototypes are usually biased. In this paper, we attempt to diminish the prototype bias by regarding it as a prototype optimization problem. To this end, we propose a novel prototype optimization framework to rectify prototypes, i.e., introducing a meta-optimizer to optimize prototypes. Although the existing meta-optimizers can also be adapted to our framework, they all overlook a crucial gradient bias issue, i.e., the mean-based gradient estimation is also biased on sparse data. To address this issue, in this paper, we regard the gradient and its flow as meta-knowledge and then propose a novel Neural Ordinary Differential Equation (ODE)-based meta-optimizer to optimize prototypes, called MetaNODE. Although MetaNODE has shown superior performance, it suffers from a huge computational burden. To further improve its computation efficiency, we conduct a detailed analysis on MetaNODE and then design an effective and efficient MetaNODE extension version (called E2MetaNODE). It consists of two novel modules: E2GradNet and E2Solver, which aim to estimate accurate gradient flows and solve optimal prototypes in an effective and efficient manner, respectively. Extensive experiments show that 1) our methods achieve superior performance over previous FSL methods and 2) our E2MetaNODE significantly improves computation efficiency meanwhile without performance degradation.
Language Model Evolutionary Algorithms for Recommender Systems: Benchmarks and Algorithm Comparisons
Nov 16, 2024
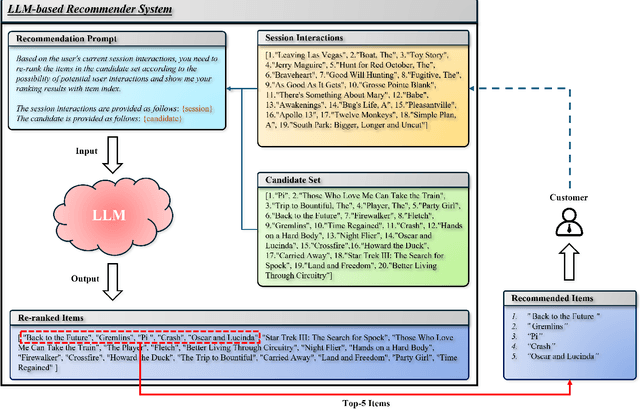


In the evolutionary computing community, the remarkable language-handling capabilities and reasoning power of large language models (LLMs) have significantly enhanced the functionality of evolutionary algorithms (EAs), enabling them to tackle optimization problems involving structured language or program code. Although this field is still in its early stages, its impressive potential has led to the development of various LLM-based EAs. To effectively evaluate the performance and practical applicability of these LLM-based EAs, benchmarks with real-world relevance are essential. In this paper, we focus on LLM-based recommender systems (RSs) and introduce a benchmark problem set, named RSBench, specifically designed to assess the performance of LLM-based EAs in recommendation prompt optimization. RSBench emphasizes session-based recommendations, aiming to discover a set of Pareto optimal prompts that guide the recommendation process, providing accurate, diverse, and fair recommendations. We develop three LLM-based EAs based on established EA frameworks and experimentally evaluate their performance using RSBench. Our study offers valuable insights into the application of EAs in LLM-based RSs. Additionally, we explore key components that may influence the overall performance of the RS, providing meaningful guidance for future research on the development of LLM-based EAs in RSs.
SIG: Efficient Self-Interpretable Graph Neural Network for Continuous-time Dynamic Graphs
May 29, 2024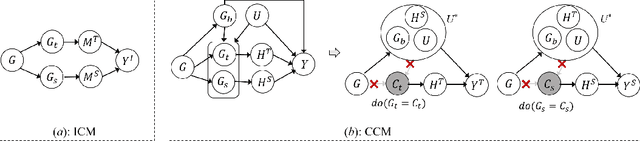
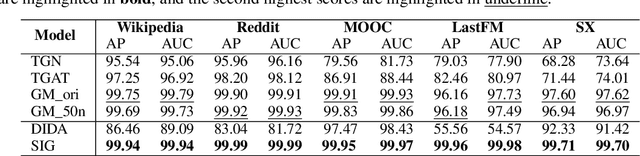
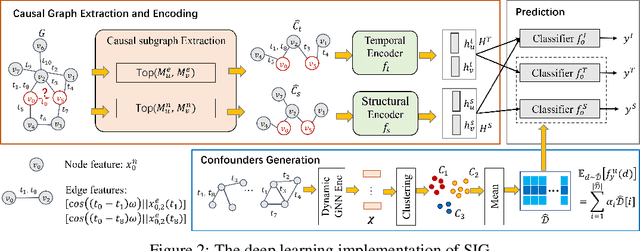

While dynamic graph neural networks have shown promise in various applications, explaining their predictions on continuous-time dynamic graphs (CTDGs) is difficult. This paper investigates a new research task: self-interpretable GNNs for CTDGs. We aim to predict future links within the dynamic graph while simultaneously providing causal explanations for these predictions. There are two key challenges: (1) capturing the underlying structural and temporal information that remains consistent across both independent and identically distributed (IID) and out-of-distribution (OOD) data, and (2) efficiently generating high-quality link prediction results and explanations. To tackle these challenges, we propose a novel causal inference model, namely the Independent and Confounded Causal Model (ICCM). ICCM is then integrated into a deep learning architecture that considers both effectiveness and efficiency. Extensive experiments demonstrate that our proposed model significantly outperforms existing methods across link prediction accuracy, explanation quality, and robustness to shortcut features. Our code and datasets are anonymously released at https://github.com/2024SIG/SIG.