 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Feature Augmentation for Predictive Tasks on Relational Datasets
Aug 28, 2025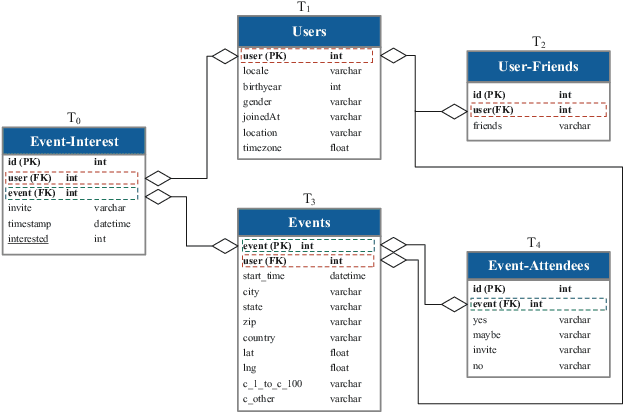
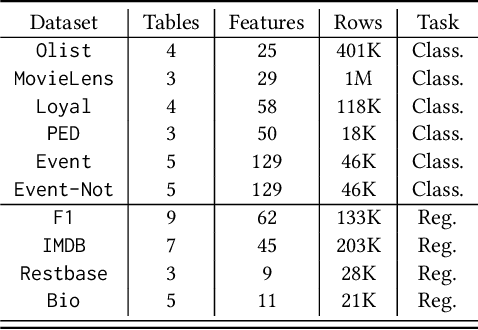
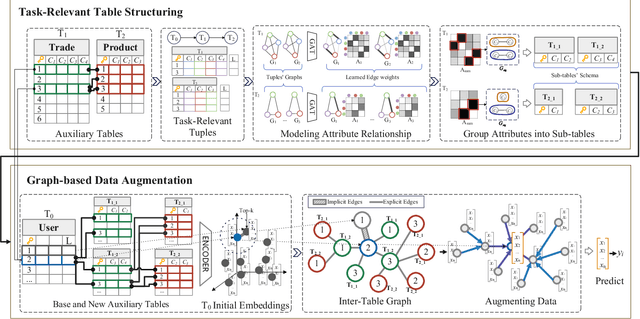
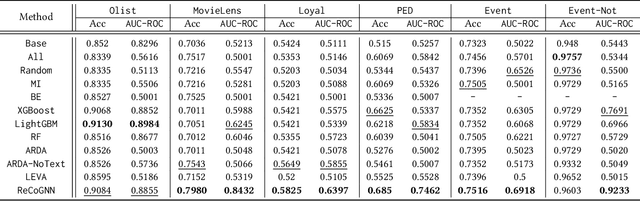
Data has become a foundational asset driving innovation across domains such as finance, healthcare, and e-commerce. In these areas, predictive modeling over relational tables is commonly employed, with increasing emphasis on reducing manual effort through automated machine learning (AutoML) techniques. This raises an interesting question: can feature augmentation itself be automated and identify and utilize task-related relational signals? To address this challenge, we propose an end-to-end automated feature augmentation framework, ReCoGNN, which enhances initial datasets using features extracted from multiple relational tables to support predictive tasks. ReCoGNN first captures semantic dependencies within each table by modeling intra-table attribute relationships, enabling it to partition tables into structured, semantically coherent segments. It then constructs a heterogeneous weighted graph that represents inter-row relationships across all segments. Finally, ReCoGNN leverages message-passing graph neural networks to propagate information through the graph, guiding feature selection and augmenting the original dataset. Extensive experiments conducted on ten real-life and synthetic datasets demonstrate that ReCoGNN consistently outperforms existing methods on both classification and regression tasks.
PORCA: Root Cause Analysis with Partially
Jul 08, 2024



Root Cause Analysis (RCA) aims at identifying the underlying causes of system faults by uncovering and analyzing the causal structure from complex systems. It has been widely used in many application domains. Reliable diagnostic conclusions are of great importance in mitigating system failures and financial losses. However, previous studies implicitly assume a full observation of the system, which neglect the effect of partial observation (i.e., missing nodes and latent malfunction). As a result, they fail in deriving reliable RCA results. In this paper, we unveil the issues of unobserved confounders and heterogeneity in partial observation and come up with a new problem of root cause analysis with partially observed data. To achieve this, we propose PORCA, a novel RCA framework which can explore reliable root causes under both unobserved confounders and unobserved heterogeneity. PORCA leverages magnified score-based causal discovery to efficiently optimize acyclic directed mixed graph under unobserved confounders. In addition, we also develop a heterogeneity-aware scheduling strategy to provide adaptive sample weights. Extensive experimental results on one synthetic and two real-world datasets demonstrate the effectiveness and superiority of the proposed framework.
SIG: Efficient Self-Interpretable Graph Neural Network for Continuous-time Dynamic Graphs
May 29, 2024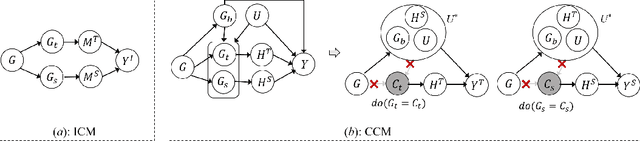
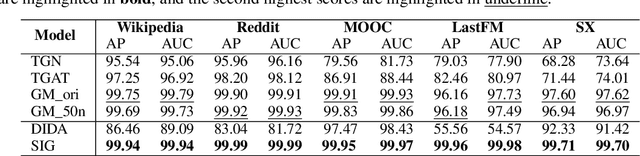
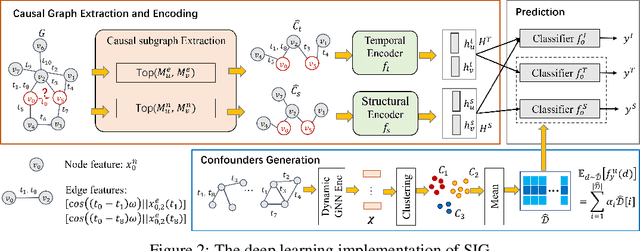

While dynamic graph neural networks have shown promise in various applications, explaining their predictions on continuous-time dynamic graphs (CTDGs) is difficult. This paper investigates a new research task: self-interpretable GNNs for CTDGs. We aim to predict future links within the dynamic graph while simultaneously providing causal explanations for these predictions. There are two key challenges: (1) capturing the underlying structural and temporal information that remains consistent across both independent and identically distributed (IID) and out-of-distribution (OOD) data, and (2) efficiently generating high-quality link prediction results and explanations. To tackle these challenges, we propose a novel causal inference model, namely the Independent and Confounded Causal Model (ICCM). ICCM is then integrated into a deep learning architecture that considers both effectiveness and efficiency. Extensive experiments demonstrate that our proposed model significantly outperforms existing methods across link prediction accuracy, explanation quality, and robustness to shortcut features. Our code and datasets are anonymously released at https://github.com/2024SIG/SIG.
AnomalyLLM: Few-shot Anomaly Edge Detection for Dynamic Graphs using Large Language Models
May 13, 2024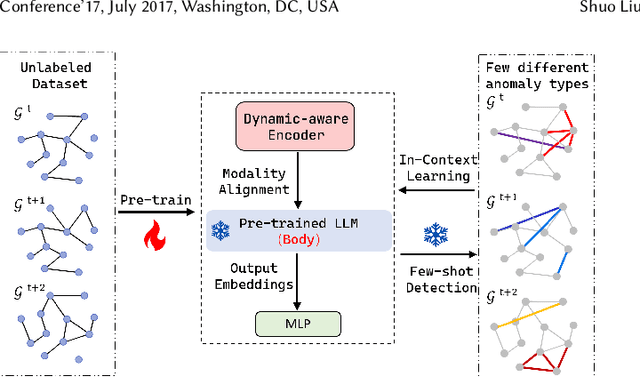
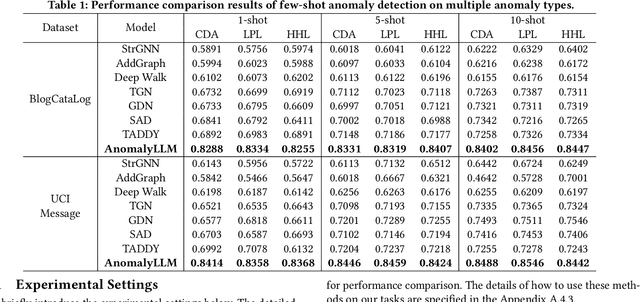
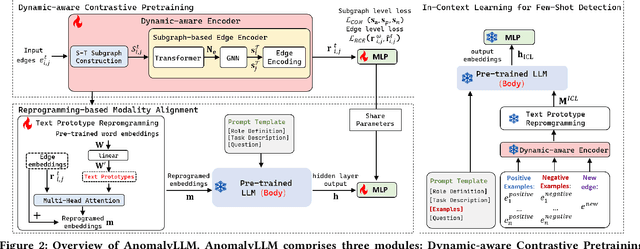

Detecting anomaly edges for dynamic graphs aims to identify edges significantly deviating from the normal pattern and can be applied in various domains, such as cybersecurity, financial transactions and AIOps. With the evolving of time, the types of anomaly edges are emerging and the labeled anomaly samples are few for each type. Current methods are either designed to detect randomly inserted edges or require sufficient labeled data for model training, which harms their applicability for real-world applications. In this paper, we study this problem by cooperating with the rich knowledge encoded in large language models(LLMs) and propose a method, namely AnomalyLLM. To align the dynamic graph with LLMs, AnomalyLLM pre-trains a dynamic-aware encoder to generate the representations of edges and reprograms the edges using the prototypes of word embeddings. Along with the encoder, we design an in-context learning framework that integrates the information of a few labeled samples to achieve few-shot anomaly detection. Experiments on four datasets reveal that AnomalyLLM can not only significantly improve the performance of few-shot anomaly detection, but also achieve superior results on new anomalies without any update of model parameters.
The RLR-Tree: A Reinforcement Learning Based R-Tree for Spatial Data
Mar 08, 2021
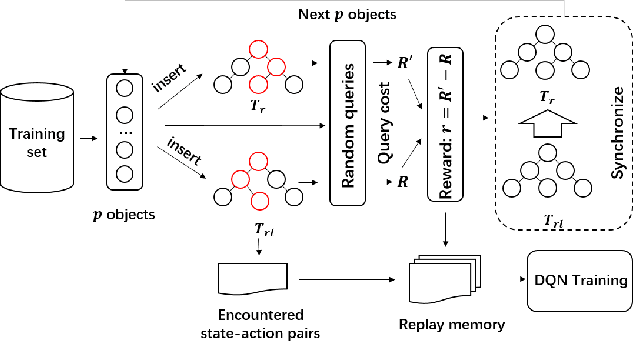

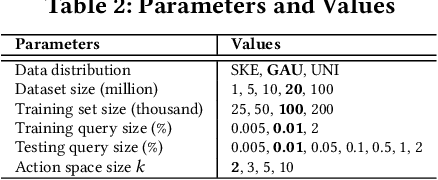
Learned indices have been proposed to replace classic index structures like B-Tree with machine learning (ML) models. They require to replace both the indices and query processing algorithms currently deployed by the databases, and such a radical departure is likely to encounter challenges and obstacles. In contrast, we propose a fundamentally different way of using ML techniques to improve on the query performance of the classic R-Tree without the need of changing its structure or query processing algorithms. Specifically, we develop reinforcement learning (RL) based models to decide how to choose a subtree for insertion and how to split a node, instead of relying on hand-crafted heuristic rules as R-Tree and its variants. Experiments on real and synthetic datasets with up to 100 million spatial objects clearly show that our RL based index outperforms R-Tree and its variants.