 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoGS: Homophily-Oriented Graph Synthesis for Local Differentially Private GNN Training
Feb 09, 2026Graph neural networks (GNNs) have demonstrated remarkable performance in various graph-based machine learning tasks by effectively modeling high-order interactions between nodes. However, training GNNs without protection may leak sensitive personal information in graph data, including links and node features. Local differential privacy (LDP) is an advanced technique for protecting data privacy in decentralized networks. Unfortunately, existing local differentially private GNNs either only preserve link privacy or suffer significant utility loss in the process of preserving link and node feature privacy. In this paper, we propose an effective LDP framework, called HoGS, which trains GNNs with link and feature protection by generating a synthetic graph. Concretely, HoGS first collects the link and feature information of the graph under LDP, and then utilizes the phenomenon of homophily in graph data to reconstruct the graph structure and node features separately, thereby effectively mitigating the negative impact of LDP on the downstream GNN training. We theoretically analyze the privacy guarantee of HoGS and conduct experiments using the generated synthetic graph as input to various state-of-the-art GNN architectures. Experimental results on three real-world datasets show that HoGS significantly outperforms baseline methods in the accuracy of training GNNs.
RoMA: Robust Malware Attribution via Byte-level Adversarial Training with Global Perturbations and Adversarial Consistency Regularization
Feb 11, 2025Attributing APT (Advanced Persistent Threat) malware to their respective groups is crucial for threat intelligence and cybersecurity. However, APT adversaries often conceal their identities, rendering attribution inherently adversarial. Existing machine learning-based attribution models, while effective, remain highly vulnerable to adversarial attacks. For example, the state-of-the-art byte-level model MalConv sees its accuracy drop from over 90% to below 2% under PGD (projected gradient descent) attacks. Existing gradient-based adversarial training techniques for malware detection or image processing were applied to malware attribution in this study, revealing that both robustness and training efficiency require significant improvement. To address this, we propose RoMA, a novel single-step adversarial training approach that integrates global perturbations to generate enhanced adversarial samples and employs adversarial consistency regularization to improve representation quality and resilience. A novel APT malware dataset named AMG18, with diverse samples and realistic class imbalances, is introduced for evaluation. Extensive experiments show that RoMA significantly outperforms seven competing methods in both adversarial robustness (e.g., achieving over 80% robust accuracy-more than twice that of the next-best method under PGD attacks) and training efficiency (e.g., more than twice as fast as the second-best method in terms of accuracy), while maintaining superior standard accuracy in non-adversarial scenarios.
AnomalyLLM: Few-shot Anomaly Edge Detection for Dynamic Graphs using Large Language Models
May 13, 2024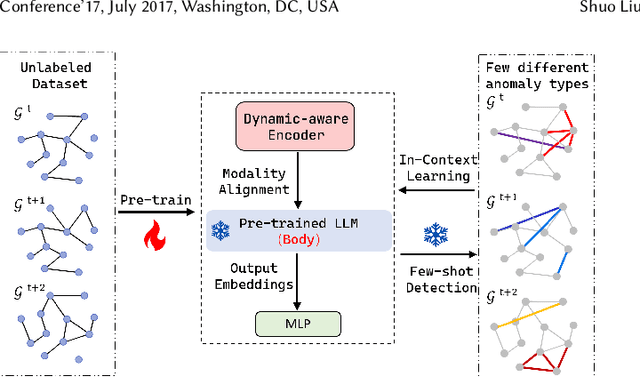
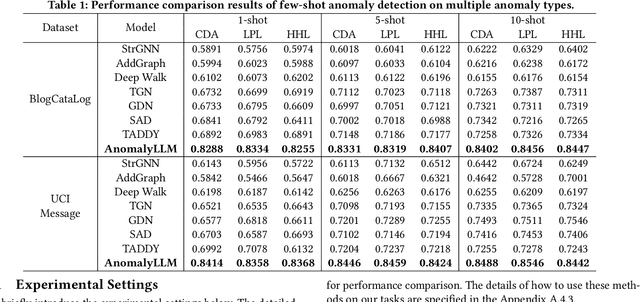
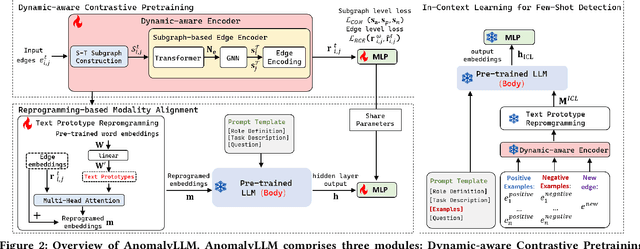

Detecting anomaly edges for dynamic graphs aims to identify edges significantly deviating from the normal pattern and can be applied in various domains, such as cybersecurity, financial transactions and AIOps. With the evolving of time, the types of anomaly edges are emerging and the labeled anomaly samples are few for each type. Current methods are either designed to detect randomly inserted edges or require sufficient labeled data for model training, which harms their applicability for real-world applications. In this paper, we study this problem by cooperating with the rich knowledge encoded in large language models(LLMs) and propose a method, namely AnomalyLLM. To align the dynamic graph with LLMs, AnomalyLLM pre-trains a dynamic-aware encoder to generate the representations of edges and reprograms the edges using the prototypes of word embeddings. Along with the encoder, we design an in-context learning framework that integrates the information of a few labeled samples to achieve few-shot anomaly detection. Experiments on four datasets reveal that AnomalyLLM can not only significantly improve the performance of few-shot anomaly detection, but also achieve superior results on new anomalies without any update of model parameters.
Denial-of-Service or Fine-Grained Control: Towards Flexible Model Poisoning Attacks on Federated Learning
Apr 21, 2023



Federated learning (FL) is vulnerable to poisoning attacks, where adversaries corrupt the global aggregation results and cause denial-of-service (DoS). Unlike recent model poisoning attacks that optimize the amplitude of malicious perturbations along certain prescribed directions to cause DoS, we propose a Flexible Model Poisoning Attack (FMPA) that can achieve versatile attack goals. We consider a practical threat scenario where no extra knowledge about the FL system (e.g., aggregation rules or updates on benign devices) is available to adversaries. FMPA exploits the global historical information to construct an estimator that predicts the next round of the global model as a benign reference. It then fine-tunes the reference model to obtain the desired poisoned model with low accuracy and small perturbations. Besides the goal of causing DoS, FMPA can be naturally extended to launch a fine-grained controllable attack, making it possible to precisely reduce the global accuracy. Armed with precise control, malicious FL service providers can gain advantages over their competitors without getting noticed, hence opening a new attack surface in FL other than DoS. Even for the purpose of DoS, experiments show that FMPA significantly decreases the global accuracy, outperforming six state-of-the-art attacks.
Cell-Free Massive MIMO-OFDM for High-Speed Train Communications
Mar 02, 2022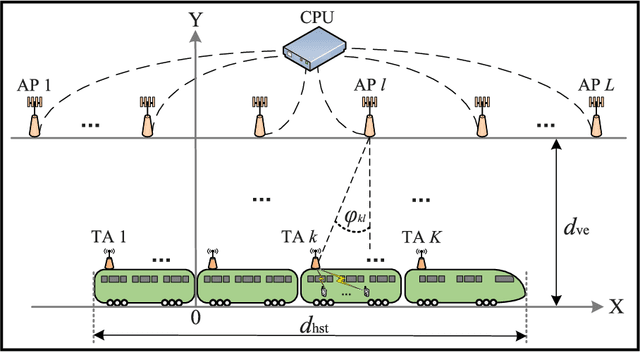
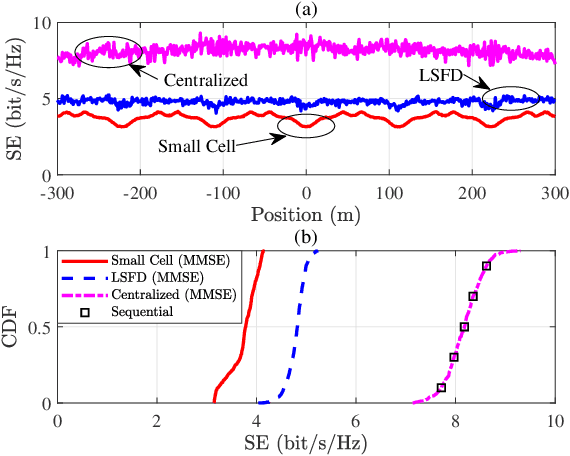
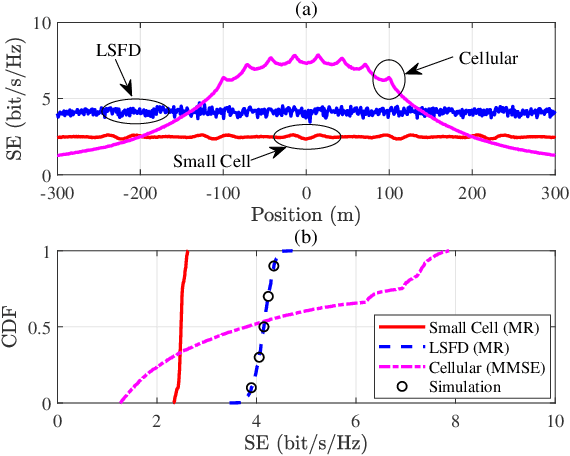
Cell-free (CF) massive multiple-input multiple-output (MIMO) systems show great potentials in low-mobility scenarios, due to cell boundary disappearance and strong macro diversity. However, the great Doppler frequency offset (DFO) leads to serious inter-carrier interference in orthogonal frequency division multiplexing (OFDM) technology, which makes it difficult to provide high-quality transmissions for both high-speed train (HST) operation control systems and passengers. In this paper, we focus on the performance of CF massive MIMO-OFDM systems with both fully centralized and local minimum mean square error (MMSE) combining in HST communications. Considering the local maximum ratio (MR) combining, the large-scale fading decoding (LSFD) cooperation and the practical effect of DFO on system performance, exact closed-form expressions for uplink spectral efficiency (SE) expressions are derived. We observe that cooperative MMSE combining achieves better SE performance than uncooperative MR combining. In addition, HST communications with small cell and cellular massive MIMO-OFDM systems are compared in terms of SE. Numerical results reveal that the CF massive MIMO-OFDM system achieves a larger and more uniform SE than the other systems. Finally, the train antenna centric (TA-centric) CF massive MIMO-OFDM system is designed for practical implementation in HST communications, and three power control schemes are adopted to optimize the propagation of TAs for reducing the impact of the DFO.
Decentralized Multi-AGV Task Allocation based on Multi-Agent Reinforcement Learning with Information Potential Field Rewards
Aug 16, 2021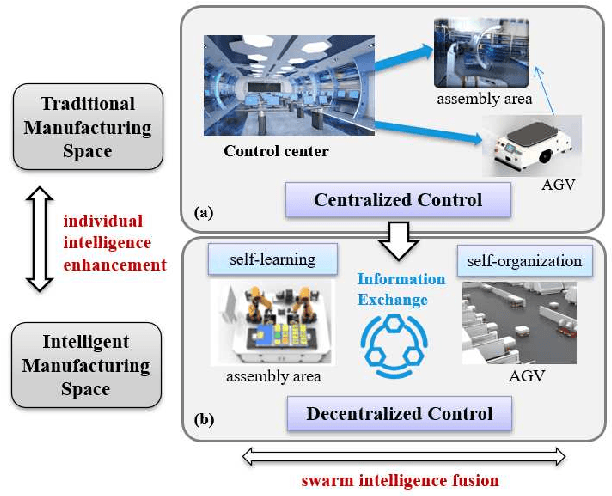
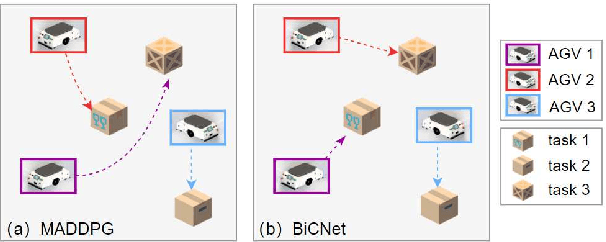
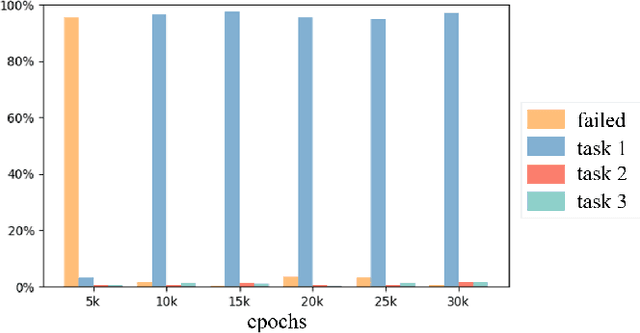
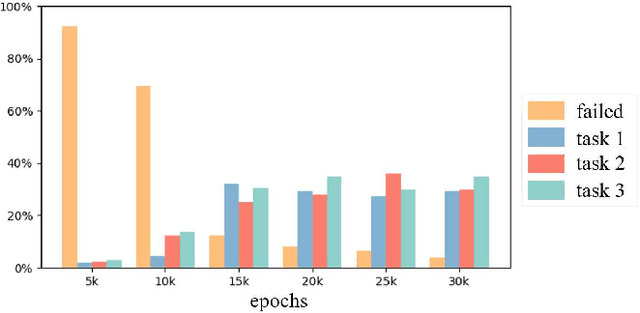
Automated Guided Vehicles (AGVs) have been widely used for material handling in flexible shop floors. Each product requires various raw materials to complete the assembly in production process. AGVs are used to realize the automatic handling of raw materials in different locations. Efficient AGVs task allocation strategy can reduce transportation costs and improve distribution efficiency. However, the traditional centralized approaches make high demands on the control center's computing power and real-time capability. In this paper, we present decentralized solutions to achieve flexible and self-organized AGVs task allocation. In particular, we propose two improved multi-agent reinforcement learning algorithms, MADDPG-IPF (Information Potential Field) and BiCNet-IPF, to realize the coordination among AGVs adapting to different scenarios. To address the reward-sparsity issue, we propose a reward shaping strategy based on information potential field, which provides stepwise rewards and implicitly guides the AGVs to different material targets. We conduct experiments under different settings (3 AGVs and 6 AGVs), and the experiment results indicate that, compared with baseline methods, our work obtains up to 47\% task response improvement and 22\% training iterations reduction.