 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Thrice Before You Speak: Dual knowledge-enhanced Theory-of-Mind Reasoning for Persuasive Agents
May 21, 2026Persuasive dialogue requires reasoning about others' latent mental states, a capability known as Theory of Mind (ToM). However, due to reliance on simple prompting strategies and insufficient ToM knowledge, existing LLMs often fail to capture the intrinsic dependencies among mental states, leading to fragmented representations and unstable reasoning. To address these challenges, we introduce the ToM-based Persuasive Dialogue (ToM-PD) task, grounded in the Belief-Desire-Intention (BDI) framework, which explicitly models the sequential dependencies among mental states in multi-turn dialogues. To facilitate research on this task, we construct a large-scale annotated dataset, ToM-based Broad Persuasive Dialogues (ToM-BPD), capturing fine-grained mental states and corresponding persuasive strategies. We further propose Think Thrice Before You Speak (TTBYS), a knowledge-enhanced stepwise reasoning framework that leverages both explicit and implicit prior experiences to improve LLMs' inference of desires, beliefs, and persuasive strategies. Experimental results demonstrate that Qwen3-8B equipped with TTBYS outperforms GPT-5 by 1.20%, 22.80%, and 16.97% in predicting desires, beliefs, and persuasive strategies, respectively. Case studies further show that our approach enhances interpretability and consistency in reasoning.
Foundation Models Defining A New Era In Sensor-based Human Activity Recognition: A Survey And Outlook
Apr 03, 2026Sensor-based Human Activity Recognition (HAR) underpins many ubiquitous and wearable computing applications, yet current models remain limited by scarce labels, sensor heterogeneity, and weak generalization across users, devices, and contexts. Foundation models, which are generally pretrained at scale using self-supervised and multimodal learning, offer a unifying paradigm to address these challenges by learning reusable, adaptable representations for activity understanding. This survey synthesizes emerging foundation models for sensor-based HAR. We first clarify foundational concepts, definitions, and evaluation criteria, then organize existing work using a lifecycle-oriented taxonomy spanning input design, pretraining, adaptation, and utilization. Rather than enumerating individual models, we analyze recurring design patterns and trade-offs across nine technical axes, including modality scope, tokenization, architectures, learning paradigms, adaptation mechanisms, and deployment settings. From this synthesis, we identify three dominant development trajectories: (1) HAR-specific foundation models trained from scratch on large sensor corpora, (2) adaptation of general time-series or multimodal foundation models to sensor-based HAR, and (3) integration of large language models for reasoning, annotation, and human-AI interaction. We conclude by highlighting open challenges in data curation, multimodal alignment, personalization, privacy, and responsible deployment, and outline directions toward general-purpose, interpretable, and human-centered foundation models for activity understanding. A complete, continuously updated index of papers and models is available in our companion repository: https://github.com/zhaxidele/Foundation-Models-Defining-A-New-Era-In-Human-Activity-Recognition.
Detecting Fake Reviewer Groups in Dynamic Networks: An Adaptive Graph Learning Method
Mar 09, 2026The proliferation of fake reviews, often produced by organized groups, undermines consumer trust and fair competition on online platforms. These groups employ sophisticated strategies that evade traditional detection methods, particularly in cold-start scenarios involving newly launched products with sparse data. To address this, we propose the \underline{D}iversity- and \underline{S}imilarity-aware \underline{D}ynamic \underline{G}raph \underline{A}ttention-enhanced \underline{G}raph \underline{C}onvolutional \underline{N}etwork (DS-DGA-GCN), a new graph learning model for detecting fake reviewer groups. DS-DGA-GCN achieves robust detection since it focuses on the joint relationships among products, reviews, and reviewers by modeling product-review-reviewer networks. DS-DGA-GCN also achieves adaptive detection by integrating a Network Feature Scoring (NFS) system and a new dynamic graph attention mechanism. The NFS system quantifies network attributes, including neighbor diversity, network self-similarity, as a unified feature score. The dynamic graph attention mechanism improves the adaptability and computational efficiency by captures features related to temporal information, node importance, and global network structure. Extensive experiments conducted on two real-world datasets derived from Amazon and Xiaohongshu demonstrate that DS-DGA-GCN significantly outperforms state-of-the-art baselines, achieving accuracies of up to \textbf{89.8\% and 88.3\%}, respectively.
MeCo: Enhancing LLM-Empowered Multi-Robot Collaboration via Similar Task Memoization
Jan 28, 2026Multi-robot systems have been widely deployed in real-world applications, providing significant improvements in efficiency and reductions in labor costs. However, most existing multi-robot collaboration methods rely on extensive task-specific training, which limits their adaptability to new or diverse scenarios. Recent research leverages the language understanding and reasoning capabilities of large language models (LLMs) to enable more flexible collaboration without specialized training. Yet, current LLM-empowered approaches remain inefficient: when confronted with identical or similar tasks, they must replan from scratch because they omit task-level similarities. To address this limitation, we propose MeCo, a similarity-aware multi-robot collaboration framework that applies the principle of ``cache and reuse'' (a.k.a., memoization) to reduce redundant computation. Unlike simple task repetition, identifying and reusing solutions for similar but not identical tasks is far more challenging, particularly in multi-robot settings. To this end, MeCo introduces a new similarity testing method that retrieves previously solved tasks with high relevance, enabling effective plan reuse without re-invoking LLMs. Furthermore, we present MeCoBench, the first benchmark designed to evaluate performance on similar-task collaboration scenarios. Experimental results show that MeCo substantially reduces planning costs and improves success rates compared with state-of-the-art approaches.
Adaptive Multi-Stage Patent Claim Generation with Unified Quality Assessment
Jan 14, 2026Current patent claim generation systems face three fundamental limitations: poor cross-jurisdictional generalization, inadequate semantic relationship modeling between claims and prior art, and unreliable quality assessment. We introduce a novel three-stage framework that addresses these challenges through relationship-aware similarity analysis, domain-adaptive claim generation, and unified quality assessment. Our approach employs multi-head attention with eight specialized heads for explicit relationship modeling, integrates curriculum learning with dynamic LoRA adapter selection across five patent domains, and implements cross-attention mechanisms between evaluation aspects for comprehensive quality assessment. Extensive experiments on USPTO HUPD dataset, EPO patent collections, and Patent-CE benchmark demonstrate substantial improvements: 7.6-point ROUGE-L gain over GPT-4o, 8.3\% BERTScore enhancement over Llama-3.1-8B, and 0.847 correlation with human experts compared to 0.623 for separate evaluation models. Our method maintains 89.4\% cross-jurisdictional performance retention versus 76.2\% for baselines, establishing a comprehensive solution for automated patent prosecution workflows.
Tri-Select: A Multi-Stage Visual Data Selection Framework for Mobile Visual Crowdsensing
Dec 18, 2025Mobile visual crowdsensing enables large-scale, fine-grained environmental monitoring through the collection of images from distributed mobile devices. However, the resulting data is often redundant and heterogeneous due to overlapping acquisition perspectives, varying resolutions, and diverse user behaviors. To address these challenges, this paper proposes Tri-Select, a multi-stage visual data selection framework that efficiently filters redundant and low-quality images. Tri-Select operates in three stages: (1) metadata-based filtering to discard irrelevant samples; (2) spatial similarity-based spectral clustering to organize candidate images; and (3) a visual-feature-guided selection based on maximum independent set search to retain high-quality, representative images. Experiments on real-world and public datasets demonstrate that Tri-Select improves both selection efficiency and dataset quality, making it well-suited for scalable crowdsensing applications.
AG-MPBS: a Mobility-Aware Prediction and Behavior-Based Scheduling Framework for Air-Ground Unmanned Systems
Dec 18, 2025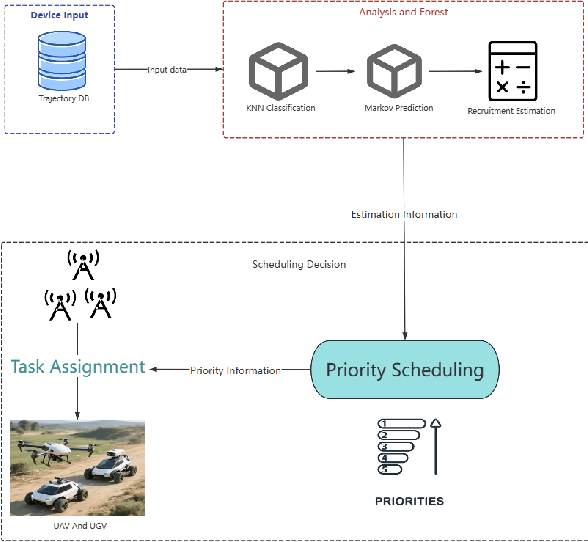
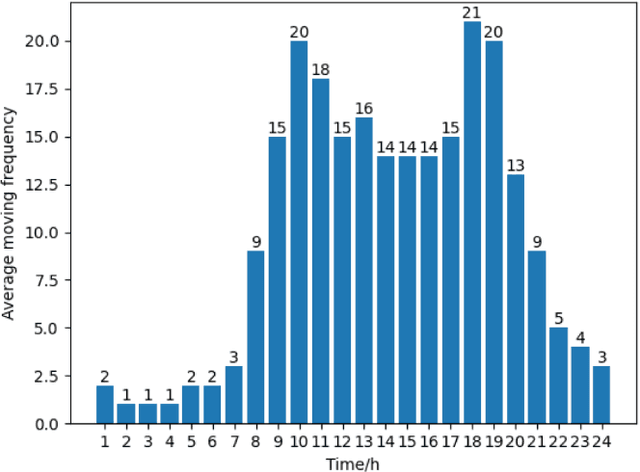
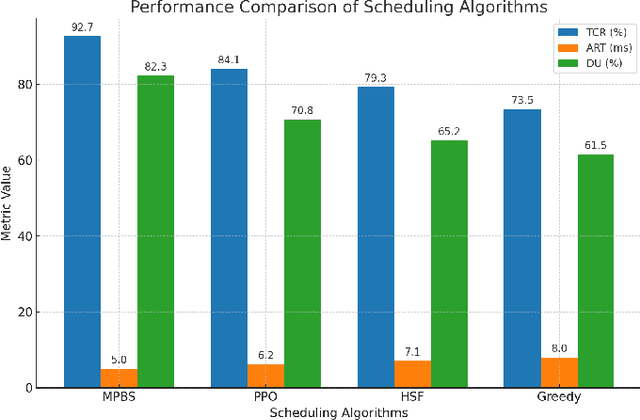
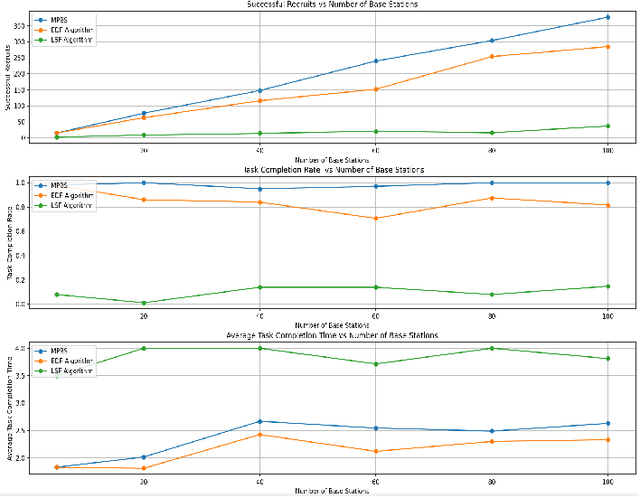
As unmanned systems such as Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs) become increasingly important to applications like urban sensing and emergency response, efficiently recruiting these autonomous devices to perform time-sensitive tasks has become a critical challenge. This paper presents MPBS (Mobility-aware Prediction and Behavior-based Scheduling), a scalable task recruitment framework that treats each device as a recruitable "user". MPBS integrates three key modules: a behavior-aware KNN classifier, a time-varying Markov prediction model for forecasting device mobility, and a dynamic priority scheduling mechanism that considers task urgency and base station performance. By combining behavioral classification with spatiotemporal prediction, MPBS adaptively assigns tasks to the most suitable devices in real time. Experimental evaluations on the real-world GeoLife dataset show that MPBS significantly improves task completion efficiency and resource utilization. The proposed framework offers a predictive, behavior-aware solution for intelligent and collaborative scheduling in unmanned systems.
MemoCue: Empowering LLM-Based Agents for Human Memory Recall via Strategy-Guided Querying
Jul 31, 2025Agent-assisted memory recall is one critical research problem in the field of human-computer interaction. In conventional methods, the agent can retrieve information from its equipped memory module to help the person recall incomplete or vague memories. The limited size of memory module hinders the acquisition of complete memories and impacts the memory recall performance in practice. Memory theories suggest that the person's relevant memory can be proactively activated through some effective cues. Inspired by this, we propose a novel strategy-guided agent-assisted memory recall method, allowing the agent to transform an original query into a cue-rich one via the judiciously designed strategy to help the person recall memories. To this end, there are two key challenges. (1) How to choose the appropriate recall strategy for diverse forgetting scenarios with distinct memory-recall characteristics? (2) How to obtain the high-quality responses leveraging recall strategies, given only abstract and sparsely annotated strategy patterns? To address the challenges, we propose a Recall Router framework. Specifically, we design a 5W Recall Map to classify memory queries into five typical scenarios and define fifteen recall strategy patterns across the corresponding scenarios. We then propose a hierarchical recall tree combined with the Monte Carlo Tree Search algorithm to optimize the selection of strategy and the generation of strategy responses. We construct an instruction tuning dataset and fine-tune multiple open-source large language models (LLMs) to develop MemoCue, an agent that excels in providing memory-inspired responses. Experiments on three representative datasets show that MemoCue surpasses LLM-based methods by 17.74% in recall inspiration. Further human evaluation highlights its advantages in memory-recall applications.
DeepTraverse: A Depth-First Search Inspired Network for Algorithmic Visual Understanding
Jun 11, 2025Conventional vision backbones, despite their success, often construct features through a largely uniform cascade of operations, offering limited explicit pathways for adaptive, iterative refinement. This raises a compelling question: can principles from classical search algorithms instill a more algorithmic, structured, and logical processing flow within these networks, leading to representations built through more interpretable, perhaps reasoning-like decision processes? We introduce DeepTraverse, a novel vision architecture directly inspired by algorithmic search strategies, enabling it to learn features through a process of systematic elucidation and adaptive refinement distinct from conventional approaches. DeepTraverse operationalizes this via two key synergistic components: recursive exploration modules that methodically deepen feature analysis along promising representational paths with parameter sharing for efficiency, and adaptive calibration modules that dynamically adjust feature salience based on evolving global context. The resulting algorithmic interplay allows DeepTraverse to intelligently construct and refine feature patterns. Comprehensive evaluations across a diverse suite of image classification benchmarks show that DeepTraverse achieves highly competitive classification accuracy and robust feature discrimination, often outperforming conventional models with similar or larger parameter counts. Our work demonstrates that integrating such algorithmic priors provides a principled and effective strategy for building more efficient, performant, and structured vision backbones.
JointDistill: Adaptive Multi-Task Distillation for Joint Depth Estimation and Scene Segmentation
May 15, 2025Depth estimation and scene segmentation are two important tasks in intelligent transportation systems. A joint modeling of these two tasks will reduce the requirement for both the storage and training efforts. This work explores how the multi-task distillation could be used to improve such unified modeling. While existing solutions transfer multiple teachers' knowledge in a static way, we propose a self-adaptive distillation method that can dynamically adjust the knowledge amount from each teacher according to the student's current learning ability. Furthermore, as multiple teachers exist, the student's gradient update direction in the distillation is more prone to be erroneous where knowledge forgetting may occur. To avoid this, we propose a knowledge trajectory to record the most essential information that a model has learnt in the past, based on which a trajectory-based distillation loss is designed to guide the student to follow the learning curve similarly in a cost-effective way. We evaluate our method on multiple benchmarking datasets including Cityscapes and NYU-v2. Compared to the state-of-the-art solutions, our method achieves a clearly improvement. The code is provided in the supplementary materials.