 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptInfer: Adaptive Token Pruning for Vision-Language Model Inference with Dynamical Text Guidance
Aug 08, 2025Vision-language models (VLMs) have achieved impressive performance on multimodal reasoning tasks such as visual question answering (VQA), but their inference cost remains a significant challenge due to the large number of vision tokens processed during the prefill stage. Existing pruning methods often rely on directly using the attention patterns or static text prompt guidance, failing to exploit the dynamic internal signals generated during inference. To address these issues, we propose AdaptInfer, a plug-and-play framework for adaptive vision token pruning in VLMs. First, we introduce a fine-grained, dynamic text-guided pruning mechanism that reuses layer-wise text-to-text attention maps to construct soft priors over text-token importance, allowing more informed scoring of vision tokens at each stage. Second, we perform an offline analysis of cross-modal attention shifts and identify consistent inflection locations in inference, which inspire us to propose a more principled and efficient pruning schedule. Our method is lightweight and plug-and-play, also generalizable across multi-modal tasks. Experimental results have verified the effectiveness of the proposed method. For example, it reduces CUDA latency by 61.3\% while maintaining an average accuracy of 92.9\% on vanilla LLaVA-1.5-7B. Under the same token budget, AdaptInfer surpasses SOTA in accuracy.
SynSeg: Feature Synergy for Multi-Category Contrastive Learning in Open-Vocabulary Semantic Segmentation
Aug 08, 2025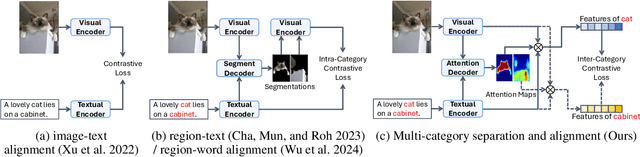
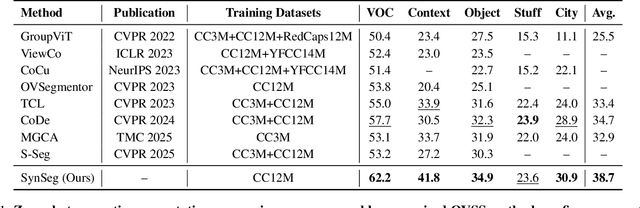
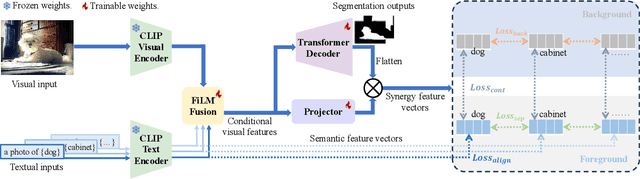
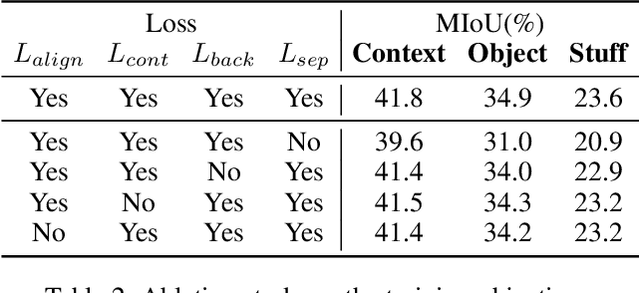
Semantic segmentation in open-vocabulary scenarios presents significant challenges due to the wide range and granularity of semantic categories. Existing weakly-supervised methods often rely on category-specific supervision and ill-suited feature construction methods for contrastive learning, leading to semantic misalignment and poor performance. In this work, we propose a novel weakly-supervised approach, SynSeg, to address the challenges. SynSeg performs Multi-Category Contrastive Learning (MCCL) as a stronger training signal with a new feature reconstruction framework named Feature Synergy Structure (FSS). Specifically, MCCL strategy robustly combines both intra- and inter-category alignment and separation in order to make the model learn the knowledge of correlations from different categories within the same image. Moreover, FSS reconstructs discriminative features for contrastive learning through prior fusion and semantic-activation-map enhancement, effectively avoiding the foreground bias introduced by the visual encoder. In general, SynSeg effectively improves the abilities in semantic localization and discrimination under weak supervision. Extensive experiments on benchmarks demonstrate that our method outperforms state-of-the-art (SOTA) performance. For instance, SynSeg achieves higher accuracy than SOTA baselines by 4.5\% on VOC, 8.9\% on Context, 2.6\% on Object and 2.0\% on City.
SURGEON: Memory-Adaptive Fully Test-Time Adaptation via Dynamic Activation Sparsity
Mar 26, 2025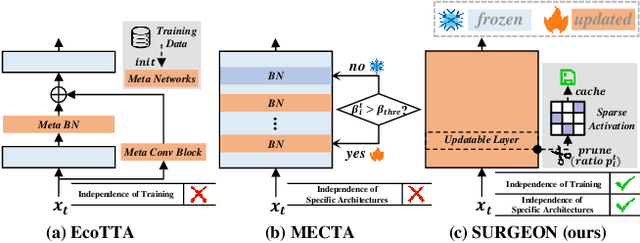
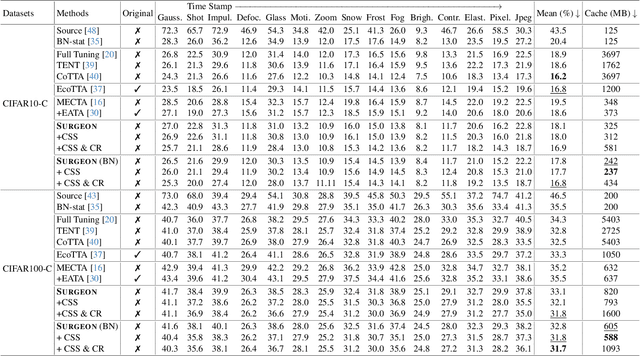
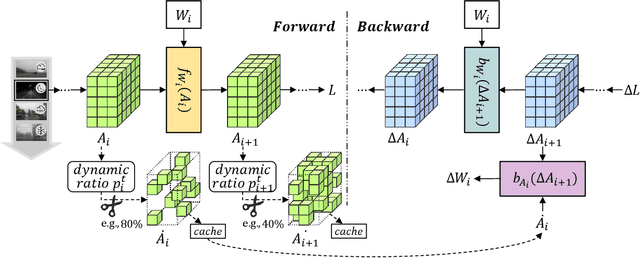
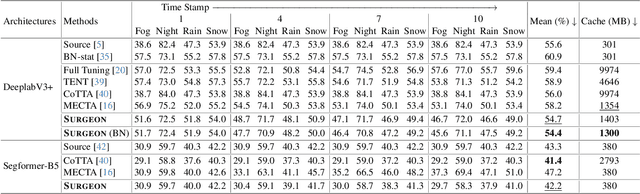
Despite the growing integration of deep models into mobile terminals, the accuracy of these models declines significantly due to various deployment interferences. Test-time adaptation (TTA) has emerged to improve the performance of deep models by adapting them to unlabeled target data online. Yet, the significant memory cost, particularly in resource-constrained terminals, impedes the effective deployment of most backward-propagation-based TTA methods. To tackle memory constraints, we introduce SURGEON, a method that substantially reduces memory cost while preserving comparable accuracy improvements during fully test-time adaptation (FTTA) without relying on specific network architectures or modifications to the original training procedure. Specifically, we propose a novel dynamic activation sparsity strategy that directly prunes activations at layer-specific dynamic ratios during adaptation, allowing for flexible control of learning ability and memory cost in a data-sensitive manner. Among this, two metrics, Gradient Importance and Layer Activation Memory, are considered to determine the layer-wise pruning ratios, reflecting accuracy contribution and memory efficiency, respectively. Experimentally, our method surpasses the baselines by not only reducing memory usage but also achieving superior accuracy, delivering SOTA performance across diverse datasets, architectures, and tasks.
Palantir: Towards Efficient Super Resolution for Ultra-high-definition Live Streaming
Aug 12, 2024Neural enhancement through super-resolution deep neural networks opens up new possibilities for ultra-high-definition live streaming over existing encoding and networking infrastructure. Yet, the heavy SR DNN inference overhead leads to severe deployment challenges. To reduce the overhead, existing systems propose to apply DNN-based SR only on selected anchor frames while upscaling non-anchor frames via the lightweight reusing-based SR approach. However, frame-level scheduling is coarse-grained and fails to deliver optimal efficiency. In this work, we propose Palantir, the first neural-enhanced UHD live streaming system with fine-grained patch-level scheduling. In the presented solutions, two novel techniques are incorporated to make good scheduling decisions for inference overhead optimization and reduce the scheduling latency. Firstly, under the guidance of our pioneering and theoretical analysis, Palantir constructs a directed acyclic graph (DAG) for lightweight yet accurate quality estimation under any possible anchor patch set. Secondly, to further optimize the scheduling latency, Palantir improves parallelizability by refactoring the computation subprocedure of the estimation process into a sparse matrix-matrix multiplication operation. The evaluation results suggest that Palantir incurs a negligible scheduling latency accounting for less than 5.7% of the end-to-end latency requirement. When compared to the state-of-the-art real-time frame-level scheduling strategy, Palantir reduces the energy overhead of SR-integrated mobile clients by 38.1% at most (and 22.4% on average) and the monetary costs of cloud-based SR by 80.1% at most (and 38.4% on average).
Calculus of Consent via MARL: Legitimating the Collaborative Governance Supplying Public Goods
Nov 20, 2021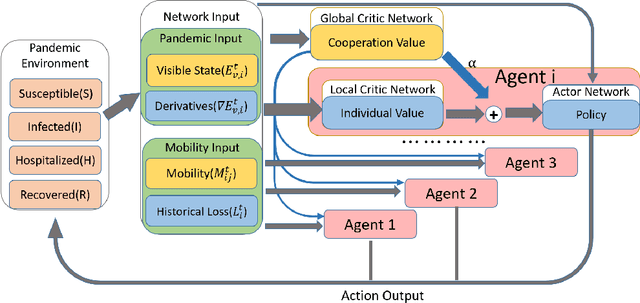
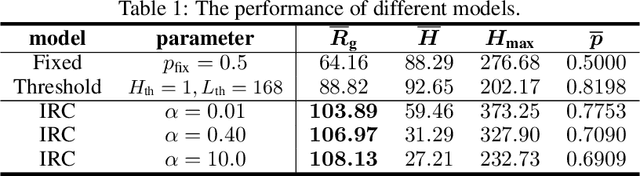
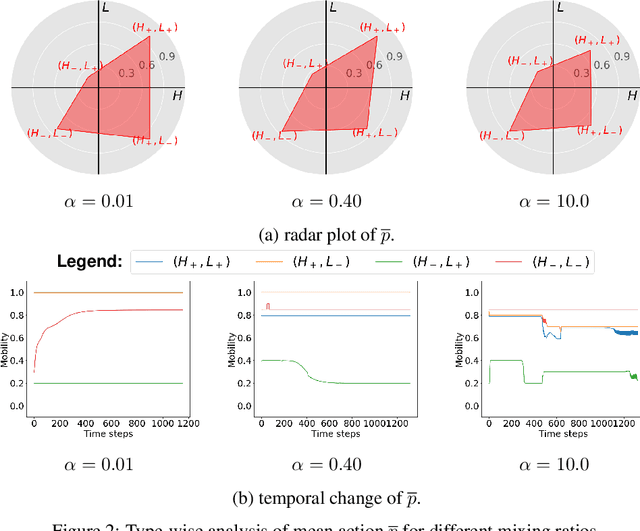

Public policies that supply public goods, especially those involve collaboration by limiting individual liberty, always give rise to controversies over governance legitimacy. Multi-Agent Reinforcement Learning (MARL) methods are appropriate for supporting the legitimacy of the public policies that supply public goods at the cost of individual interests. Among these policies, the inter-regional collaborative pandemic control is a prominent example, which has become much more important for an increasingly inter-connected world facing a global pandemic like COVID-19. Different patterns of collaborative strategies have been observed among different systems of regions, yet it lacks an analytical process to reason for the legitimacy of those strategies. In this paper, we use the inter-regional collaboration for pandemic control as an example to demonstrate the necessity of MARL in reasoning, and thereby legitimizing policies enforcing such inter-regional collaboration. Experimental results in an exemplary environment show that our MARL approach is able to demonstrate the effectiveness and necessity of restrictions on individual liberty for collaborative supply of public goods. Different optimal policies are learned by our MARL agents under different collaboration levels, which change in an interpretable pattern of collaboration that helps to balance the losses suffered by regions of different types, and consequently promotes the overall welfare. Meanwhile, policies learned with higher collaboration levels yield higher global rewards, which illustrates the benefit of, and thus provides a novel justification for the legitimacy of, promoting inter-regional collaboration. Therefore, our method shows the capability of MARL in computationally modeling and supporting the theory of calculus of consent, developed by Nobel Prize winner J. M. Buchanan.