 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliteKV: Scalable KV Cache Compression via RoPE Frequency Selection and Joint Low-Rank Projection
Mar 03, 2025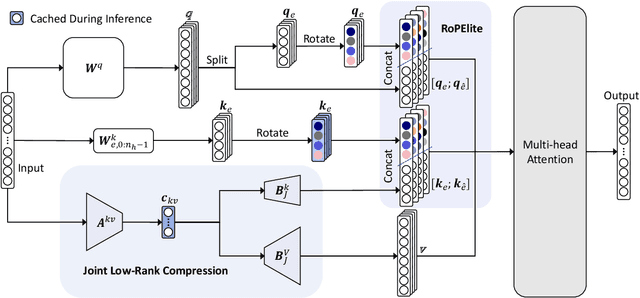
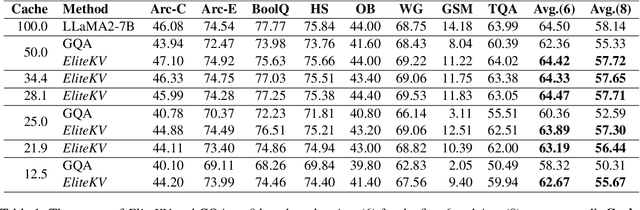


Rotary Position Embedding (RoPE) enables each attention head to capture multi-frequency information along the sequence dimension and is widely applied in foundation models. However, the nonlinearity introduced by RoPE complicates optimization of the key state in the Key-Value (KV) cache for RoPE-based attention. Existing KV cache compression methods typically store key state before rotation and apply the transformation during decoding, introducing additional computational overhead. This paper introduces EliteKV, a flexible modification framework for RoPE-based models supporting variable KV cache compression ratios. EliteKV first identifies the intrinsic frequency preference of each head using RoPElite, selectively restoring linearity to certain dimensions of key within attention computation. Building on this, joint low-rank compression of key and value enables partial cache sharing. Experimental results show that with minimal uptraining on only $0.6\%$ of the original training data, RoPE-based models achieve a $75\%$ reduction in KV cache size while preserving performance within a negligible margin. Furthermore, EliteKV consistently performs well across models of different scales within the same family.
MouSi: Poly-Visual-Expert Vision-Language Models
Jan 30, 2024Current large vision-language models (VLMs) often encounter challenges such as insufficient capabilities of a single visual component and excessively long visual tokens. These issues can limit the model's effectiveness in accurately interpreting complex visual information and over-lengthy contextual information. Addressing these challenges is crucial for enhancing the performance and applicability of VLMs. This paper proposes the use of ensemble experts technique to synergizes the capabilities of individual visual encoders, including those skilled in image-text matching, OCR, image segmentation, etc. This technique introduces a fusion network to unify the processing of outputs from different visual experts, while bridging the gap between image encoders and pre-trained LLMs. In addition, we explore different positional encoding schemes to alleviate the waste of positional encoding caused by lengthy image feature sequences, effectively addressing the issue of position overflow and length limitations. For instance, in our implementation, this technique significantly reduces the positional occupancy in models like SAM, from a substantial 4096 to a more efficient and manageable 64 or even down to 1. Experimental results demonstrate that VLMs with multiple experts exhibit consistently superior performance over isolated visual encoders and mark a significant performance boost as more experts are integrated. We have open-sourced the training code used in this report. All of these resources can be found on our project website.
Smooth Trajectory Collision Avoidance through Deep Reinforcement Learning
Oct 12, 2022
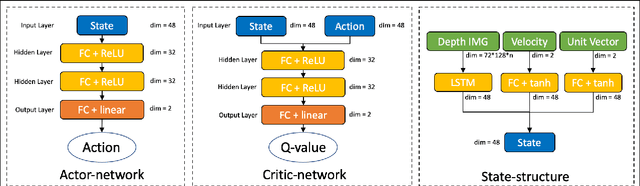
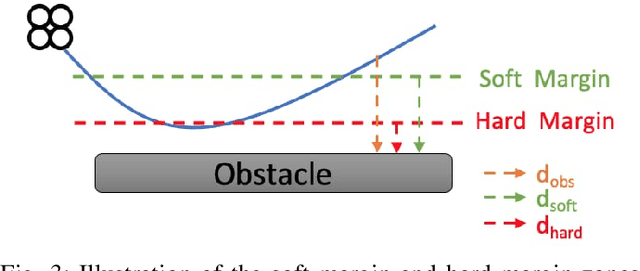
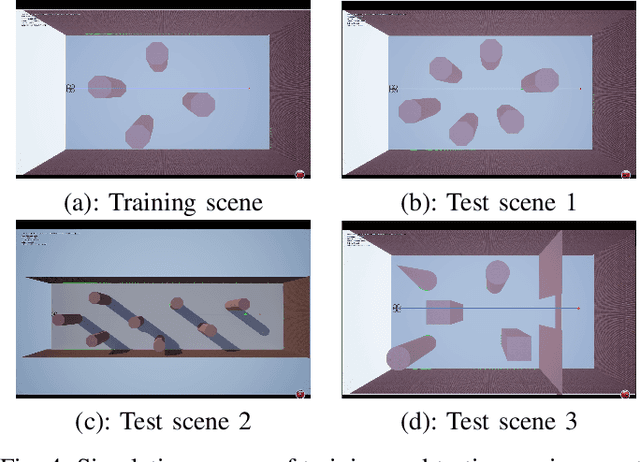
Collision avoidance is a crucial task in vision-guided autonomous navigation. Solutions based on deep reinforcement learning (DRL) has become increasingly popular. In this work, we proposed several novel agent state and reward function designs to tackle two critical issues in DRL-based navigation solutions: 1) smoothness of the trained flight trajectories; and 2) model generalization to handle unseen environments. Formulated under a DRL framework, our model relies on margin reward and smoothness constraints to ensure UAVs fly smoothly while greatly reducing the chance of collision. The proposed smoothness reward minimizes a combination of first-order and second-order derivatives of flight trajectories, which can also drive the points to be evenly distributed, leading to stable flight speed. To enhance the agent's capability of handling new unseen environments, two practical setups are proposed to improve the invariance of both the state and reward function when deploying in different scenes. Experiments demonstrate the effectiveness of our overall design and individual components.
Unbiased Implicit Feedback via Bi-level Optimization
May 31, 2022
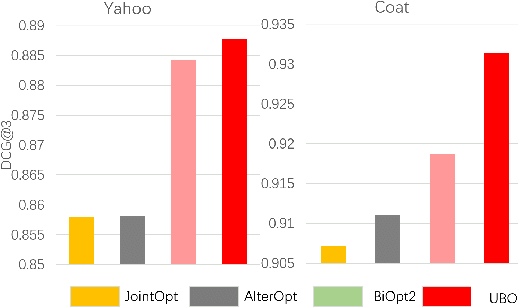
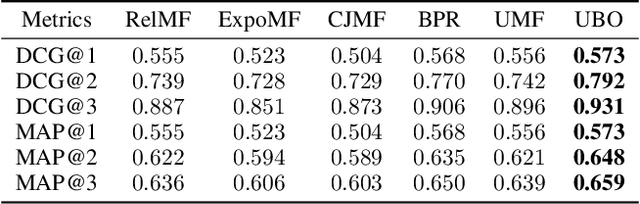

Implicit feedback is widely leveraged in recommender systems since it is easy to collect and provides weak supervision signals. Recent works reveal a huge gap between the implicit feedback and user-item relevance due to the fact that implicit feedback is also closely related to the item exposure. To bridge this gap, existing approaches explicitly model the exposure and propose unbiased estimators to improve the relevance. Unfortunately, these unbiased estimators suffer from the high gradient variance, especially for long-tail items, leading to inaccurate gradient updates and degraded model performance. To tackle this challenge, we propose a low-variance unbiased estimator from a probabilistic perspective, which effectively bounds the variance of the gradient. Unlike previous works which either estimate the exposure via heuristic-based strategies or use a large biased training set, we propose to estimate the exposure via an unbiased small-scale validation set. Specifically, we first parameterize the user-item exposure by incorporating both user and item information, and then construct an unbiased validation set from the biased training set. By leveraging the unbiased validation set, we adopt bi-level optimization to automatically update exposure-related parameters along with recommendation model parameters during the learning. Experiments on two real-world datasets and two semi-synthetic datasets verify the effectiveness of our method.
Calculus of Consent via MARL: Legitimating the Collaborative Governance Supplying Public Goods
Nov 20, 2021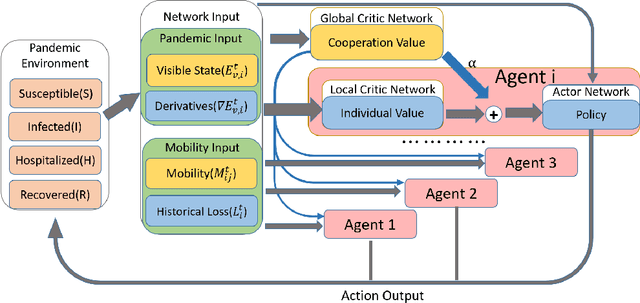
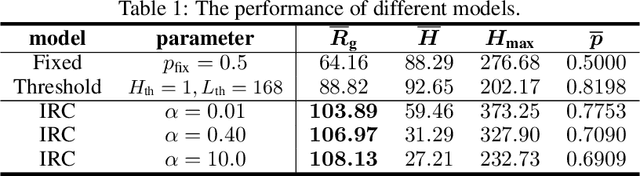
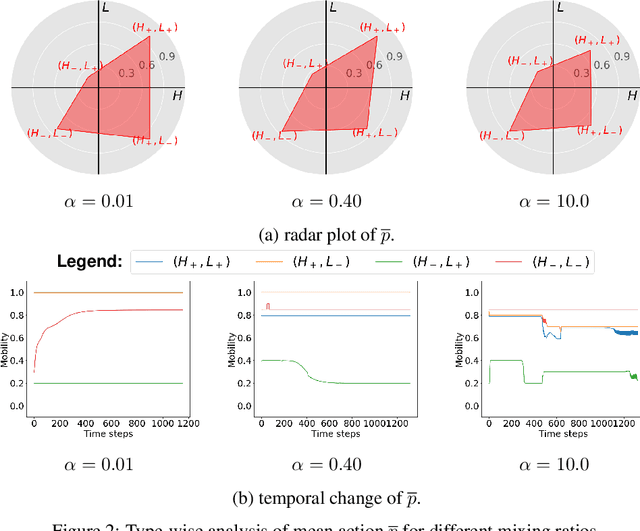

Public policies that supply public goods, especially those involve collaboration by limiting individual liberty, always give rise to controversies over governance legitimacy. Multi-Agent Reinforcement Learning (MARL) methods are appropriate for supporting the legitimacy of the public policies that supply public goods at the cost of individual interests. Among these policies, the inter-regional collaborative pandemic control is a prominent example, which has become much more important for an increasingly inter-connected world facing a global pandemic like COVID-19. Different patterns of collaborative strategies have been observed among different systems of regions, yet it lacks an analytical process to reason for the legitimacy of those strategies. In this paper, we use the inter-regional collaboration for pandemic control as an example to demonstrate the necessity of MARL in reasoning, and thereby legitimizing policies enforcing such inter-regional collaboration. Experimental results in an exemplary environment show that our MARL approach is able to demonstrate the effectiveness and necessity of restrictions on individual liberty for collaborative supply of public goods. Different optimal policies are learned by our MARL agents under different collaboration levels, which change in an interpretable pattern of collaboration that helps to balance the losses suffered by regions of different types, and consequently promotes the overall welfare. Meanwhile, policies learned with higher collaboration levels yield higher global rewards, which illustrates the benefit of, and thus provides a novel justification for the legitimacy of, promoting inter-regional collaboration. Therefore, our method shows the capability of MARL in computationally modeling and supporting the theory of calculus of consent, developed by Nobel Prize winner J. M. Buchanan.
Reinforced Contact Tracing and Epidemic Intervention
Feb 04, 2021


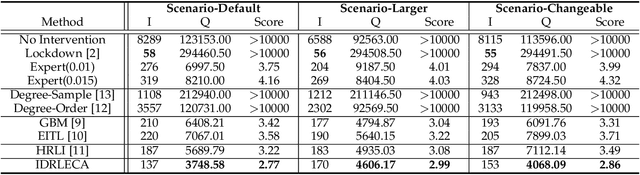
The recent outbreak of COVID-19 poses a serious threat to people's lives. Epidemic control strategies have also caused damage to the economy by cutting off humans' daily commute. In this paper, we develop an Individual-based Reinforcement Learning Epidemic Control Agent (IDRLECA) to search for smart epidemic control strategies that can simultaneously minimize infections and the cost of mobility intervention. IDRLECA first hires an infection probability model to calculate the current infection probability of each individual. Then, the infection probabilities together with individuals' health status and movement information are fed to a novel GNN to estimate the spread of the virus through human contacts. The estimated risks are used to further support an RL agent to select individual-level epidemic-control actions. The training of IDRLECA is guided by a specially designed reward function considering both the cost of mobility intervention and the effectiveness of epidemic control. Moreover, we design a constraint for control-action selection that eases its difficulty and further improve exploring efficiency. Extensive experimental results demonstrate that IDRLECA can suppress infections at a very low level and retain more than 95% of human mobility.
Reinforced Epidemic Control: Saving Both Lives and Economy
Aug 04, 2020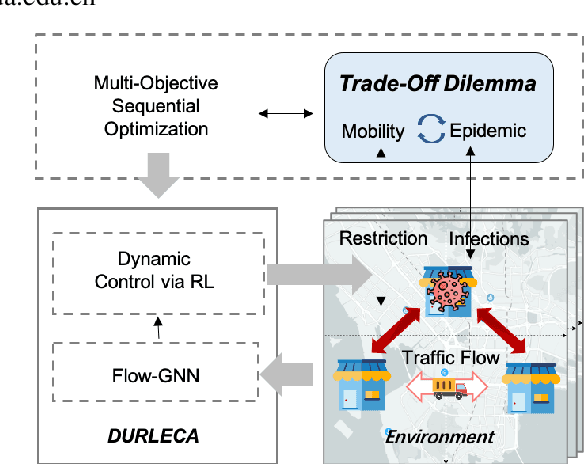
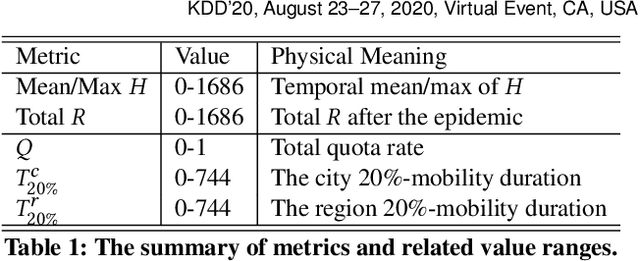
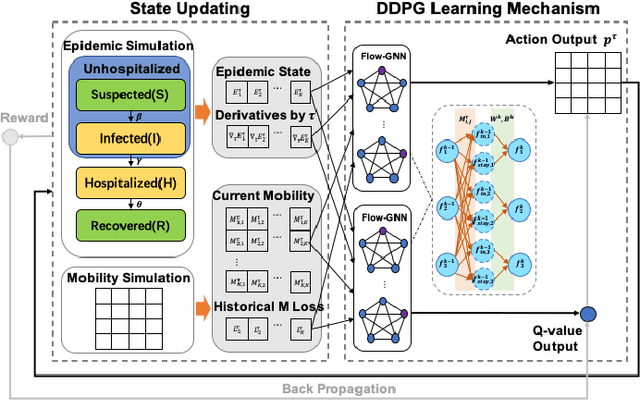
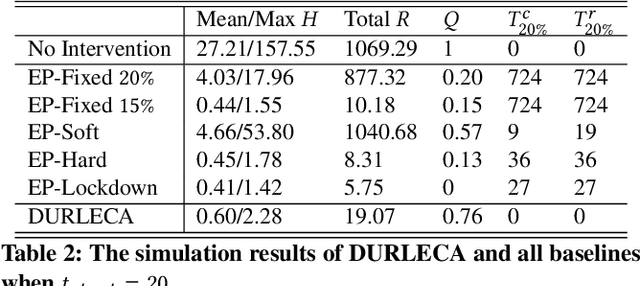
Saving lives or economy is a dilemma for epidemic control in most cities while smart-tracing technology raises people's privacy concerns. In this paper, we propose a solution for the life-or-economy dilemma that does not require private data. We bypass the private-data requirement by suppressing epidemic transmission through a dynamic control on inter-regional mobility that only relies on Origin-Designation (OD) data. We develop DUal-objective Reinforcement-Learning Epidemic Control Agent (DURLECA) to search mobility-control policies that can simultaneously minimize infection spread and maximally retain mobility. DURLECA hires a novel graph neural network, namely Flow-GNN, to estimate the virus-transmission risk induced by urban mobility. The estimated risk is used to support a reinforcement learning agent to generate mobility-control actions. The training of DURLECA is guided with a well-constructed reward function, which captures the natural trade-off relation between epidemic control and mobility retaining. Besides, we design two exploration strategies to improve the agent's searching efficiency and help it get rid of local optimums. Extensive experimental results on a real-world OD dataset show that DURLECA is able to suppress infections at an extremely low level while retaining 76\% of the mobility in the city. Our implementation is available at https://github.com/anyleopeace/DURLECA/.
UrbanRhythm: Revealing Urban Dynamics Hidden in Mobility Data
Nov 03, 2019
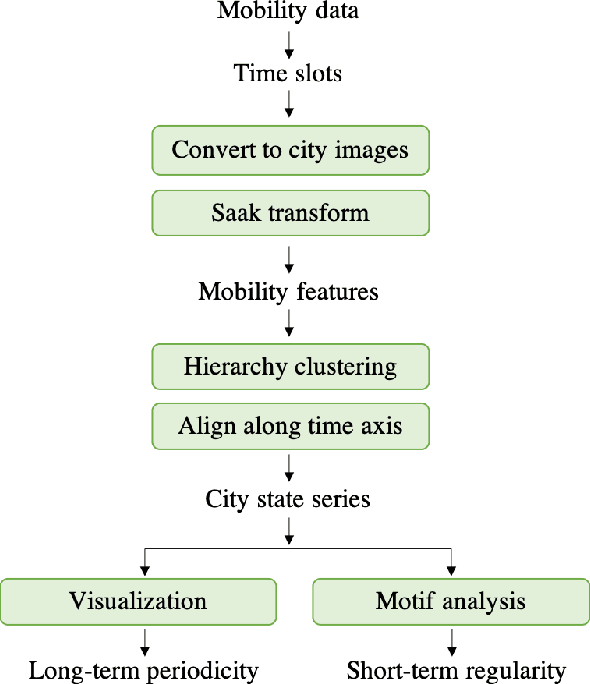


Understanding urban dynamics, i.e., how the types and intensity of urban residents' activities in the city change along with time, is of urgent demand for building an efficient and livable city. Nonetheless, this is challenging due to the expanding urban population and the complicated spatial distribution of residents. In this paper, to reveal urban dynamics, we propose a novel system UrbanRhythm to reveal the urban dynamics hidden in human mobility data. UrbanRhythm addresses three questions: 1) What mobility feature should be used to present residents' high-dimensional activities in the city? 2) What are basic components of urban dynamics? 3) What are the long-term periodicity and short-term regularity of urban dynamics? In UrbanRhythm, we extract staying, leaving, arriving three attributes of mobility and use a image processing method Saak transform to calculate the mobility distribution feature. For the second question, several city states are identified by hierarchy clustering as the basic components of urban dynamics, such as sleeping states and working states. We further characterize the urban dynamics as the transform of city states along time axis. For the third question, we directly observe the long-term periodicity of urban dynamics from visualization. Then for the short-term regularity, we design a novel motif analysis method to discovery motifs as well as their hierarchy relationships. We evaluate our proposed system on two real-life datesets and validate the results according to App usage records. This study sheds light on urban dynamics hidden in human mobility and can further pave the way for more complicated mobility behavior modeling and deeper urban understanding.