 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoHealth: An Uncertainty-Aware Multi-Agent System for Autonomous Health Data Modeling
Feb 01, 2026LLM-based agents have demonstrated strong potential for autonomous machine learning, yet their applicability to health data remains limited. Existing systems often struggle to generalize across heterogeneous health data modalities, rely heavily on predefined solution templates with insufficient adaptation to task-specific objectives, and largely overlook uncertainty estimation, which is essential for reliable decision-making in healthcare. To address these challenges, we propose \textit{AutoHealth}, a novel uncertainty-aware multi-agent system that autonomously models health data and assesses model reliability. \textit{AutoHealth} employs closed-loop coordination among five specialized agents to perform data exploration, task-conditioned model construction, training, and optimization, while jointly prioritizing predictive performance and uncertainty quantification. Beyond producing ready-to-use models, the system generates comprehensive reports to support trustworthy interpretation and risk-aware decision-making. To rigorously evaluate its effectiveness, we curate a challenging real-world benchmark comprising 17 tasks across diverse data modalities and learning settings. \textit{AutoHealth} completes all tasks and outperforms state-of-the-art baselines by 29.2\% in prediction performance and 50.2\% in uncertainty estimation.
UniPACT: A Multimodal Framework for Prognostic Question Answering on Raw ECG and Structured EHR
Jan 25, 2026Accurate clinical prognosis requires synthesizing structured Electronic Health Records (EHRs) with real-time physiological signals like the Electrocardiogram (ECG). Large Language Models (LLMs) offer a powerful reasoning engine for this task but struggle to natively process these heterogeneous, non-textual data types. To address this, we propose UniPACT (Unified Prognostic Question Answering for Clinical Time-series), a unified framework for prognostic question answering that bridges this modality gap. UniPACT's core contribution is a structured prompting mechanism that converts numerical EHR data into semantically rich text. This textualized patient context is then fused with representations learned directly from raw ECG waveforms, enabling an LLM to reason over both modalities holistically. We evaluate UniPACT on the comprehensive MDS-ED benchmark, it achieves a state-of-the-art mean AUROC of 89.37% across a diverse set of prognostic tasks including diagnosis, deterioration, ICU admission, and mortality, outperforming specialized baselines. Further analysis demonstrates that our multimodal, multi-task approach is critical for performance and provides robustness in missing data scenarios.
Unified Multi-task Learning for Voice-Based Detection of Diverse Clinical Conditions
Aug 28, 2025Voice-based health assessment offers unprecedented opportunities for scalable, non-invasive disease screening, yet existing approaches typically focus on single conditions and fail to leverage the rich, multi-faceted information embedded in speech. We present MARVEL (Multi-task Acoustic Representations for Voice-based Health Analysis), a privacy-conscious multitask learning framework that simultaneously detects nine distinct neurological, respiratory, and voice disorders using only derived acoustic features, eliminating the need for raw audio transmission. Our dual-branch architecture employs specialized encoders with task-specific heads sharing a common acoustic backbone, enabling effective cross-condition knowledge transfer. Evaluated on the large-scale Bridge2AI-Voice v2.0 dataset, MARVEL achieves an overall AUROC of 0.78, with exceptional performance on neurological disorders (AUROC = 0.89), particularly for Alzheimer's disease/mild cognitive impairment (AUROC = 0.97). Our framework consistently outperforms single-modal baselines by 5-19% and surpasses state-of-the-art self-supervised models on 7 of 9 tasks, while correlation analysis reveals that the learned representations exhibit meaningful similarities with established acoustic features, indicating that the model's internal representations are consistent with clinically recognized acoustic patterns. By demonstrating that a single unified model can effectively screen for diverse conditions, this work establishes a foundation for deployable voice-based diagnostics in resource-constrained and remote healthcare settings.
SurvUnc: A Meta-Model Based Uncertainty Quantification Framework for Survival Analysis
May 20, 2025Survival analysis, which estimates the probability of event occurrence over time from censored data, is fundamental in numerous real-world applications, particularly in high-stakes domains such as healthcare and risk assessment. Despite advances in numerous survival models, quantifying the uncertainty of predictions from these models remains underexplored and challenging. The lack of reliable uncertainty quantification limits the interpretability and trustworthiness of survival models, hindering their adoption in clinical decision-making and other sensitive applications. To bridge this gap, in this work, we introduce SurvUnc, a novel meta-model based framework for post-hoc uncertainty quantification for survival models. SurvUnc introduces an anchor-based learning strategy that integrates concordance knowledge into meta-model optimization, leveraging pairwise ranking performance to estimate uncertainty effectively. Notably, our framework is model-agnostic, ensuring compatibility with any survival model without requiring modifications to its architecture or access to its internal parameters. Especially, we design a comprehensive evaluation pipeline tailored to this critical yet overlooked problem. Through extensive experiments on four publicly available benchmarking datasets and five representative survival models, we demonstrate the superiority of SurvUnc across multiple evaluation scenarios, including selective prediction, misprediction detection, and out-of-domain detection. Our results highlight the effectiveness of SurvUnc in enhancing model interpretability and reliability, paving the way for more trustworthy survival predictions in real-world applications.
Electrocardiogram-Language Model for Few-Shot Question Answering with Meta Learning
Oct 18, 2024Electrocardiogram (ECG) interpretation requires specialized expertise, often involving synthesizing insights from ECG signals with complex clinical queries posed in natural language. The scarcity of labeled ECG data coupled with the diverse nature of clinical inquiries presents a significant challenge for developing robust and adaptable ECG diagnostic systems. This work introduces a novel multimodal meta-learning method for few-shot ECG question answering, addressing the challenge of limited labeled data while leveraging the rich knowledge encoded within large language models (LLMs). Our LLM-agnostic approach integrates a pre-trained ECG encoder with a frozen LLM (e.g., LLaMA and Gemma) via a trainable fusion module, enabling the language model to reason about ECG data and generate clinically meaningful answers. Extensive experiments demonstrate superior generalization to unseen diagnostic tasks compared to supervised baselines, achieving notable performance even with limited ECG leads. For instance, in a 5-way 5-shot setting, our method using LLaMA-3.1-8B achieves accuracy of 84.6%, 77.3%, and 69.6% on single verify, choose and query question types, respectively. These results highlight the potential of our method to enhance clinical ECG interpretation by combining signal processing with the nuanced language understanding capabilities of LLMs, particularly in data-constrained scenarios.
RespLLM: Unifying Audio and Text with Multimodal LLMs for Generalized Respiratory Health Prediction
Oct 07, 2024
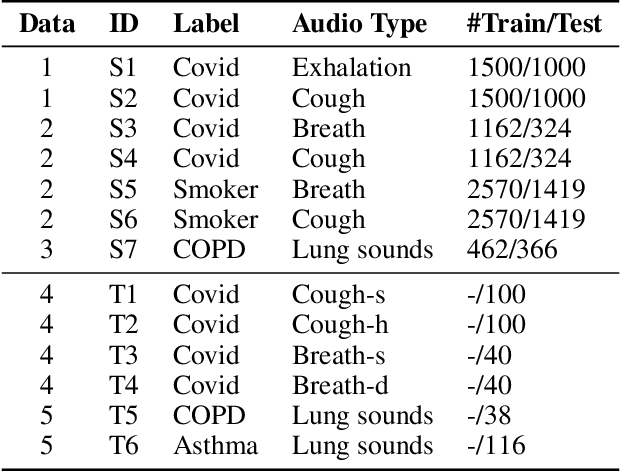
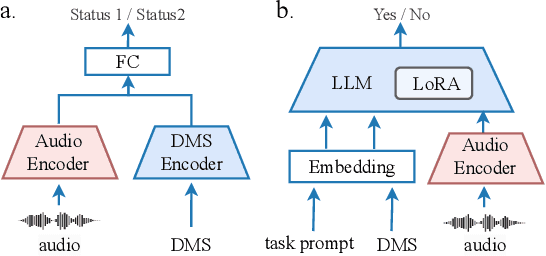
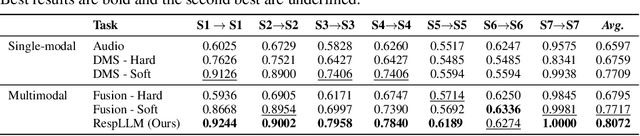
The high incidence and mortality rates associated with respiratory diseases underscores the importance of early screening. Machine learning models can automate clinical consultations and auscultation, offering vital support in this area. However, the data involved, spanning demographics, medical history, symptoms, and respiratory audio, are heterogeneous and complex. Existing approaches are insufficient and lack generalizability, as they typically rely on limited training data, basic fusion techniques, and task-specific models. In this paper, we propose RespLLM, a novel multimodal large language model (LLM) framework that unifies text and audio representations for respiratory health prediction. RespLLM leverages the extensive prior knowledge of pretrained LLMs and enables effective audio-text fusion through cross-modal attentions. Instruction tuning is employed to integrate diverse data from multiple sources, ensuring generalizability and versatility of the model. Experiments on five real-world datasets demonstrate that RespLLM outperforms leading baselines by an average of 4.6% on trained tasks, 7.9% on unseen datasets, and facilitates zero-shot predictions for new tasks. Our work lays the foundation for multimodal models that can perceive, listen to, and understand heterogeneous data, paving the way for scalable respiratory health diagnosis.
Electrocardiogram Report Generation and Question Answering via Retrieval-Augmented Self-Supervised Modeling
Sep 13, 2024



Interpreting electrocardiograms (ECGs) and generating comprehensive reports remain challenging tasks in cardiology, often requiring specialized expertise and significant time investment. To address these critical issues, we propose ECG-ReGen, a retrieval-based approach for ECG-to-text report generation and question answering. Our method leverages a self-supervised learning for the ECG encoder, enabling efficient similarity searches and report retrieval. By combining pre-training with dynamic retrieval and Large Language Model (LLM)-based refinement, ECG-ReGen effectively analyzes ECG data and answers related queries, with the potential of improving patient care. Experiments conducted on the PTB-XL and MIMIC-IV-ECG datasets demonstrate superior performance in both in-domain and cross-domain scenarios for report generation. Furthermore, our approach exhibits competitive performance on ECG-QA dataset compared to fully supervised methods when utilizing off-the-shelf LLMs for zero-shot question answering. This approach, effectively combining self-supervised encoder and LLMs, offers a scalable and efficient solution for accurate ECG interpretation, holding significant potential to enhance clinical decision-making.
Towards Open Respiratory Acoustic Foundation Models: Pretraining and Benchmarking
Jun 23, 2024



Respiratory audio, such as coughing and breathing sounds, has predictive power for a wide range of healthcare applications, yet is currently under-explored. The main problem for those applications arises from the difficulty in collecting large labeled task-specific data for model development. Generalizable respiratory acoustic foundation models pretrained with unlabeled data would offer appealing advantages and possibly unlock this impasse. However, given the safety-critical nature of healthcare applications, it is pivotal to also ensure openness and replicability for any proposed foundation model solution. To this end, we introduce OPERA, an OPEn Respiratory Acoustic foundation model pretraining and benchmarking system, as the first approach answering this need. We curate large-scale respiratory audio datasets (~136K samples, 440 hours), pretrain three pioneering foundation models, and build a benchmark consisting of 19 downstream respiratory health tasks for evaluation. Our pretrained models demonstrate superior performance (against existing acoustic models pretrained with general audio on 16 out of 19 tasks) and generalizability (to unseen datasets and new respiratory audio modalities). This highlights the great promise of respiratory acoustic foundation models and encourages more studies using OPERA as an open resource to accelerate research on respiratory audio for health. The system is accessible from https://github.com/evelyn0414/OPERA.
FLea: Addressing Data Scarcity and Label Skew in Federated Learning via Privacy-preserving Feature Augmentation
Jun 13, 2024Federated Learning (FL) enables model development by leveraging data distributed across numerous edge devices without transferring local data to a central server. However, existing FL methods still face challenges when dealing with scarce and label-skewed data across devices, resulting in local model overfitting and drift, consequently hindering the performance of the global model. In response to these challenges, we propose a pioneering framework called FLea, incorporating the following key components: i) A global feature buffer that stores activation-target pairs shared from multiple clients to support local training. This design mitigates local model drift caused by the absence of certain classes; ii) A feature augmentation approach based on local and global activation mix-ups for local training. This strategy enlarges the training samples, thereby reducing the risk of local overfitting; iii) An obfuscation method to minimize the correlation between intermediate activations and the source data, enhancing the privacy of shared features. To verify the superiority of FLea, we conduct extensive experiments using a wide range of data modalities, simulating different levels of local data scarcity and label skew. The results demonstrate that FLea consistently outperforms state-of-the-art FL counterparts (among 13 of the experimented 18 settings, the improvement is over 5% while concurrently mitigating the privacy vulnerabilities associated with shared features. Code is available at https://github.com/XTxiatong/FLea.git.
FLea: Improving federated learning on scarce and label-skewed data via privacy-preserving feature augmentation
Dec 04, 2023Learning a global model by abstracting the knowledge, distributed across multiple clients, without aggregating the raw data is the primary goal of Federated Learning (FL). Typically, this works in rounds alternating between parallel local training at several clients, followed by model aggregation at a server. We found that existing FL methods under-perform when local datasets are small and present severe label skew as these lead to over-fitting and local model bias. This is a realistic setting in many real-world applications. To address the problem, we propose \textit{FLea}, a unified framework that tackles over-fitting and local bias by encouraging clients to exchange privacy-protected features to aid local training. The features refer to activations from an intermediate layer of the model, which are obfuscated before being shared with other clients to protect sensitive information in the data. \textit{FLea} leverages a novel way of combining local and shared features as augmentations to enhance local model learning. Our extensive experiments demonstrate that \textit{FLea} outperforms the start-of-the-art FL methods, sharing only model parameters, by up to $17.6\%$, and FL methods that share data augmentations by up to $6.3\%$, while reducing the privacy vulnerability associated with shared data augmentations.