 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespLLM: Unifying Audio and Text with Multimodal LLMs for Generalized Respiratory Health Prediction
Paper and Code
Oct 07, 2024
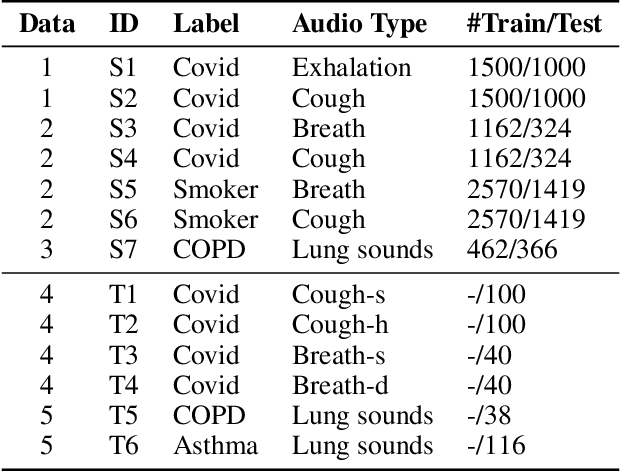
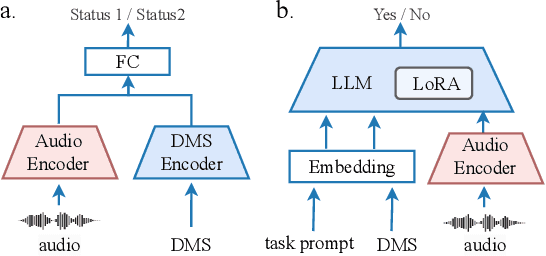
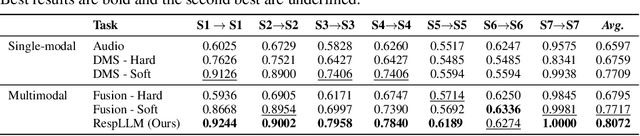
The high incidence and mortality rates associated with respiratory diseases underscores the importance of early screening. Machine learning models can automate clinical consultations and auscultation, offering vital support in this area. However, the data involved, spanning demographics, medical history, symptoms, and respiratory audio, are heterogeneous and complex. Existing approaches are insufficient and lack generalizability, as they typically rely on limited training data, basic fusion techniques, and task-specific models. In this paper, we propose RespLLM, a novel multimodal large language model (LLM) framework that unifies text and audio representations for respiratory health prediction. RespLLM leverages the extensive prior knowledge of pretrained LLMs and enables effective audio-text fusion through cross-modal attentions. Instruction tuning is employed to integrate diverse data from multiple sources, ensuring generalizability and versatility of the model. Experiments on five real-world datasets demonstrate that RespLLM outperforms leading baselines by an average of 4.6% on trained tasks, 7.9% on unseen datasets, and facilitates zero-shot predictions for new tasks. Our work lays the foundation for multimodal models that can perceive, listen to, and understand heterogeneous data, paving the way for scalable respiratory health diagnosis.