 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNC2C: Automated Convexification of Generic Non-Convex Optimization Problems
Jan 08, 2026Non-convex optimization problems are pervasive across mathematical programming, engineering design, and scientific computing, often posing intractable challenges for traditional solvers due to their complex objective functions and constrained landscapes. To address the inefficiency of manual convexification and the over-reliance on expert knowledge, we propose NC2C, an LLM-based end-to-end automated framework designed to transform generic non-convex optimization problems into solvable convex forms using large language models. NC2C leverages LLMs' mathematical reasoning capabilities to autonomously detect non-convex components, select optimal convexification strategies, and generate rigorous convex equivalents. The framework integrates symbolic reasoning, adaptive transformation techniques, and iterative validation, equipped with error correction loops and feasibility domain correction mechanisms to ensure the robustness and validity of transformed problems. Experimental results on a diverse dataset of 100 generic non-convex problems demonstrate that NC2C achieves an 89.3\% execution rate and a 76\% success rate in producing feasible, high-quality convex transformations. This outperforms baseline methods by a significant margin, highlighting NC2C's ability to leverage LLMs for automated non-convex to convex transformation, reduce expert dependency, and enable efficient deployment of convex solvers for previously intractable optimization tasks.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025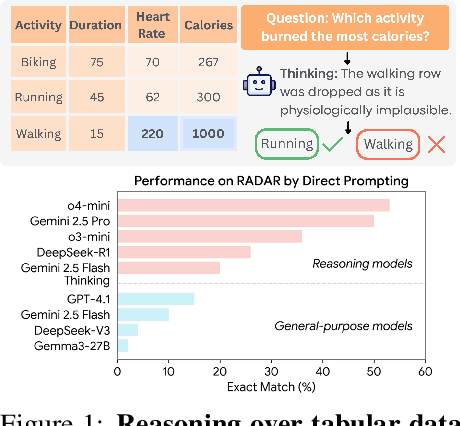
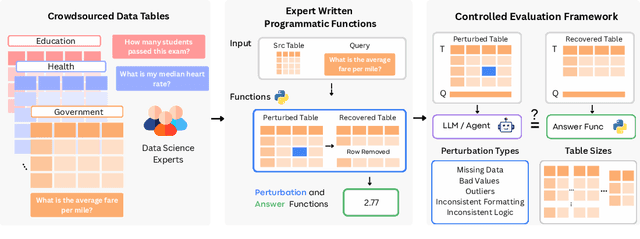
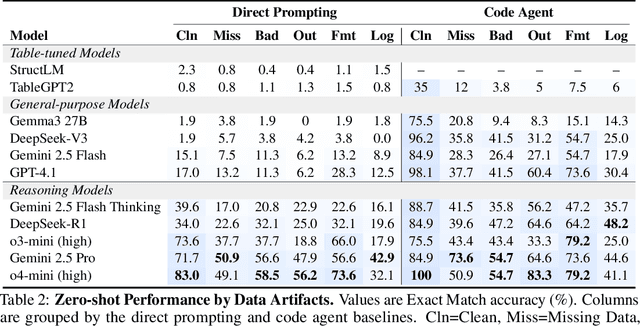
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Bidirectional LMs are Better Knowledge Memorizers? A Benchmark for Real-world Knowledge Injection
May 18, 2025Despite significant advances in large language models (LLMs), their knowledge memorization capabilities remain underexplored, due to the lack of standardized and high-quality test ground. In this paper, we introduce a novel, real-world and large-scale knowledge injection benchmark that evolves continuously over time without requiring human intervention. Specifically, we propose WikiDYK, which leverages recently-added and human-written facts from Wikipedia's "Did You Know..." entries. These entries are carefully selected by expert Wikipedia editors based on criteria such as verifiability and clarity. Each entry is converted into multiple question-answer pairs spanning diverse task formats from easy cloze prompts to complex multi-hop questions. WikiDYK contains 12,290 facts and 77,180 questions, which is also seamlessly extensible with future updates from Wikipedia editors. Extensive experiments using continued pre-training reveal a surprising insight: despite their prevalence in modern LLMs, Causal Language Models (CLMs) demonstrate significantly weaker knowledge memorization capabilities compared to Bidirectional Language Models (BiLMs), exhibiting a 23% lower accuracy in terms of reliability. To compensate for the smaller scales of current BiLMs, we introduce a modular collaborative framework utilizing ensembles of BiLMs as external knowledge repositories to integrate with LLMs. Experiment shows that our framework further improves the reliability accuracy by up to 29.1%.
Seedream 3.0 Technical Report
Apr 16, 2025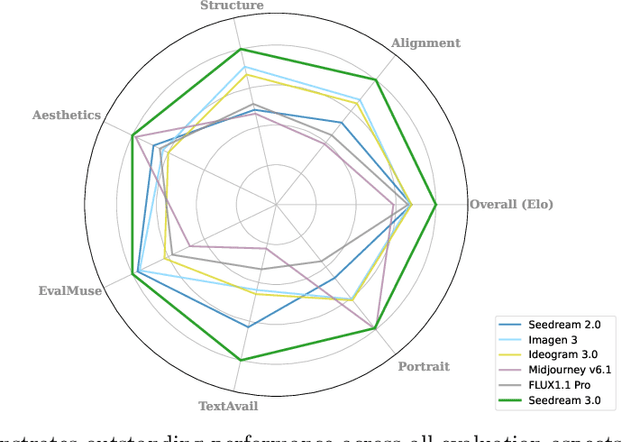


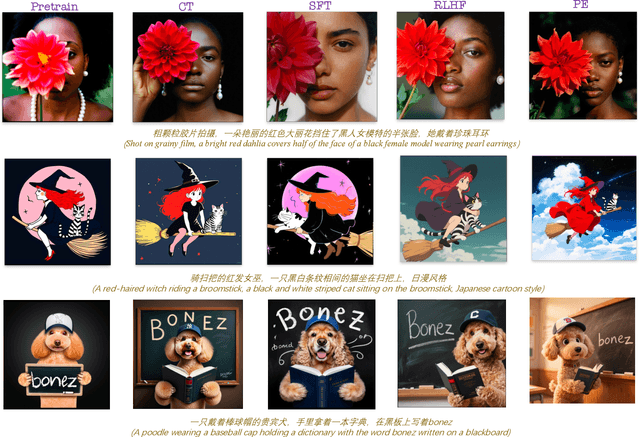
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
Attention Reveals More Than Tokens: Training-Free Long-Context Reasoning with Attention-guided Retrieval
Mar 12, 2025Large Language Models (LLMs) often exhibit substantially shorter effective context lengths than their claimed capacities, especially when handling complex reasoning tasks that require integrating information from multiple parts of a long context and performing multi-step reasoning. Although Chain-of-Thought (CoT) prompting has shown promise in reducing task complexity, our empirical analysis reveals that it does not fully resolve this limitation. Through controlled experiments, we identify poor recall of implicit facts as the primary cause of failure, which significantly hampers reasoning performance. Interestingly, we observe that the internal attention weights from the generated CoT tokens can effectively ground implicit facts, even when these facts are not explicitly recalled. Building on this insight, we propose a novel training-free algorithm, Attrieval, which leverages attention weights to retrieve relevant facts from the long context and incorporates them into the reasoning process. Additionally, we find that selecting context tokens from CoT tokens further improves performance. Our results demonstrate that Attrieval enhances long-context reasoning capability notably on both synthetic and real-world QA datasets with various models.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
Toward Multi-Session Personalized Conversation: A Large-Scale Dataset and Hierarchical Tree Framework for Implicit Reasoning
Mar 10, 2025There has been a surge in the use of large language models (LLM) conversational agents to generate responses based on long-term history from multiple sessions. However, existing long-term open-domain dialogue datasets lack complex, real-world personalization and fail to capture implicit reasoning-where relevant information is embedded in subtle, syntactic, or semantically distant connections rather than explicit statements. In such cases, traditional retrieval methods fail to capture relevant context, and long-context modeling also becomes inefficient due to numerous complicated persona-related details. To address this gap, we introduce ImplexConv, a large-scale long-term dataset with 2,500 examples, each containing approximately 100 conversation sessions, designed to study implicit reasoning in personalized dialogues. Additionally, we propose TaciTree, a novel hierarchical tree framework that structures conversation history into multiple levels of summarization. Instead of brute-force searching all data, TaciTree enables an efficient, level-based retrieval process where models refine their search by progressively selecting relevant details. Our experiments demonstrate that TaciTree significantly improves the ability of LLMs to reason over long-term conversations with implicit contextual dependencies.
Object Detection for Medical Image Analysis: Insights from the RT-DETR Model
Jan 27, 2025



Deep learning has emerged as a transformative approach for solving complex pattern recognition and object detection challenges. This paper focuses on the application of a novel detection framework based on the RT-DETR model for analyzing intricate image data, particularly in areas such as diabetic retinopathy detection. Diabetic retinopathy, a leading cause of vision loss globally, requires accurate and efficient image analysis to identify early-stage lesions. The proposed RT-DETR model, built on a Transformer-based architecture, excels at processing high-dimensional and complex visual data with enhanced robustness and accuracy. Comparative evaluations with models such as YOLOv5, YOLOv8, SSD, and DETR demonstrate that RT-DETR achieves superior performance across precision, recall, mAP50, and mAP50-95 metrics, particularly in detecting small-scale objects and densely packed targets. This study underscores the potential of Transformer-based models like RT-DETR for advancing object detection tasks, offering promising applications in medical imaging and beyond.