 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-stationary BERT: Exploring Augmented IMU Data For Robust Human Activity Recognition
Sep 25, 2024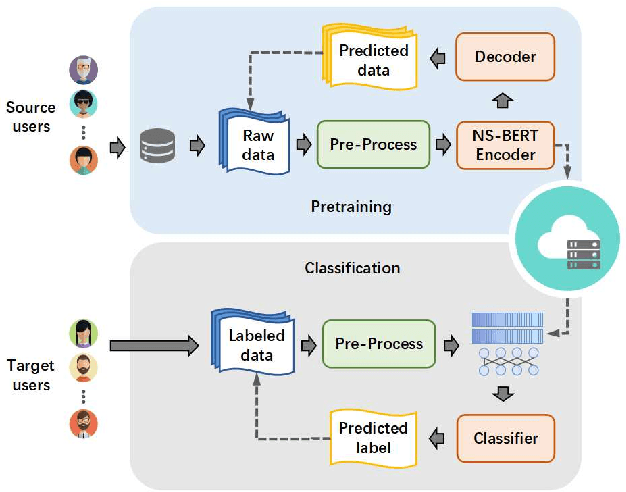
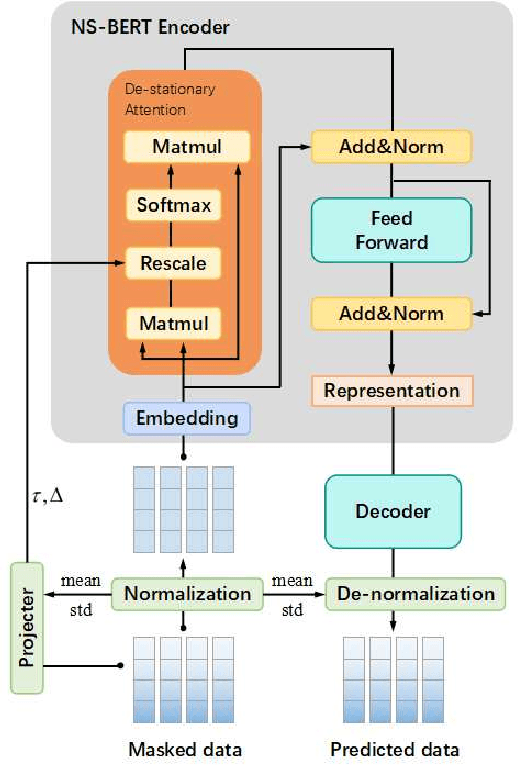
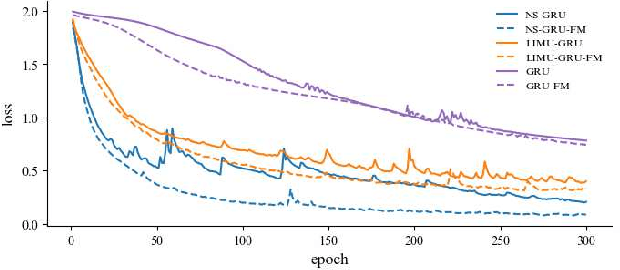

Human Activity Recognition (HAR) has gained great attention from researchers due to the popularity of mobile devices and the need to observe users' daily activity data for better human-computer interaction. In this work, we collect a human activity recognition dataset called OPPOHAR consisting of phone IMU data. To facilitate the employment of HAR system in mobile phone and to achieve user-specific activity recognition, we propose a novel light-weight network called Non-stationary BERT with a two-stage training method. We also propose a simple yet effective data augmentation method to explore the deeper relationship between the accelerator and gyroscope data from the IMU. The network achieves the state-of-the-art performance testing on various activity recognition datasets and the data augmentation method demonstrates its wide applicability.
Monocular Localization with Semantics Map for Autonomous Vehicles
Jun 06, 2024

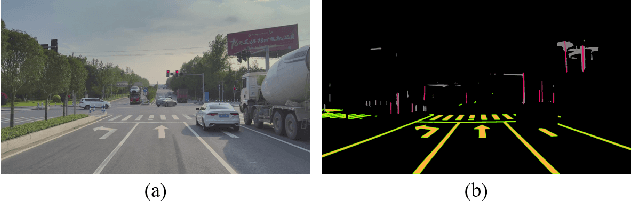
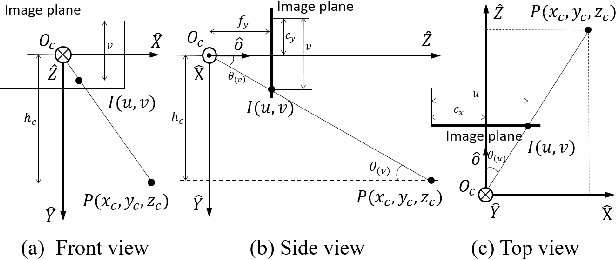
Accurate and robust localization remains a significant challenge for autonomous vehicles. The cost of sensors and limitations in local computational efficiency make it difficult to scale to large commercial applications. Traditional vision-based approaches focus on texture features that are susceptible to changes in lighting, season, perspective, and appearance. Additionally, the large storage size of maps with descriptors and complex optimization processes hinder system performance. To balance efficiency and accuracy, we propose a novel lightweight visual semantic localization algorithm that employs stable semantic features instead of low-level texture features. First, semantic maps are constructed offline by detecting semantic objects, such as ground markers, lane lines, and poles, using cameras or LiDAR sensors. Then, online visual localization is performed through data association of semantic features and map objects. We evaluated our proposed localization framework in the publicly available KAIST Urban dataset and in scenarios recorded by ourselves. The experimental results demonstrate that our method is a reliable and practical localization solution in various autonomous driving localization tasks.
SGL: Structure Guidance Learning for Camera Localization
Apr 12, 2023



Camera localization is a classical computer vision task that serves various Artificial Intelligence and Robotics applications. With the rapid developments of Deep Neural Networks (DNNs), end-to-end visual localization methods are prosperous in recent years. In this work, we focus on the scene coordinate prediction ones and propose a network architecture named as Structure Guidance Learning (SGL) which utilizes the receptive branch and the structure branch to extract both high-level and low-level features to estimate the 3D coordinates. We design a confidence strategy to refine and filter the predicted 3D observations, which enables us to estimate the camera poses by employing the Perspective-n-Point (PnP) with RANSAC. In the training part, we design the Bundle Adjustment trainer to help the network fit the scenes better. Comparisons with some state-of-the-art (SOTA) methods and sufficient ablation experiments confirm the validity of our proposed architecture.
A Real-Time Fusion Framework for Long-term Visual Localization
Oct 18, 2022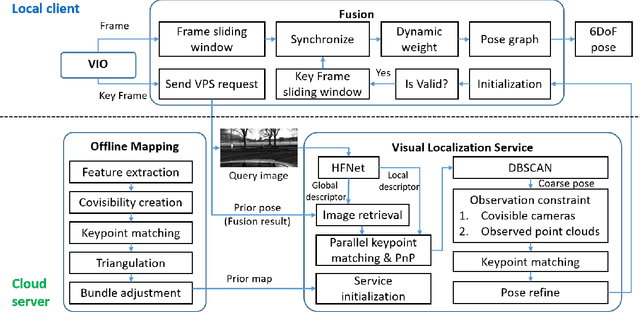
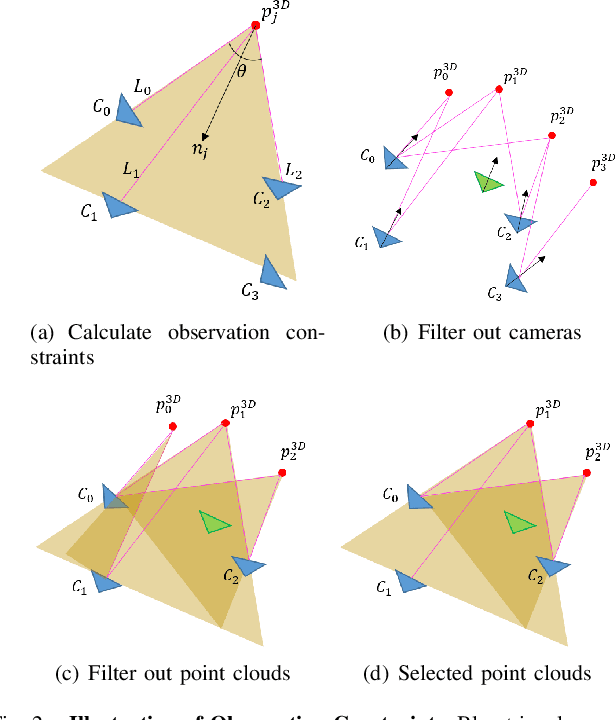
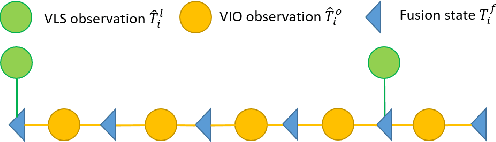
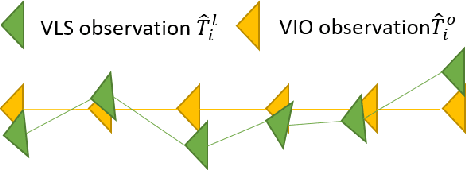
Visual localization is a fundamental task that regresses the 6 Degree Of Freedom (6DoF) poses with image features in order to serve the high precision localization requests in many robotics applications. Degenerate conditions like motion blur, illumination changes and environment variations place great challenges in this task. Fusion with additional information, such as sequential information and Inertial Measurement Unit (IMU) inputs, would greatly assist such problems. In this paper, we present an efficient client-server visual localization architecture that fuses global and local pose estimations to realize promising precision and efficiency. We include additional geometry hints in mapping and global pose regressing modules to improve the measurement quality. A loosely coupled fusion policy is adopted to leverage the computation complexity and accuracy. We conduct the evaluations on two typical open-source benchmarks, 4Seasons and OpenLORIS. Quantitative results prove that our framework has competitive performance with respect to other state-of-the-art visual localization solutions.
Pose Refinement with Joint Optimization of Visual Points and Lines
Oct 08, 2021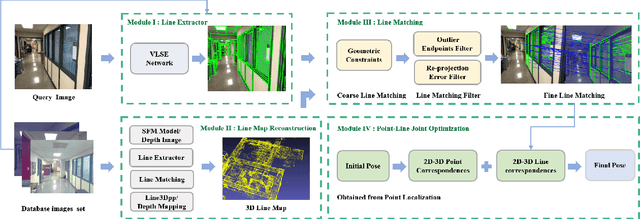
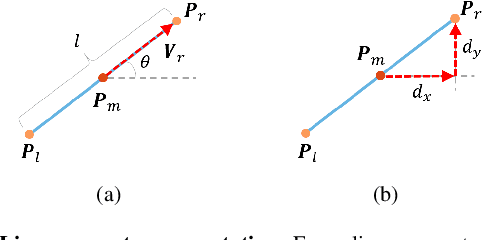
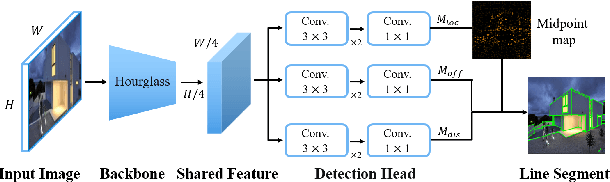
High-precision camera re-localization technology in a pre-established 3D environment map is the basis for many tasks, such as Augmented Reality, Robotics and Autonomous Driving. The point-based visual re-localization approaches are well-developed in recent decades, but are insufficient in some feature-less cases. In this paper, we propose a point-line joint optimization method for pose refinement with the help of the innovatively designed line extracting CNN named VLSE, and the line matching and pose optimization approach. We adopt a novel line representation and customize a hybrid convolutional block based on the Stacked Hourglass network, to detect accurate and stable line features on images. Then we apply a coarse-to-fine strategy to obtain precise 2D-3D line correspondences based on the geometric constraint. A following point-line joint cost function is constructed to optimize the camera pose with the initial coarse pose. Sufficient experiments are conducted on open datasets, i.e, line extractor on Wireframe and YorkUrban, localization performance on Aachen Day-Night v1.1 and InLoc, to confirm the effectiveness of our point-line joint pose optimization method.