 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Select: Exploring Label Distribution Divergence for In-Context Demonstration Selection in Text Classification
Nov 10, 2025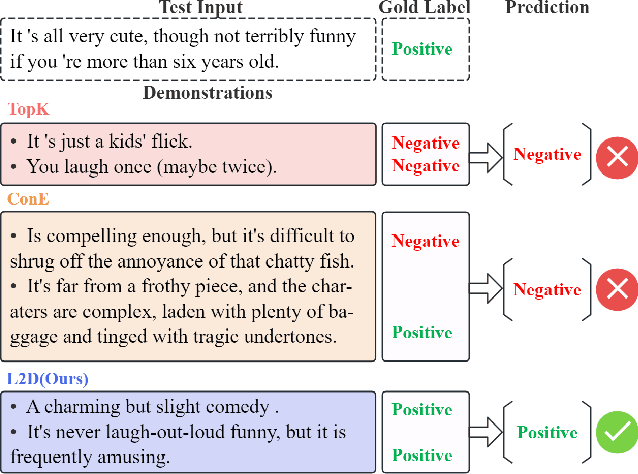
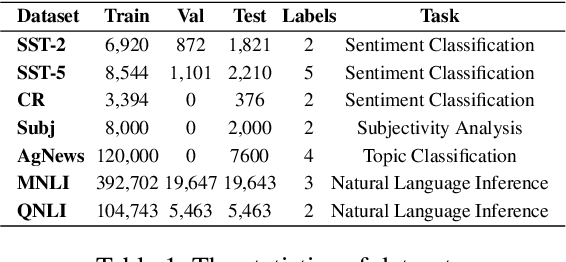
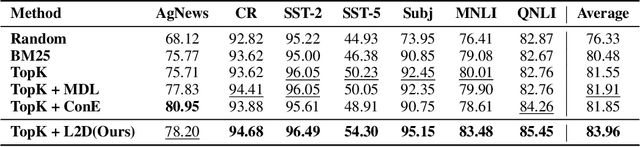
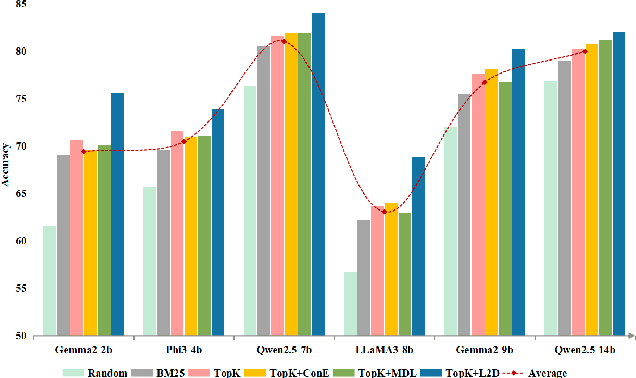
In-context learning (ICL) for text classification, which uses a few input-label demonstrations to describe a task, has demonstrated impressive performance on large language models (LLMs). However, the selection of in-context demonstrations plays a crucial role and can significantly affect LLMs' performance. Most existing demonstration selection methods primarily focus on semantic similarity between test inputs and demonstrations, often overlooking the importance of label distribution alignment. To address this limitation, we propose a two-stage demonstration selection method, TopK + Label Distribution Divergence (L2D), which leverages a fine-tuned BERT-like small language model (SLM) to generate label distributions and calculate their divergence for both test inputs and candidate demonstrations. This enables the selection of demonstrations that are not only semantically similar but also aligned in label distribution with the test input. Extensive experiments across seven text classification benchmarks show that our method consistently outperforms previous demonstration selection strategies. Further analysis reveals a positive correlation between the performance of LLMs and the accuracy of the underlying SLMs used for label distribution estimation.
AMPLE: Emotion-Aware Multimodal Fusion Prompt Learning for Fake News Detection
Oct 21, 2024Detecting fake news in large datasets is challenging due to its diversity and complexity, with traditional approaches often focusing on textual features while underutilizing semantic and emotional elements. Current methods also rely heavily on large annotated datasets, limiting their effectiveness in more nuanced analysis. To address these challenges, this paper introduces Emotion-\textbf{A}ware \textbf{M}ultimodal Fusion \textbf{P}rompt \textbf{L}\textbf{E}arning (\textbf{AMPLE}) framework to address the above issue by combining text sentiment analysis with multimodal data and hybrid prompt templates. This framework extracts emotional elements from texts by leveraging sentiment analysis tools. It then employs Multi-Head Cross-Attention (MCA) mechanisms and similarity-aware fusion methods to integrate multimodal data. The proposed AMPLE framework demonstrates strong performance on two public datasets in both few-shot and data-rich settings, with results indicating the potential of emotional aspects in fake news detection. Furthermore, the study explores the impact of integrating large language models with this method for text sentiment extraction, revealing substantial room for further improvement. The code can be found at :\url{https://github.com/xxm1215/MMM2025_few-shot/
Cross-Modal Augmentation for Few-Shot Multimodal Fake News Detection
Jul 16, 2024



The nascent topic of fake news requires automatic detection methods to quickly learn from limited annotated samples. Therefore, the capacity to rapidly acquire proficiency in a new task with limited guidance, also known as few-shot learning, is critical for detecting fake news in its early stages. Existing approaches either involve fine-tuning pre-trained language models which come with a large number of parameters, or training a complex neural network from scratch with large-scale annotated datasets. This paper presents a multimodal fake news detection model which augments multimodal features using unimodal features. For this purpose, we introduce Cross-Modal Augmentation (CMA), a simple approach for enhancing few-shot multimodal fake news detection by transforming n-shot classification into a more robust (n $\times$ z)-shot problem, where z represents the number of supplementary features. The proposed CMA achieves SOTA results over three benchmark datasets, utilizing a surprisingly simple linear probing method to classify multimodal fake news with only a few training samples. Furthermore, our method is significantly more lightweight than prior approaches, particularly in terms of the number of trainable parameters and epoch times. The code is available here: \url{https://github.com/zgjiangtoby/FND_fewshot}
Large Visual-Language Models Are Also Good Classifiers: A Study of In-Context Multimodal Fake News Detection
Jul 16, 2024



Large visual-language models (LVLMs) exhibit exceptional performance in visual-language reasoning across diverse cross-modal benchmarks. Despite these advances, recent research indicates that Large Language Models (LLMs), like GPT-3.5-turbo, underachieve compared to well-trained smaller models, such as BERT, in Fake News Detection (FND), prompting inquiries into LVLMs' efficacy in FND tasks. Although performance could improve through fine-tuning LVLMs, the substantial parameters and requisite pre-trained weights render it a resource-heavy endeavor for FND applications. This paper initially assesses the FND capabilities of two notable LVLMs, CogVLM and GPT4V, in comparison to a smaller yet adeptly trained CLIP model in a zero-shot context. The findings demonstrate that LVLMs can attain performance competitive with that of the smaller model. Next, we integrate standard in-context learning (ICL) with LVLMs, noting improvements in FND performance, though limited in scope and consistency. To address this, we introduce the \textbf{I}n-context \textbf{M}ultimodal \textbf{F}ake \textbf{N}ews \textbf{D}etection (IMFND) framework, enriching in-context examples and test inputs with predictions and corresponding probabilities from a well-trained smaller model. This strategic integration directs the LVLMs' focus towards news segments associated with higher probabilities, thereby improving their analytical accuracy. The experimental results suggest that the IMFND framework significantly boosts the FND efficiency of LVLMs, achieving enhanced accuracy over the standard ICL approach across three publicly available FND datasets.
Monocular Localization with Semantics Map for Autonomous Vehicles
Jun 06, 2024

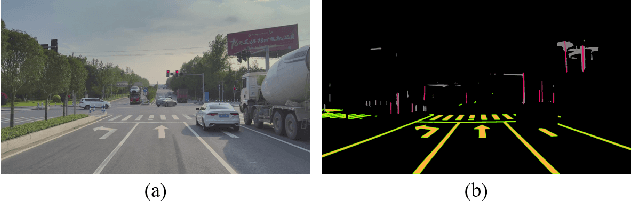
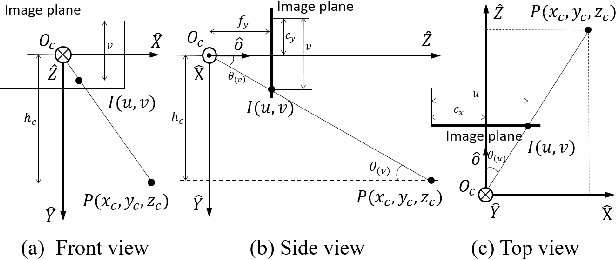
Accurate and robust localization remains a significant challenge for autonomous vehicles. The cost of sensors and limitations in local computational efficiency make it difficult to scale to large commercial applications. Traditional vision-based approaches focus on texture features that are susceptible to changes in lighting, season, perspective, and appearance. Additionally, the large storage size of maps with descriptors and complex optimization processes hinder system performance. To balance efficiency and accuracy, we propose a novel lightweight visual semantic localization algorithm that employs stable semantic features instead of low-level texture features. First, semantic maps are constructed offline by detecting semantic objects, such as ground markers, lane lines, and poles, using cameras or LiDAR sensors. Then, online visual localization is performed through data association of semantic features and map objects. We evaluated our proposed localization framework in the publicly available KAIST Urban dataset and in scenarios recorded by ourselves. The experimental results demonstrate that our method is a reliable and practical localization solution in various autonomous driving localization tasks.
Team QUST at SemEval-2024 Task 8: A Comprehensive Study of Monolingual and Multilingual Approaches for Detecting AI-generated Text
Feb 19, 2024



This paper presents the participation of team QUST in Task 8 SemEval 2024. We first performed data augmentation and cleaning on the dataset to enhance model training efficiency and accuracy. In the monolingual task, we evaluated traditional deep-learning methods, multiscale positive-unlabeled framework (MPU), fine-tuning, adapters and ensemble methods. Then, we selected the top-performing models based on their accuracy from the monolingual models and evaluated them in subtasks A and B. The final model construction employed a stacking ensemble that combined fine-tuning with MPU. Our system achieved 8th (scored 8th in terms of accuracy, officially ranked 13th) place in the official test set in multilingual settings of subtask A. We release our system code at:https://github.com/warmth27/SemEval2024_QUST
Similarity-Aware Multimodal Prompt Learning for Fake News Detection
Apr 20, 2023



The standard paradigm for fake news detection mainly utilizes text information to model the truthfulness of news. However, the discourse of online fake news is typically subtle and it requires expert knowledge to use textual information to debunk fake news. Recently, studies focusing on multimodal fake news detection have outperformed text-only methods. Recent approaches utilizing the pre-trained model to extract unimodal features, or fine-tuning the pre-trained model directly, have become a new paradigm for detecting fake news. Again, this paradigm either requires a large number of training instances, or updates the entire set of pre-trained model parameters, making real-world fake news detection impractical. Furthermore, traditional multimodal methods fuse the cross-modal features directly without considering that the uncorrelated semantic representation might inject noise into the multimodal features. This paper proposes a Similarity-Aware Multimodal Prompt Learning (SAMPLE) framework. First, we incorporate prompt learning into multimodal fake news detection. Prompt learning, which only tunes prompts with a frozen language model, can reduce memory usage significantly and achieve comparable performances, compared with fine-tuning. We analyse three prompt templates with a soft verbalizer to detect fake news. In addition, we introduce the similarity-aware fusing method to adaptively fuse the intensity of multimodal representation and mitigate the noise injection via uncorrelated cross-modal features. For evaluation, SAMPLE surpasses the F1 and the accuracies of previous works on two benchmark multimodal datasets, demonstrating the effectiveness of the proposed method in detecting fake news. In addition, SAMPLE also is superior to other approaches regardless of few-shot and data-rich settings.
A Large-Scale Comparative Study of Accurate COVID-19 Information versus Misinformation
Apr 10, 2023



The COVID-19 pandemic led to an infodemic where an overwhelming amount of COVID-19 related content was being disseminated at high velocity through social media. This made it challenging for citizens to differentiate between accurate and inaccurate information about COVID-19. This motivated us to carry out a comparative study of the characteristics of COVID-19 misinformation versus those of accurate COVID-19 information through a large-scale computational analysis of over 242 million tweets. The study makes comparisons alongside four key aspects: 1) the distribution of topics, 2) the live status of tweets, 3) language analysis and 4) the spreading power over time. An added contribution of this study is the creation of a COVID-19 misinformation classification dataset. Finally, we demonstrate that this new dataset helps improve misinformation classification by more than 9% based on average F1 measure.
Team QUST at SemEval-2023 Task 3: A Comprehensive Study of Monolingual and Multilingual Approaches for Detecting Online News Genre, Framing and Persuasion Techniques
Apr 09, 2023



This paper describes the participation of team QUST in the SemEval2023 task 3. The monolingual models are first evaluated with the under-sampling of the majority classes in the early stage of the task. Then, the pre-trained multilingual model is fine-tuned with a combination of the class weights and the sample weights. Two different fine-tuning strategies, the task-agnostic and the task-dependent, are further investigated. All experiments are conducted under the 10-fold cross-validation, the multilingual approaches are superior to the monolingual ones. The submitted system achieves the second best in Italian and Spanish (zero-shot) in subtask-1.
Categorising Fine-to-Coarse Grained Misinformation: An Empirical Study of COVID-19 Infodemic
Jul 08, 2021
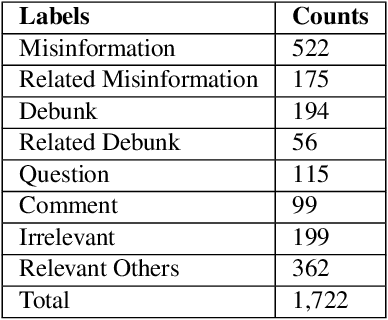
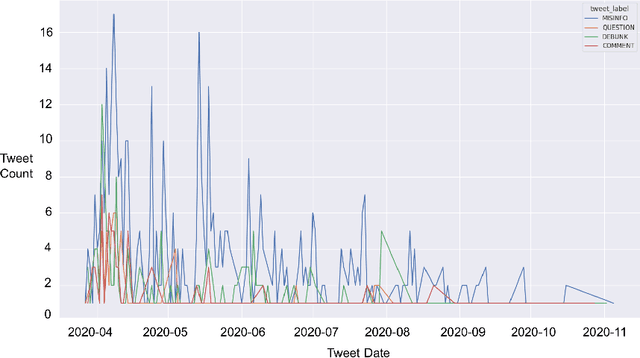
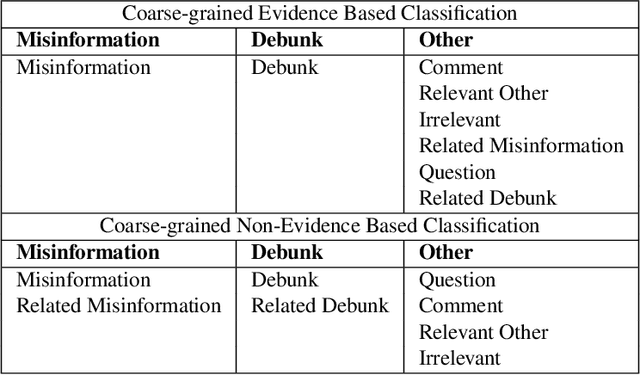
The spreading COVID-19 misinformation over social media already draws the attention of many researchers. According to Google Scholar, about 26000 COVID-19 related misinformation studies have been published to date. Most of these studies focusing on 1) detect and/or 2) analysing the characteristics of COVID-19 related misinformation. However, the study of the social behaviours related to misinformation is often neglected. In this paper, we introduce a fine-grained annotated misinformation tweets dataset including social behaviours annotation (e.g. comment or question to the misinformation). The dataset not only allows social behaviours analysis but also suitable for both evidence-based or non-evidence-based misinformation classification task. In addition, we introduce leave claim out validation in our experiments and demonstrate the misinformation classification performance could be significantly different when applying to real-world unseen misinformation.