 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLying Blindly: Bypassing ChatGPT's Safeguards to Generate Hard-to-Detect Disinformation Claims at Scale
Feb 13, 2024As Large Language Models (LLMs) become more proficient, their misuse in large-scale viral disinformation campaigns is a growing concern. This study explores the capability of ChatGPT to generate unconditioned claims about the war in Ukraine, an event beyond its knowledge cutoff, and evaluates whether such claims can be differentiated by human readers and automated tools from human-written ones. We compare war-related claims from ClaimReview, authored by IFCN-registered fact-checkers, and similar short-form content generated by ChatGPT. We demonstrate that ChatGPT can produce realistic, target-specific disinformation cheaply, fast, and at scale, and that these claims cannot be reliably distinguished by humans or existing automated tools.
Analysing State-Backed Propaganda Websites: a New Dataset and Linguistic Study
Oct 21, 2023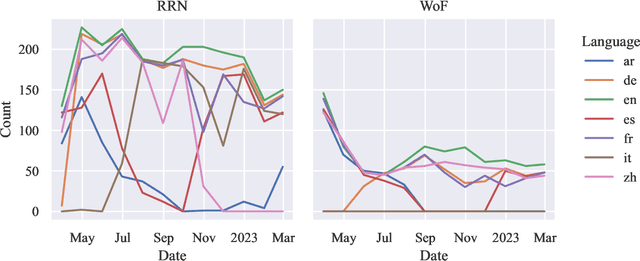
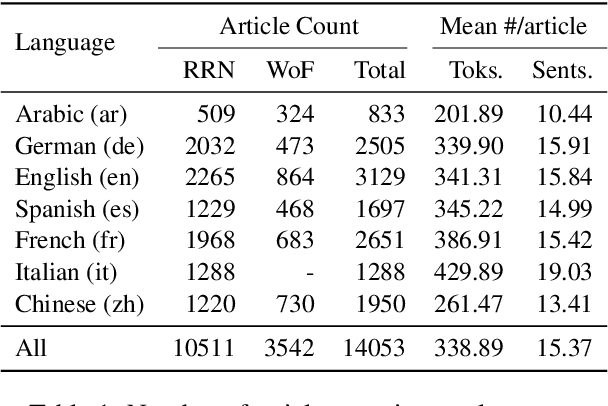


This paper analyses two hitherto unstudied sites sharing state-backed disinformation, Reliable Recent News (rrn.world) and WarOnFakes (waronfakes.com), which publish content in Arabic, Chinese, English, French, German, and Spanish. We describe our content acquisition methodology and perform cross-site unsupervised topic clustering on the resulting multilingual dataset. We also perform linguistic and temporal analysis of the web page translations and topics over time, and investigate articles with false publication dates. We make publicly available this new dataset of 14,053 articles, annotated with each language version, and additional metadata such as links and images. The main contribution of this paper for the NLP community is in the novel dataset which enables studies of disinformation networks, and the training of NLP tools for disinformation detection.
Comparison between parameter-efficient techniques and full fine-tuning: A case study on multilingual news article classification
Aug 14, 2023Adapters and Low-Rank Adaptation (LoRA) are parameter-efficient fine-tuning techniques designed to make the training of language models more efficient. Previous results demonstrated that these methods can even improve performance on some classification tasks. This paper complements the existing research by investigating how these techniques influence the classification performance and computation costs compared to full fine-tuning when applied to multilingual text classification tasks (genre, framing, and persuasion techniques detection; with different input lengths, number of predicted classes and classification difficulty), some of which have limited training data. In addition, we conduct in-depth analyses of their efficacy across different training scenarios (training on the original multilingual data; on the translations into English; and on a subset of English-only data) and different languages. Our findings provide valuable insights into the applicability of the parameter-efficient fine-tuning techniques, particularly to complex multilingual and multilabel classification tasks.
A Large-Scale Comparative Study of Accurate COVID-19 Information versus Misinformation
Apr 10, 2023



The COVID-19 pandemic led to an infodemic where an overwhelming amount of COVID-19 related content was being disseminated at high velocity through social media. This made it challenging for citizens to differentiate between accurate and inaccurate information about COVID-19. This motivated us to carry out a comparative study of the characteristics of COVID-19 misinformation versus those of accurate COVID-19 information through a large-scale computational analysis of over 242 million tweets. The study makes comparisons alongside four key aspects: 1) the distribution of topics, 2) the live status of tweets, 3) language analysis and 4) the spreading power over time. An added contribution of this study is the creation of a COVID-19 misinformation classification dataset. Finally, we demonstrate that this new dataset helps improve misinformation classification by more than 9% based on average F1 measure.
Team SheffieldVeraAI at SemEval-2023 Task 3: Mono and multilingual approaches for news genre, topic and persuasion technique classification
Mar 16, 2023



This paper describes our approach for SemEval-2023 Task 3: Detecting the category, the framing, and the persuasion techniques in online news in a multi-lingual setup. For Subtask 1 (News Genre), we propose an ensemble of fully trained and adapter mBERT models which was ranked joint-first for German, and had the highest mean rank of multi-language teams. For Subtask 2 (Framing), we achieved first place in 3 languages, and the best average rank across all the languages, by using two separate ensembles: a monolingual RoBERTa-MUPPETLARGE and an ensemble of XLM-RoBERTaLARGE with adapters and task adaptive pretraining. For Subtask 3 (Persuasion Techniques), we train a monolingual RoBERTa-Base model for English and a multilingual mBERT model for the remaining languages, which achieved top 10 for all languages, including 2nd for English. For each subtask, we compare monolingual and multilingual approaches, and consider class imbalance techniques.