 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Browser-based Open Source Assistant for Multimodal Content Verification
Mar 03, 2026Disinformation and false content produced by generative AI pose a significant challenge for journalists and fact-checkers who must rapidly verify digital media information. While there is an abundance of NLP models for detecting credibility signals such as persuasion techniques, subjectivity, or machine-generated text, such methods often remain inaccessible to non-expert users and are not integrated into their daily workflows as a unified framework. This paper demonstrates the VERIFICATION ASSISTANT, a browser-based tool designed to bridge this gap. The VERIFICATION ASSISTANT, a core component of the widely adopted VERIFICATION PLUGIN (140,000+ users), allows users to submit URLs or media files to a unified interface. It automatically extracts content and routes it to a suite of backend NLP classifiers, delivering actionable credibility signals, estimating AI-generated content, and providing other verification guidance in a clear, easy-to-digest format. This paper showcases the tool architecture, its integration of multiple NLP services, and its real-world application to detecting disinformation.
LLM-Based Adversarial Persuasion Attacks on Fact-Checking Systems
Jan 23, 2026Automated fact-checking (AFC) systems are susceptible to adversarial attacks, enabling false claims to evade detection. Existing adversarial frameworks typically rely on injecting noise or altering semantics, yet no existing framework exploits the adversarial potential of persuasion techniques, which are widely used in disinformation campaigns to manipulate audiences. In this paper, we introduce a novel class of persuasive adversarial attacks on AFCs by employing a generative LLM to rephrase claims using persuasion techniques. Considering 15 techniques grouped into 6 categories, we study the effects of persuasion on both claim verification and evidence retrieval using a decoupled evaluation strategy. Experiments on the FEVER and FEVEROUS benchmarks show that persuasion attacks can substantially degrade both verification performance and evidence retrieval. Our analysis identifies persuasion techniques as a potent class of adversarial attacks, highlighting the need for more robust AFC systems.
Truth with a Twist: The Rhetoric of Persuasion in Professional vs. Community-Authored Fact-Checks
Jan 20, 2026This study presents the first large-scale comparison of persuasion techniques present in crowd- versus professionally-written debunks. Using extensive datasets from Community Notes (CNs), EUvsDisinfo, and the Database of Known Fakes (DBKF), we quantify the prevalence and types of persuasion techniques across these fact-checking ecosystems. Contrary to prior hypothesis that community-produced debunks rely more heavily on subjective or persuasive wording, we find no evidence that CNs contain a higher average number of persuasion techniques than professional fact-checks. We additionally identify systematic rhetorical differences between CNs and professional debunking efforts, reflecting differences in institutional norms and topical coverage. Finally, we examine how the crowd evaluates persuasive language in CNs and show that, although notes with more persuasive elements receive slightly higher overall helpfulness ratings, crowd raters are effective at penalising the use of particular problematic rhetorical means
GateNLP at SemEval-2025 Task 10: Hierarchical Three-Step Prompting for Multilingual Narrative Classification
May 28, 2025The proliferation of online news and the increasing spread of misinformation necessitate robust methods for automatic data analysis. Narrative classification is emerging as a important task, since identifying what is being said online is critical for fact-checkers, policy markers and other professionals working on information studies. This paper presents our approach to SemEval 2025 Task 10 Subtask 2, which aims to classify news articles into a pre-defined two-level taxonomy of main narratives and sub-narratives across multiple languages. We propose Hierarchical Three-Step Prompting (H3Prompt) for multilingual narrative classification. Our methodology follows a three-step Large Language Model (LLM) prompting strategy, where the model first categorises an article into one of two domains (Ukraine-Russia War or Climate Change), then identifies the most relevant main narratives, and finally assigns sub-narratives. Our approach secured the top position on the English test set among 28 competing teams worldwide. The code is available at https://github.com/GateNLP/H3Prompt.
UKElectionNarratives: A Dataset of Misleading Narratives Surrounding Recent UK General Elections
May 08, 2025Misleading narratives play a crucial role in shaping public opinion during elections, as they can influence how voters perceive candidates and political parties. This entails the need to detect these narratives accurately. To address this, we introduce the first taxonomy of common misleading narratives that circulated during recent elections in Europe. Based on this taxonomy, we construct and analyse UKElectionNarratives: the first dataset of human-annotated misleading narratives which circulated during the UK General Elections in 2019 and 2024. We also benchmark Pre-trained and Large Language Models (focusing on GPT-4o), studying their effectiveness in detecting election-related misleading narratives. Finally, we discuss potential use cases and make recommendations for future research directions using the proposed codebook and dataset.
A Dataset for Analysing News Framing in Chinese Media
Mar 06, 2025



Framing is an essential device in news reporting, allowing the writer to influence public perceptions of current affairs. While there are existing automatic news framing detection datasets in various languages, none of them focus on news framing in the Chinese language which has complex character meanings and unique linguistic features. This study introduces the first Chinese News Framing dataset, to be used as either a stand-alone dataset or a supplementary resource to the SemEval-2023 task 3 dataset. We detail its creation and we run baseline experiments to highlight the need for such a dataset and create benchmarks for future research, providing results obtained through fine-tuning XLM-RoBERTa-Base and using GPT-4o in the zero-shot setting. We find that GPT-4o performs significantly worse than fine-tuned XLM-RoBERTa across all languages. For the Chinese language, we obtain an F1-micro (the performance metric for SemEval task 3, subtask 2) score of 0.719 using only samples from our Chinese News Framing dataset and a score of 0.753 when we augment the SemEval dataset with Chinese news framing samples. With positive news frame detection results, this dataset is a valuable resource for detecting news frames in the Chinese language and is a valuable supplement to the SemEval-2023 task 3 dataset.
A Cross-Domain Study of the Use of Persuasion Techniques in Online Disinformation
Dec 19, 2024Disinformation, irrespective of domain or language, aims to deceive or manipulate public opinion, typically through employing advanced persuasion techniques. Qualitative and quantitative research on the weaponisation of persuasion techniques in disinformation has been mostly topic-specific (e.g., COVID-19) with limited cross-domain studies, resulting in a lack of comprehensive understanding of these strategies. This study employs a state-of-the-art persuasion technique classifier to conduct a large-scale, multi-domain analysis of the role of 16 persuasion techniques in disinformation narratives. It shows how different persuasion techniques are employed disproportionately in different disinformation domains. We also include a detailed case study on climate change disinformation, highlighting how linguistic, psychological, and cultural factors shape the adaptation of persuasion strategies to fit unique thematic contexts.
Hostility Detection in UK Politics: A Dataset on Online Abuse Targeting MPs
Dec 05, 2024
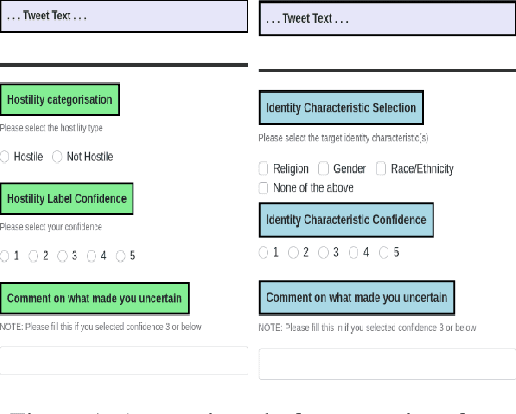
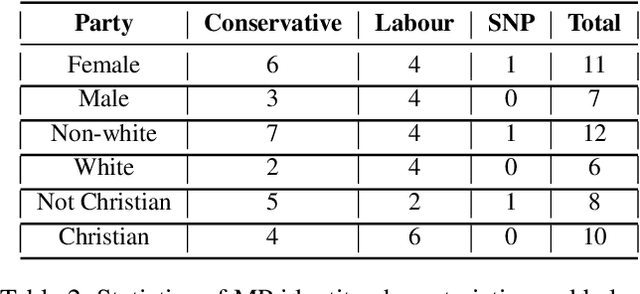
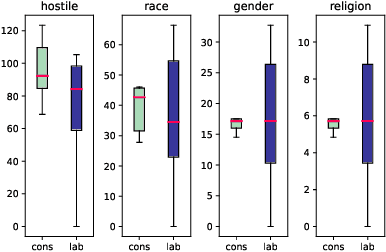
Numerous politicians use social media platforms, particularly X, to engage with their constituents. This interaction allows constituents to pose questions and offer feedback but also exposes politicians to a barrage of hostile responses, especially given the anonymity afforded by social media. They are typically targeted in relation to their governmental role, but the comments also tend to attack their personal identity. This can discredit politicians and reduce public trust in the government. It can also incite anger and disrespect, leading to offline harm and violence. While numerous models exist for detecting hostility in general, they lack the specificity required for political contexts. Furthermore, addressing hostility towards politicians demands tailored approaches due to the distinct language and issues inherent to each country (e.g., Brexit for the UK). To bridge this gap, we construct a dataset of 3,320 English tweets spanning a two-year period manually annotated for hostility towards UK MPs. Our dataset also captures the targeted identity characteristics (race, gender, religion, none) in hostile tweets. We perform linguistic and topical analyses to delve into the unique content of the UK political data. Finally, we evaluate the performance of pre-trained language models and large language models on binary hostility detection and multi-class targeted identity type classification tasks. Our study offers valuable data and insights for future research on the prevalence and nature of politics-related hostility specific to the UK.
A Survey on Automatic Credibility Assessment of Textual Credibility Signals in the Era of Large Language Models
Oct 28, 2024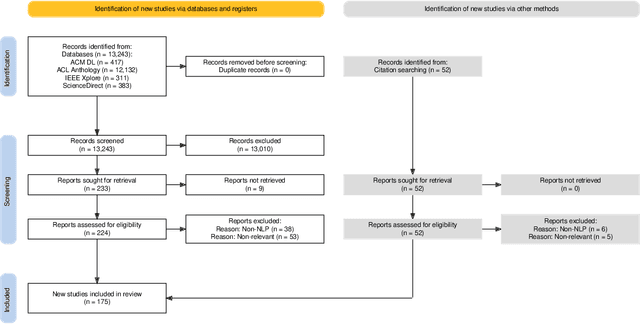
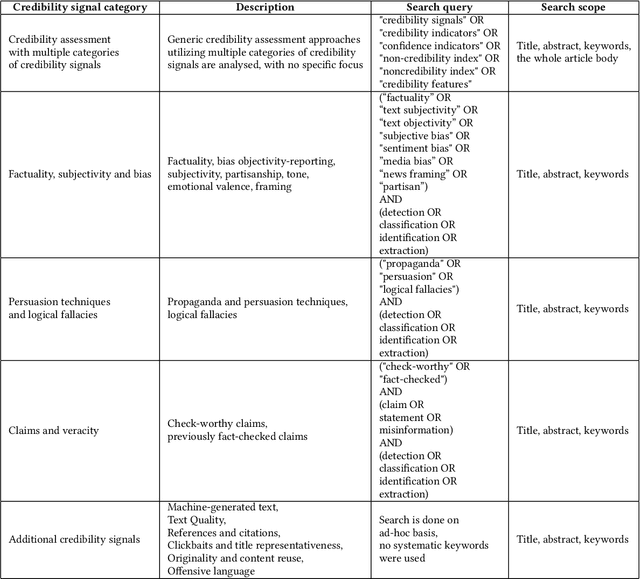
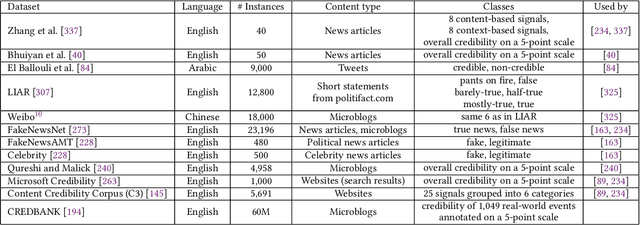
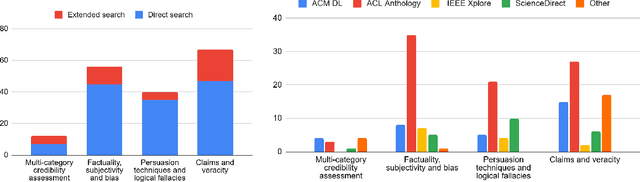
In the current era of social media and generative AI, an ability to automatically assess the credibility of online social media content is of tremendous importance. Credibility assessment is fundamentally based on aggregating credibility signals, which refer to small units of information, such as content factuality, bias, or a presence of persuasion techniques, into an overall credibility score. Credibility signals provide a more granular, more easily explainable and widely utilizable information in contrast to currently predominant fake news detection, which utilizes various (mostly latent) features. A growing body of research on automatic credibility assessment and detection of credibility signals can be characterized as highly fragmented and lacking mutual interconnections. This issue is even more prominent due to a lack of an up-to-date overview of research works on automatic credibility assessment. In this survey, we provide such systematic and comprehensive literature review of 175 research papers while focusing on textual credibility signals and Natural Language Processing (NLP), which undergoes a significant advancement due to Large Language Models (LLMs). While positioning the NLP research into the context of other multidisciplinary research works, we tackle with approaches for credibility assessment as well as with 9 categories of credibility signals (we provide a thorough analysis for 3 of them, namely: 1) factuality, subjectivity and bias, 2) persuasion techniques and logical fallacies, and 3) claims and veracity). Following the description of the existing methods, datasets and tools, we identify future challenges and opportunities, while paying a specific attention to recent rapid development of generative AI.
EUvsDisinfo: a Dataset for Multilingual Detection of Pro-Kremlin Disinformation in News Articles
Jun 18, 2024



This work introduces EUvsDisinfo, a multilingual dataset of trustworthy and disinformation articles related to pro-Kremlin themes. It is sourced directly from the debunk articles written by experts leading the EUvsDisinfo project. Our dataset is the largest to-date resource in terms of the overall number of articles and distinct languages. It also provides the largest topical and temporal coverage. Using this dataset, we investigate the dissemination of pro-Kremlin disinformation across different languages, uncovering language-specific patterns targeting specific disinformation topics. We further analyse the evolution of topic distribution over an eight-year period, noting a significant surge in disinformation content before the full-scale invasion of Ukraine in 2022. Lastly, we demonstrate the dataset's applicability in training models to effectively distinguish between disinformation and trustworthy content in multilingual settings.