 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Automatic Credibility Assessment of Textual Credibility Signals in the Era of Large Language Models
Oct 28, 2024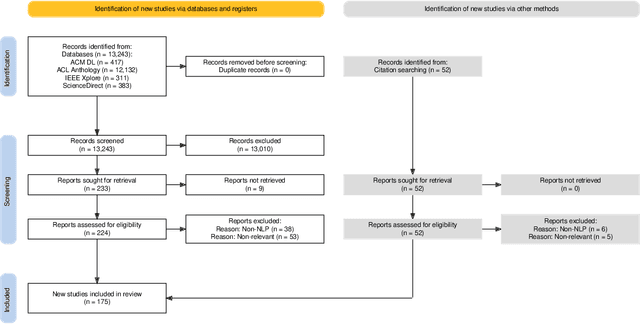
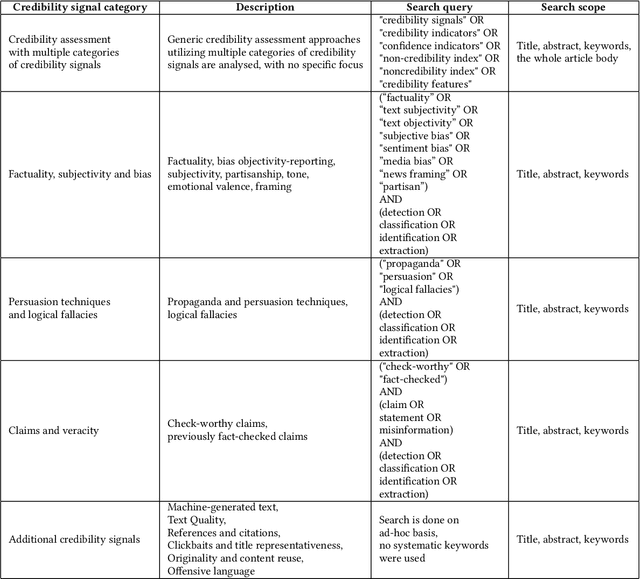
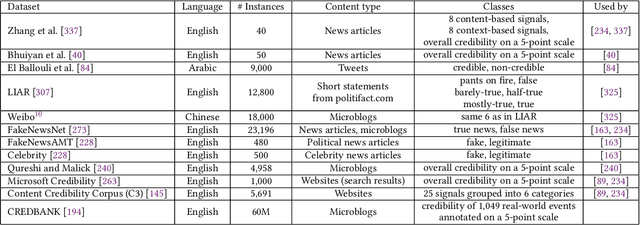
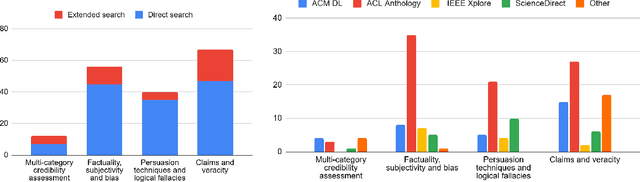
In the current era of social media and generative AI, an ability to automatically assess the credibility of online social media content is of tremendous importance. Credibility assessment is fundamentally based on aggregating credibility signals, which refer to small units of information, such as content factuality, bias, or a presence of persuasion techniques, into an overall credibility score. Credibility signals provide a more granular, more easily explainable and widely utilizable information in contrast to currently predominant fake news detection, which utilizes various (mostly latent) features. A growing body of research on automatic credibility assessment and detection of credibility signals can be characterized as highly fragmented and lacking mutual interconnections. This issue is even more prominent due to a lack of an up-to-date overview of research works on automatic credibility assessment. In this survey, we provide such systematic and comprehensive literature review of 175 research papers while focusing on textual credibility signals and Natural Language Processing (NLP), which undergoes a significant advancement due to Large Language Models (LLMs). While positioning the NLP research into the context of other multidisciplinary research works, we tackle with approaches for credibility assessment as well as with 9 categories of credibility signals (we provide a thorough analysis for 3 of them, namely: 1) factuality, subjectivity and bias, 2) persuasion techniques and logical fallacies, and 3) claims and veracity). Following the description of the existing methods, datasets and tools, we identify future challenges and opportunities, while paying a specific attention to recent rapid development of generative AI.
Evolution of Detection Performance throughout the Online Lifespan of Synthetic Images
Aug 21, 2024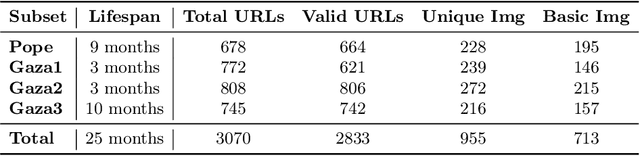



Synthetic images disseminated online significantly differ from those used during the training and evaluation of the state-of-the-art detectors. In this work, we analyze the performance of synthetic image detectors as deceptive synthetic images evolve throughout their online lifespan. Our study reveals that, despite advancements in the field, current state-of-the-art detectors struggle to distinguish between synthetic and real images in the wild. Moreover, we show that the time elapsed since the initial online appearance of a synthetic image negatively affects the performance of most detectors. Ultimately, by employing a retrieval-assisted detection approach, we demonstrate the feasibility to maintain initial detection performance throughout the whole online lifespan of an image and enhance the average detection efficacy across several state-of-the-art detectors by 6.7% and 7.8% for balanced accuracy and AUC metrics, respectively.
The MeVer DeepFake Detection Service: Lessons Learnt from Developing and Deploying in the Wild
Apr 27, 2022
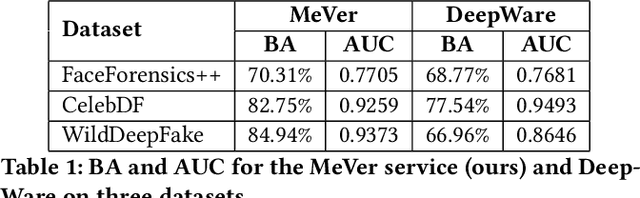
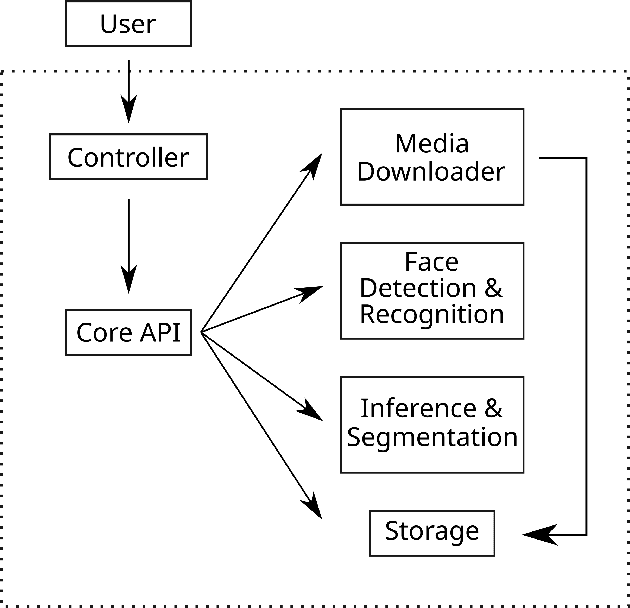
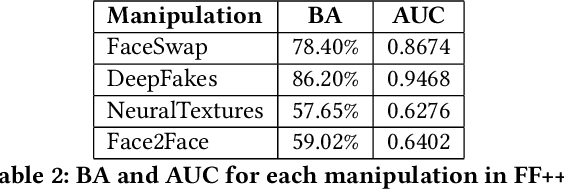
Enabled by recent improvements in generation methodologies, DeepFakes have become mainstream due to their increasingly better visual quality, the increase in easy-to-use generation tools and the rapid dissemination through social media. This fact poses a severe threat to our societies with the potential to erode social cohesion and influence our democracies. To mitigate the threat, numerous DeepFake detection schemes have been introduced in the literature but very few provide a web service that can be used in the wild. In this paper, we introduce the MeVer DeepFake detection service, a web service detecting deep learning manipulations in images and video. We present the design and implementation of the proposed processing pipeline that involves a model ensemble scheme, and we endow the service with a model card for transparency. Experimental results show that our service performs robustly on the three benchmark datasets while being vulnerable to Adversarial Attacks. Finally, we outline our experience and lessons learned when deploying a research system into production in the hopes that it will be useful to other academic and industry teams.
Searching News Articles Using an Event Knowledge Graph Leveraged by Wikidata
Apr 11, 2019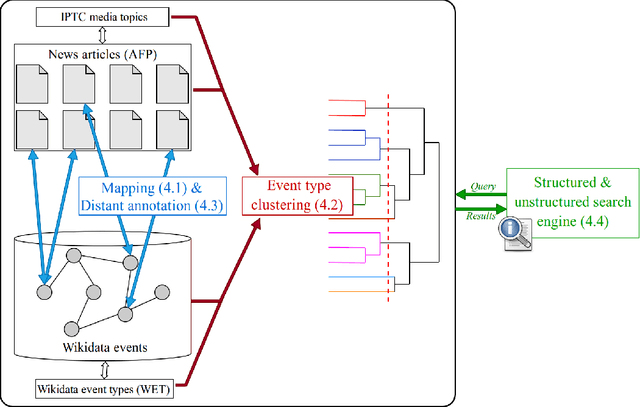
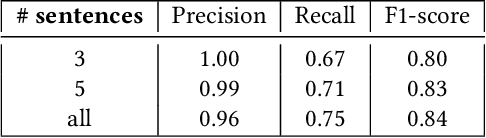
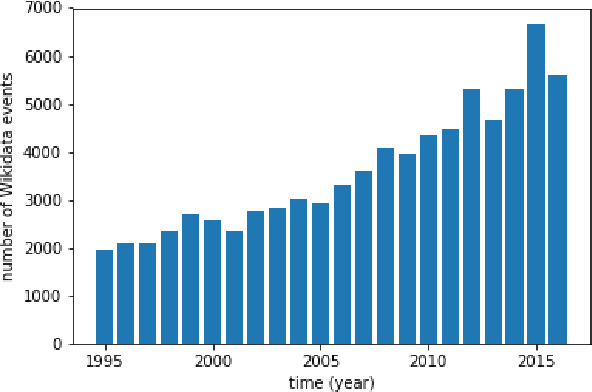

News agencies produce thousands of multimedia stories describing events happening in the world that are either scheduled such as sports competitions, political summits and elections, or breaking events such as military conflicts, terrorist attacks, natural disasters, etc. When writing up those stories, journalists refer to contextual background and to compare with past similar events. However, searching for precise facts described in stories is hard. In this paper, we propose a general method that leverages the Wikidata knowledge base to produce semantic annotations of news articles. Next, we describe a semantic search engine that supports both keyword based search in news articles and structured data search providing filters for properties belonging to specific event schemas that are automatically inferred.