 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleCap: Improving VLMs Captioning Performance via Self-Supervised Cycle Consistency Fine-Tuning
Mar 18, 2026Visual-Language Models (VLMs) have achieved remarkable progress in image captioning, visual question answering, and visual reasoning. Yet they remain prone to vision-language misalignment, often producing overly generic or hallucinated descriptions. Existing approaches address this via instruction tuning-requiring costly, large-scale annotated datasets or via complex test-time frameworks for caption refinement. In this work, we revisit image-text alignment through the lens of cycle consistency: given an image and a caption generated by an image-to-text model, the backward mapping through a text-to-image model should reconstruct an image that closely matches the original. In our setup, a VLM serves as the image-to-text component, while a pre-trained text-to-image model closes the loop by reconstructing the image from the generated caption. Building on this, we introduce CycleCap, a fine-tuning scheme to improve image captioning using Group Relative Policy Optimization (GRPO) with a reward based on the similarity between the original and reconstructed images, computed on-the-fly. Unlike previous work that uses cycle consistency loss for preference dataset construction, our method leverages cycle consistency directly as a self-supervised training signal. This enables the use of raw images alone, eliminating the need for curated image-text datasets, while steering the VLM to produce more accurate and grounded text descriptions. Applied to four VLMs ranging from 1B to 7B parameters, CycleCap yields consistent improvements across captioning and hallucination benchmarks, surpassing state-of-the-art methods that rely on supervised cycle consistency training.
Utilizing Large Language Models for Machine Learning Explainability
Oct 08, 2025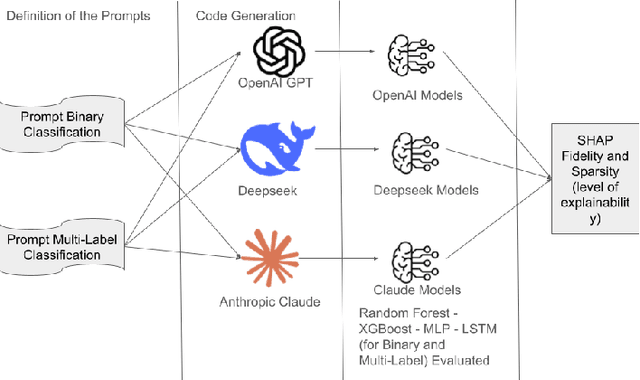
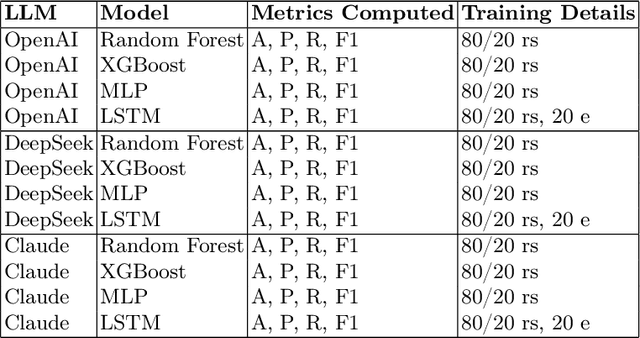
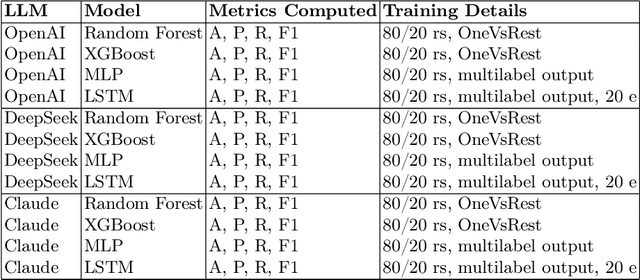
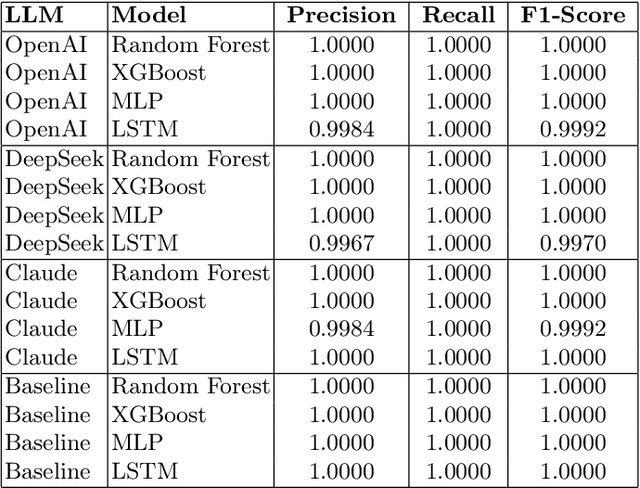
This study explores the explainability capabilities of large language models (LLMs), when employed to autonomously generate machine learning (ML) solutions. We examine two classification tasks: (i) a binary classification problem focused on predicting driver alertness states, and (ii) a multilabel classification problem based on the yeast dataset. Three state-of-the-art LLMs (i.e. OpenAI GPT, Anthropic Claude, and DeepSeek) are prompted to design training pipelines for four common classifiers: Random Forest, XGBoost, Multilayer Perceptron, and Long Short-Term Memory networks. The generated models are evaluated in terms of predictive performance (recall, precision, and F1-score) and explainability using SHAP (SHapley Additive exPlanations). Specifically, we measure Average SHAP Fidelity (Mean Squared Error between SHAP approximations and model outputs) and Average SHAP Sparsity (number of features deemed influential). The results reveal that LLMs are capable of producing effective and interpretable models, achieving high fidelity and consistent sparsity, highlighting their potential as automated tools for interpretable ML pipeline generation. The results show that LLMs can produce effective, interpretable pipelines with high fidelity and consistent sparsity, closely matching manually engineered baselines.
Few-Shot Class-Incremental Learning For Efficient SAR Automatic Target Recognition
May 26, 2025Synthetic aperture radar automatic target recognition (SAR-ATR) systems have rapidly evolved to tackle incremental recognition challenges in operational settings. Data scarcity remains a major hurdle that conventional SAR-ATR techniques struggle to address. To cope with this challenge, we propose a few-shot class-incremental learning (FSCIL) framework based on a dual-branch architecture that focuses on local feature extraction and leverages the discrete Fourier transform and global filters to capture long-term spatial dependencies. This incorporates a lightweight cross-attention mechanism that fuses domain-specific features with global dependencies to ensure robust feature interaction, while maintaining computational efficiency by introducing minimal scale-shift parameters. The framework combines focal loss for class distinction under imbalance and center loss for compact intra-class distributions to enhance class separation boundaries. Experimental results on the MSTAR benchmark dataset demonstrate that the proposed framework consistently outperforms state-of-the-art methods in FSCIL SAR-ATR, attesting to its effectiveness in real-world scenarios.
A Brief Review for Compression and Transfer Learning Techniques in DeepFake Detection
Apr 29, 2025Training and deploying deepfake detection models on edge devices offers the advantage of maintaining data privacy and confidentiality by processing it close to its source. However, this approach is constrained by the limited computational and memory resources available at the edge. To address this challenge, we explore compression techniques to reduce computational demands and inference time, alongside transfer learning methods to minimize training overhead. Using the Synthbuster, RAISE, and ForenSynths datasets, we evaluate the effectiveness of pruning, knowledge distillation (KD), quantization, fine-tuning, and adapter-based techniques. Our experimental results demonstrate that both compression and transfer learning can be effectively achieved, even with a high compression level of 90%, remaining at the same performance level when the training and validation data originate from the same DeepFake model. However, when the testing dataset is generated by DeepFake models not present in the training set, a domain generalization issue becomes evident.
Reducing Inference Energy Consumption Using Dual Complementary CNNs
Dec 02, 2024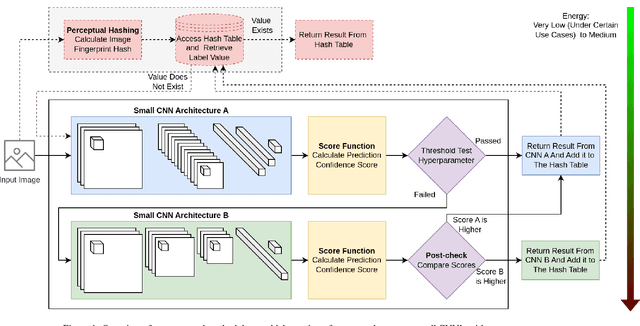
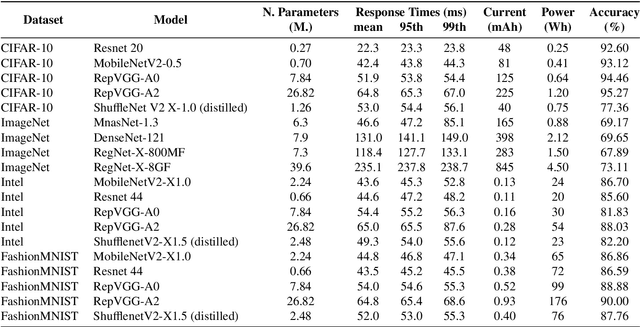
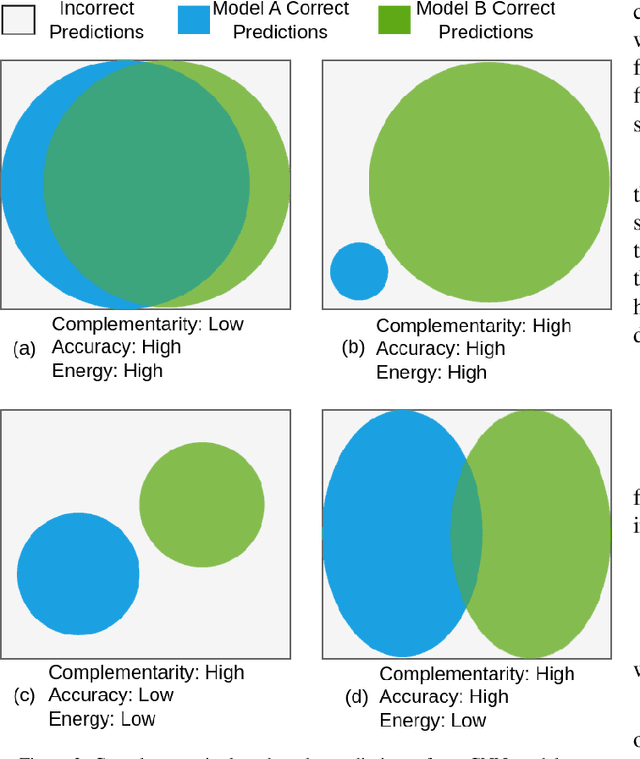
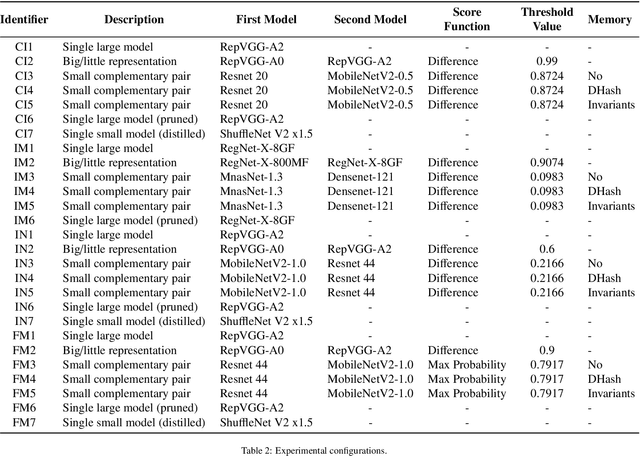
Energy efficiency of Convolutional Neural Networks (CNNs) has become an important area of research, with various strategies being developed to minimize the power consumption of these models. Previous efforts, including techniques like model pruning, quantization, and hardware optimization, have made significant strides in this direction. However, there remains a need for more effective on device AI solutions that balance energy efficiency with model performance. In this paper, we propose a novel approach to reduce the energy requirements of inference of CNNs. Our methodology employs two small Complementary CNNs that collaborate with each other by covering each other's "weaknesses" in predictions. If the confidence for a prediction of the first CNN is considered low, the second CNN is invoked with the aim of producing a higher confidence prediction. This dual-CNN setup significantly reduces energy consumption compared to using a single large deep CNN. Additionally, we propose a memory component that retains previous classifications for identical inputs, bypassing the need to re-invoke the CNNs for the same input, further saving energy. Our experiments on a Jetson Nano computer demonstrate an energy reduction of up to 85.8% achieved on modified datasets where each sample was duplicated once. These findings indicate that leveraging a complementary CNN pair along with a memory component effectively reduces inference energy while maintaining high accuracy.
Any-Resolution AI-Generated Image Detection by Spectral Learning
Nov 28, 2024



Recent works have established that AI models introduce spectral artifacts into generated images and propose approaches for learning to capture them using labeled data. However, the significant differences in such artifacts among different generative models hinder these approaches from generalizing to generators not seen during training. In this work, we build upon the key idea that the spectral distribution of real images constitutes both an invariant and highly discriminative pattern for AI-generated image detection. To model this under a self-supervised setup, we employ masked spectral learning using the pretext task of frequency reconstruction. Since generated images constitute out-of-distribution samples for this model, we propose spectral reconstruction similarity to capture this divergence. Moreover, we introduce spectral context attention, which enables our approach to efficiently capture subtle spectral inconsistencies in images of any resolution. Our spectral AI-generated image detection approach (SPAI) achieves a 5.5% absolute improvement in AUC over the previous state-of-the-art across 13 recent generative approaches, while exhibiting robustness against common online perturbations.
A Multi-Task Text Classification Pipeline with Natural Language Explanations: A User-Centric Evaluation in Sentiment Analysis and Offensive Language Identification in Greek Tweets
Oct 14, 2024



Interpretability is a topic that has been in the spotlight for the past few years. Most existing interpretability techniques produce interpretations in the form of rules or feature importance. These interpretations, while informative, may be harder to understand for non-expert users and therefore, cannot always be considered as adequate explanations. To that end, explanations in natural language are often preferred, as they are easier to comprehend and also more presentable to end-users. This work introduces an early concept for a novel pipeline that can be used in text classification tasks, offering predictions and explanations in natural language. It comprises of two models: a classifier for labelling the text and an explanation generator which provides the explanation. The proposed pipeline can be adopted by any text classification task, given that ground truth rationales are available to train the explanation generator. Our experiments are centred around the tasks of sentiment analysis and offensive language identification in Greek tweets, using a Greek Large Language Model (LLM) to obtain the necessary explanations that can act as rationales. The experimental evaluation was performed through a user study based on three different metrics and achieved promising results for both datasets.
Sum of Group Error Differences: A Critical Examination of Bias Evaluation in Biometric Verification and a Dual-Metric Measure
Apr 23, 2024Biometric Verification (BV) systems often exhibit accuracy disparities across different demographic groups, leading to biases in BV applications. Assessing and quantifying these biases is essential for ensuring the fairness of BV systems. However, existing bias evaluation metrics in BV have limitations, such as focusing exclusively on match or non-match error rates, overlooking bias on demographic groups with performance levels falling between the best and worst performance levels, and neglecting the magnitude of the bias present. This paper presents an in-depth analysis of the limitations of current bias evaluation metrics in BV and, through experimental analysis, demonstrates their contextual suitability, merits, and limitations. Additionally, it introduces a novel general-purpose bias evaluation measure for BV, the ``Sum of Group Error Differences (SEDG)''. Our experimental results on controlled synthetic datasets demonstrate the effectiveness of demographic bias quantification when using existing metrics and our own proposed measure. We discuss the applicability of the bias evaluation metrics in a set of simulated demographic bias scenarios and provide scenario-based metric recommendations. Our code is publicly available under \url{https://github.com/alaaobeid/SEDG}.
User Identity Linkage in Social Media Using Linguistic and Social Interaction Features
Aug 22, 2023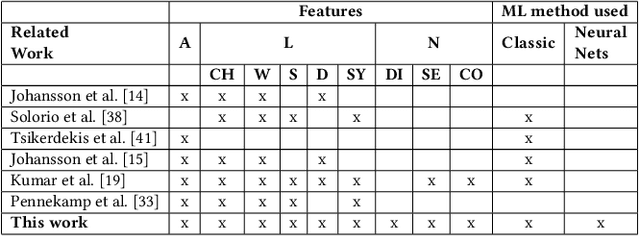
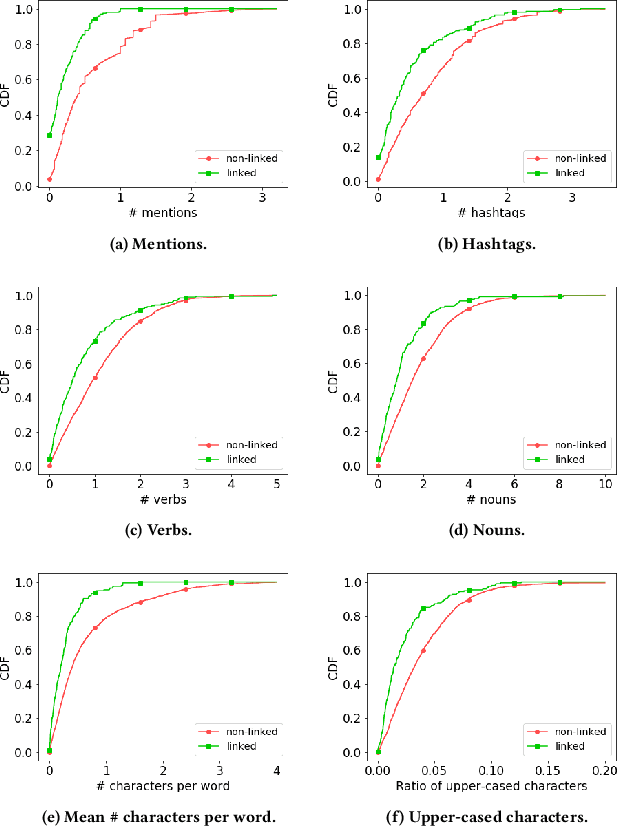
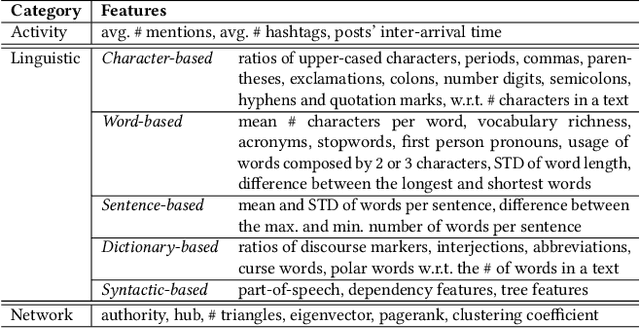
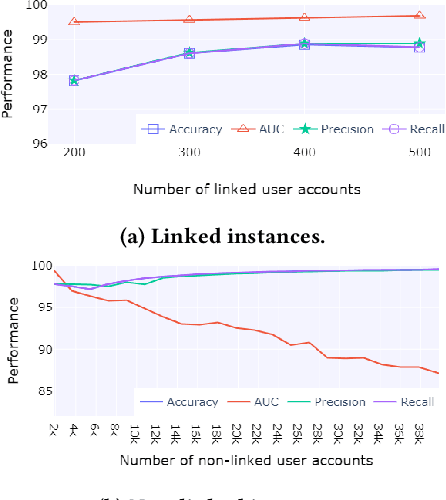
Social media users often hold several accounts in their effort to multiply the spread of their thoughts, ideas, and viewpoints. In the particular case of objectionable content, users tend to create multiple accounts to bypass the combating measures enforced by social media platforms and thus retain their online identity even if some of their accounts are suspended. User identity linkage aims to reveal social media accounts likely to belong to the same natural person so as to prevent the spread of abusive/illegal activities. To this end, this work proposes a machine learning-based detection model, which uses multiple attributes of users' online activity in order to identify whether two or more virtual identities belong to the same real natural person. The models efficacy is demonstrated on two cases on abusive and terrorism-related Twitter content.
AI and Non AI Assessments for Dementia
Jun 30, 2023



Current progress in the artificial intelligence domain has led to the development of various types of AI-powered dementia assessments, which can be employed to identify patients at the early stage of dementia. It can revolutionize the dementia care settings. It is essential that the medical community be aware of various AI assessments and choose them considering their degrees of validity, efficiency, practicality, reliability, and accuracy concerning the early identification of patients with dementia (PwD). On the other hand, AI developers should be informed about various non-AI assessments as well as recently developed AI assessments. Thus, this paper, which can be readable by both clinicians and AI engineers, fills the gap in the literature in explaining the existing solutions for the recognition of dementia to clinicians, as well as the techniques used and the most widespread dementia datasets to AI engineers. It follows a review of papers on AI and non-AI assessments for dementia to provide valuable information about various dementia assessments for both the AI and medical communities. The discussion and conclusion highlight the most prominent research directions and the maturity of existing solutions.