 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELViS: Efficient Visual Similarity from Local Descriptors that Generalizes Across Domains
Mar 30, 2026Large-scale instance-level training data is scarce, so models are typically trained on domain-specific datasets. Yet in real-world retrieval, they must handle diverse domains, making generalization to unseen data critical. We introduce ELViS, an image-to-image similarity model that generalizes effectively to unseen domains. Unlike conventional approaches, our model operates in similarity space rather than representation space, promoting cross-domain transfer. It leverages local descriptor correspondences, refines their similarities through an optimal transport step with data-dependent gains that suppress uninformative descriptors, and aggregates strong correspondences via a voting process into an image-level similarity. This design injects strong inductive biases, yielding a simple, efficient, and interpretable model. To assess generalization, we compile a benchmark of eight datasets spanning landmarks, artworks, products, and multi-domain collections, and evaluate ELViS as a re-ranking method. Our experiments show that ELViS outperforms competing methods by a large margin in out-of-domain scenarios and on average, while requiring only a fraction of their computational cost. Code available at: https://github.com/pavelsuma/ELViS/
LOCORE: Image Re-ranking with Long-Context Sequence Modeling
Mar 27, 2025We introduce LOCORE, Long-Context Re-ranker, a model that takes as input local descriptors corresponding to an image query and a list of gallery images and outputs similarity scores between the query and each gallery image. This model is used for image retrieval, where typically a first ranking is performed with an efficient similarity measure, and then a shortlist of top-ranked images is re-ranked based on a more fine-grained similarity measure. Compared to existing methods that perform pair-wise similarity estimation with local descriptors or list-wise re-ranking with global descriptors, LOCORE is the first method to perform list-wise re-ranking with local descriptors. To achieve this, we leverage efficient long-context sequence models to effectively capture the dependencies between query and gallery images at the local-descriptor level. During testing, we process long shortlists with a sliding window strategy that is tailored to overcome the context size limitations of sequence models. Our approach achieves superior performance compared with other re-rankers on established image retrieval benchmarks of landmarks (ROxf and RPar), products (SOP), fashion items (In-Shop), and bird species (CUB-200) while having comparable latency to the pair-wise local descriptor re-rankers.
ILIAS: Instance-Level Image retrieval At Scale
Feb 17, 2025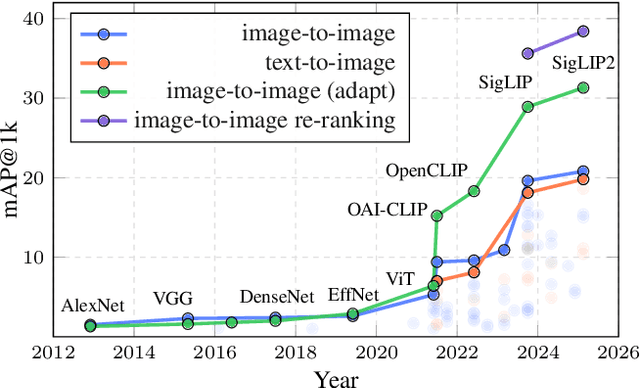
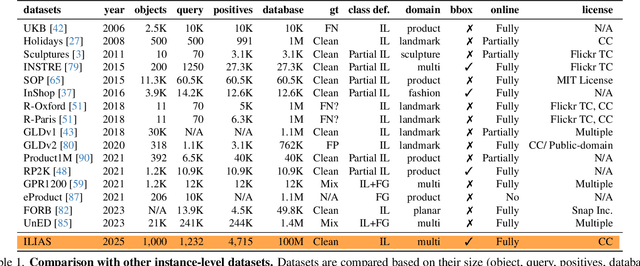

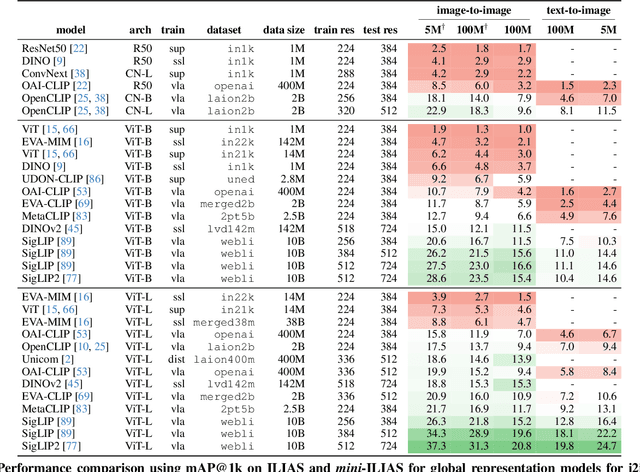
This work introduces ILIAS, a new test dataset for Instance-Level Image retrieval At Scale. It is designed to evaluate the ability of current and future foundation models and retrieval techniques to recognize particular objects. The key benefits over existing datasets include large scale, domain diversity, accurate ground truth, and a performance that is far from saturated. ILIAS includes query and positive images for 1,000 object instances, manually collected to capture challenging conditions and diverse domains. Large-scale retrieval is conducted against 100 million distractor images from YFCC100M. To avoid false negatives without extra annotation effort, we include only query objects confirmed to have emerged after 2014, i.e. the compilation date of YFCC100M. An extensive benchmarking is performed with the following observations: i) models fine-tuned on specific domains, such as landmarks or products, excel in that domain but fail on ILIAS ii) learning a linear adaptation layer using multi-domain class supervision results in performance improvements, especially for vision-language models iii) local descriptors in retrieval re-ranking are still a key ingredient, especially in the presence of severe background clutter iv) the text-to-image performance of the vision-language foundation models is surprisingly close to the corresponding image-to-image case. website: https://vrg.fel.cvut.cz/ilias/
AMES: Asymmetric and Memory-Efficient Similarity Estimation for Instance-level Retrieval
Aug 06, 2024This work investigates the problem of instance-level image retrieval re-ranking with the constraint of memory efficiency, ultimately aiming to limit memory usage to 1KB per image. Departing from the prevalent focus on performance enhancements, this work prioritizes the crucial trade-off between performance and memory requirements. The proposed model uses a transformer-based architecture designed to estimate image-to-image similarity by capturing interactions within and across images based on their local descriptors. A distinctive property of the model is the capability for asymmetric similarity estimation. Database images are represented with a smaller number of descriptors compared to query images, enabling performance improvements without increasing memory consumption. To ensure adaptability across different applications, a universal model is introduced that adjusts to a varying number of local descriptors during the testing phase. Results on standard benchmarks demonstrate the superiority of our approach over both hand-crafted and learned models. In particular, compared with current state-of-the-art methods that overlook their memory footprint, our approach not only attains superior performance but does so with a significantly reduced memory footprint. The code and pretrained models are publicly available at: https://github.com/pavelsuma/ames
Fusion Transformer with Object Mask Guidance for Image Forgery Analysis
Mar 18, 2024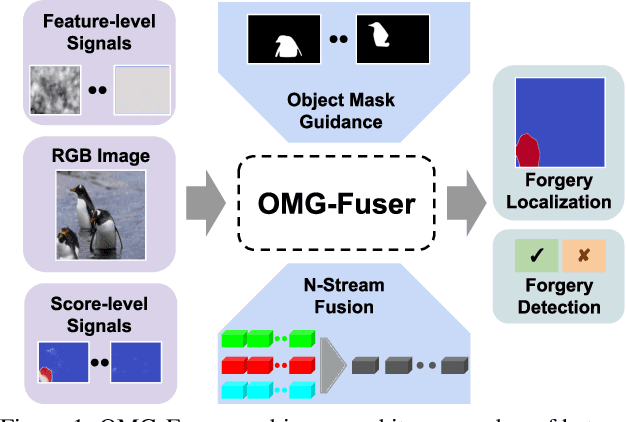
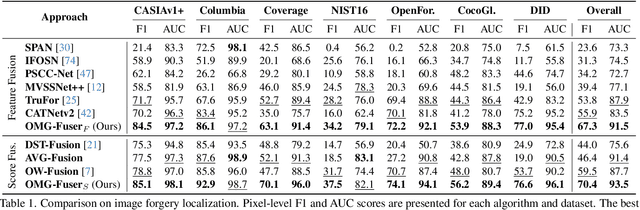
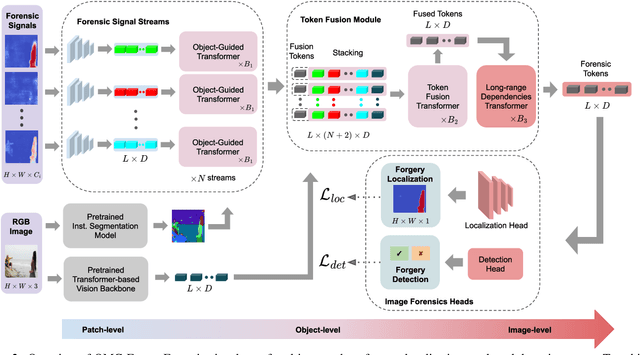
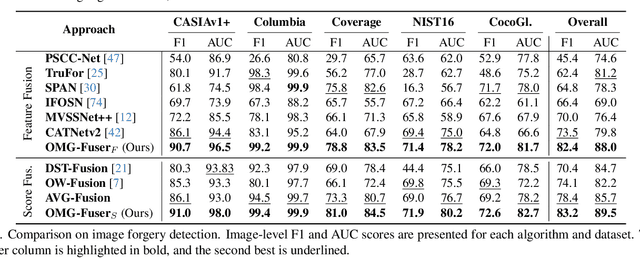
In this work, we introduce OMG-Fuser, a fusion transformer-based network designed to extract information from various forensic signals to enable robust image forgery detection and localization. Our approach can operate with an arbitrary number of forensic signals and leverages object information for their analysis -- unlike previous methods that rely on fusion schemes with few signals and often disregard image semantics. To this end, we design a forensic signal stream composed of a transformer guided by an object attention mechanism, associating patches that depict the same objects. In that way, we incorporate object-level information from the image. Each forensic signal is processed by a different stream that adapts to its peculiarities. Subsequently, a token fusion transformer efficiently aggregates the outputs of an arbitrary number of network streams and generates a fused representation for each image patch. These representations are finally processed by a long-range dependencies transformer that captures the intrinsic relations between the image patches. We assess two fusion variants on top of the proposed approach: (i) score-level fusion that fuses the outputs of multiple image forensics algorithms and (ii) feature-level fusion that fuses low-level forensic traces directly. Both variants exceed state-of-the-art performance on seven datasets for image forgery detection and localization, with a relative average improvement of 12.1% and 20.4% in terms of F1. Our network demonstrates robustness against traditional and novel forgery attacks and can be expanded with new signals without training from scratch.
The 2023 Video Similarity Dataset and Challenge
Jun 15, 2023
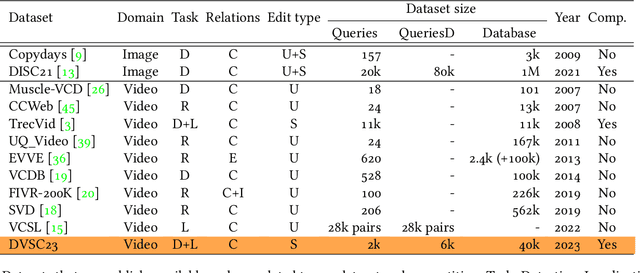

This work introduces a dataset, benchmark, and challenge for the problem of video copy detection and localization. The problem comprises two distinct but related tasks: determining whether a query video shares content with a reference video ("detection"), and additionally temporally localizing the shared content within each video ("localization"). The benchmark is designed to evaluate methods on these two tasks, and simulates a realistic needle-in-haystack setting, where the majority of both query and reference videos are "distractors" containing no copied content. We propose a metric that reflects both detection and localization accuracy. The associated challenge consists of two corresponding tracks, each with restrictions that reflect real-world settings. We provide implementation code for evaluation and baselines. We also analyze the results and methods of the top submissions to the challenge. The dataset, baseline methods and evaluation code is publicly available and will be discussed at a dedicated CVPR'23 workshop.
Improving Synthetically Generated Image Detection in Cross-Concept Settings
Apr 24, 2023



New advancements for the detection of synthetic images are critical for fighting disinformation, as the capabilities of generative AI models continuously evolve and can lead to hyper-realistic synthetic imagery at unprecedented scale and speed. In this paper, we focus on the challenge of generalizing across different concept classes, e.g., when training a detector on human faces and testing on synthetic animal images - highlighting the ineffectiveness of existing approaches that randomly sample generated images to train their models. By contrast, we propose an approach based on the premise that the robustness of the detector can be enhanced by training it on realistic synthetic images that are selected based on their quality scores according to a probabilistic quality estimation model. We demonstrate the effectiveness of the proposed approach by conducting experiments with generated images from two seminal architectures, StyleGAN2 and Latent Diffusion, and using three different concepts for each, so as to measure the cross-concept generalization ability. Our results show that our quality-based sampling method leads to higher detection performance for nearly all concepts, improving the overall effectiveness of the synthetic image detectors.
Self-Supervised Video Similarity Learning
Apr 06, 2023



We introduce S$^2$VS, a video similarity learning approach with self-supervision. Self-Supervised Learning (SSL) is typically used to train deep models on a proxy task so as to have strong transferability on target tasks after fine-tuning. Here, in contrast to prior work, SSL is used to perform video similarity learning and address multiple retrieval and detection tasks at once with no use of labeled data. This is achieved by learning via instance-discrimination with task-tailored augmentations and the widely used InfoNCE loss together with an additional loss operating jointly on self-similarity and hard-negative similarity. We benchmark our method on tasks where video relevance is defined with varying granularity, ranging from video copies to videos depicting the same incident or event. We learn a single universal model that achieves state-of-the-art performance on all tasks, surpassing previously proposed methods that use labeled data. The code and pretrained models are publicly available at: \url{https://github.com/gkordo/s2vs}
A Multi-Stream Fusion Network for Image Splicing Localization
Dec 02, 2022



In this paper, we address the problem of image splicing localization with a multi-stream network architecture that processes the raw RGB image in parallel with other handcrafted forensic signals. Unlike previous methods that either use only the RGB images or stack several signals in a channel-wise manner, we propose an encoder-decoder architecture that consists of multiple encoder streams. Each stream is fed with either the tampered image or handcrafted signals and processes them separately to capture relevant information from each one independently. Finally, the extracted features from the multiple streams are fused in the bottleneck of the architecture and propagated to the decoder network that generates the output localization map. We experiment with two handcrafted algorithms, i.e., DCT and Splicebuster. Our proposed approach is benchmarked on three public forensics datasets, demonstrating competitive performance against several competing methods and achieving state-of-the-art results, e.g., 0.898 AUC on CASIA.
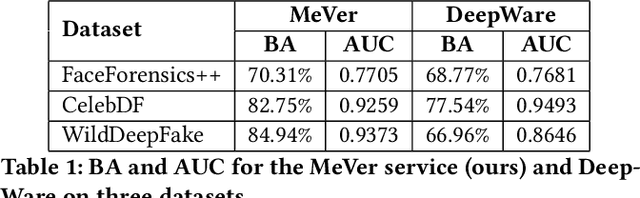
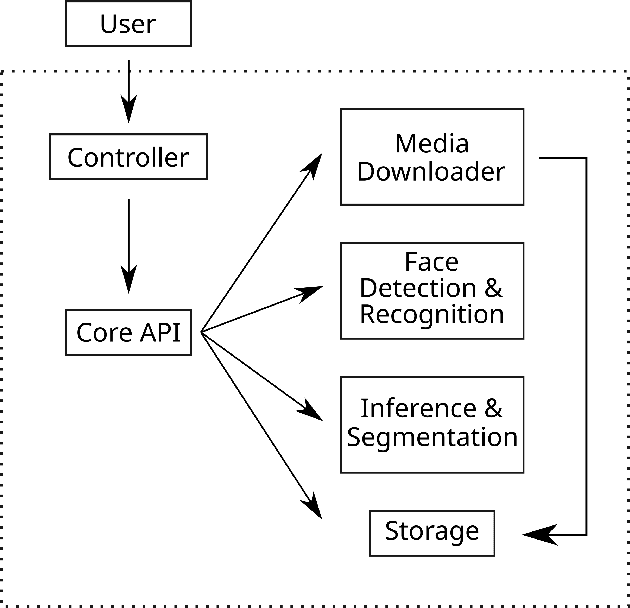
The MeVer DeepFake Detection Service: Lessons Learnt from Developing and Deploying in the Wild
Apr 27, 2022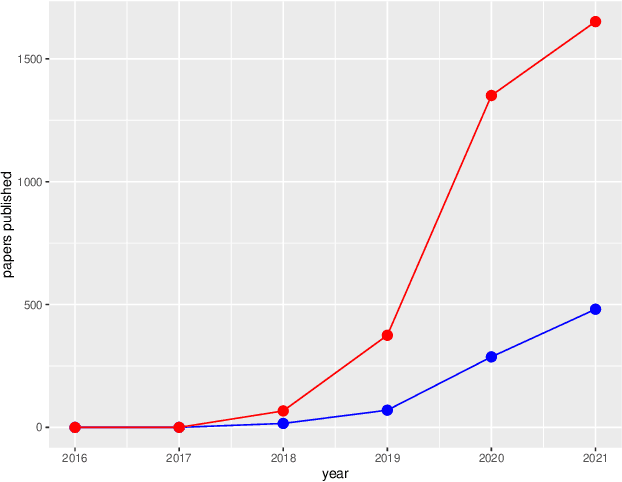
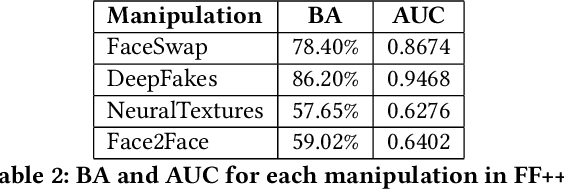
Enabled by recent improvements in generation methodologies, DeepFakes have become mainstream due to their increasingly better visual quality, the increase in easy-to-use generation tools and the rapid dissemination through social media. This fact poses a severe threat to our societies with the potential to erode social cohesion and influence our democracies. To mitigate the threat, numerous DeepFake detection schemes have been introduced in the literature but very few provide a web service that can be used in the wild. In this paper, we introduce the MeVer DeepFake detection service, a web service detecting deep learning manipulations in images and video. We present the design and implementation of the proposed processing pipeline that involves a model ensemble scheme, and we endow the service with a model card for transparency. Experimental results show that our service performs robustly on the three benchmark datasets while being vulnerable to Adversarial Attacks. Finally, we outline our experience and lessons learned when deploying a research system into production in the hopes that it will be useful to other academic and industry teams.