 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation
Mar 25, 2025We propose a training-free method for open-vocabulary semantic segmentation using Vision-and-Language Models (VLMs). Our approach enhances the initial per-patch predictions of VLMs through label propagation, which jointly optimizes predictions by incorporating patch-to-patch relationships. Since VLMs are primarily optimized for cross-modal alignment and not for intra-modal similarity, we use a Vision Model (VM) that is observed to better capture these relationships. We address resolution limitations inherent to patch-based encoders by applying label propagation at the pixel level as a refinement step, significantly improving segmentation accuracy near class boundaries. Our method, called LPOSS+, performs inference over the entire image, avoiding window-based processing and thereby capturing contextual interactions across the full image. LPOSS+ achieves state-of-the-art performance among training-free methods, across a diverse set of datasets. Code: https://github.com/vladan-stojnic/LPOSS
ILIAS: Instance-Level Image retrieval At Scale
Feb 17, 2025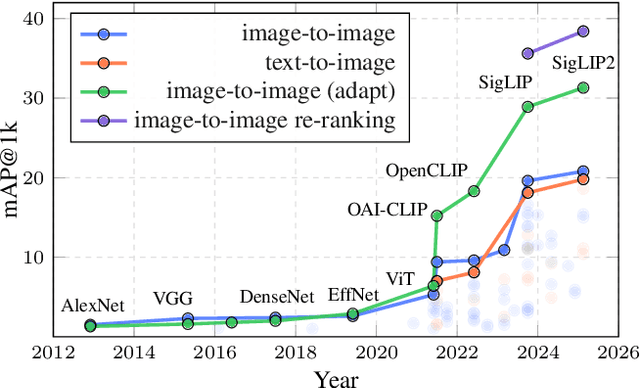
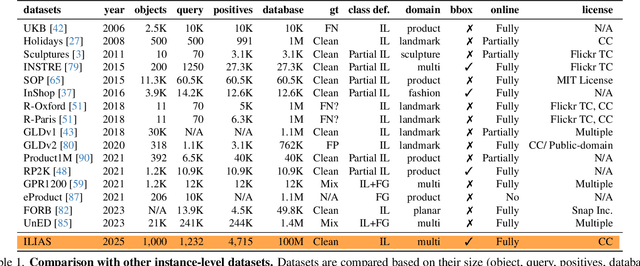

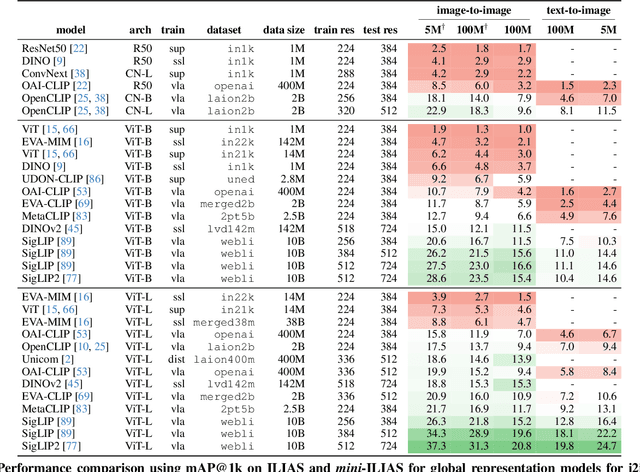
This work introduces ILIAS, a new test dataset for Instance-Level Image retrieval At Scale. It is designed to evaluate the ability of current and future foundation models and retrieval techniques to recognize particular objects. The key benefits over existing datasets include large scale, domain diversity, accurate ground truth, and a performance that is far from saturated. ILIAS includes query and positive images for 1,000 object instances, manually collected to capture challenging conditions and diverse domains. Large-scale retrieval is conducted against 100 million distractor images from YFCC100M. To avoid false negatives without extra annotation effort, we include only query objects confirmed to have emerged after 2014, i.e. the compilation date of YFCC100M. An extensive benchmarking is performed with the following observations: i) models fine-tuned on specific domains, such as landmarks or products, excel in that domain but fail on ILIAS ii) learning a linear adaptation layer using multi-domain class supervision results in performance improvements, especially for vision-language models iii) local descriptors in retrieval re-ranking are still a key ingredient, especially in the presence of severe background clutter iv) the text-to-image performance of the vision-language foundation models is surprisingly close to the corresponding image-to-image case. website: https://vrg.fel.cvut.cz/ilias/
WildFusion: Individual Animal Identification with Calibrated Similarity Fusion
Aug 23, 2024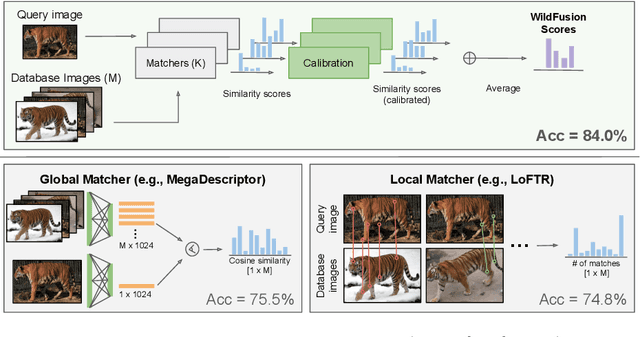
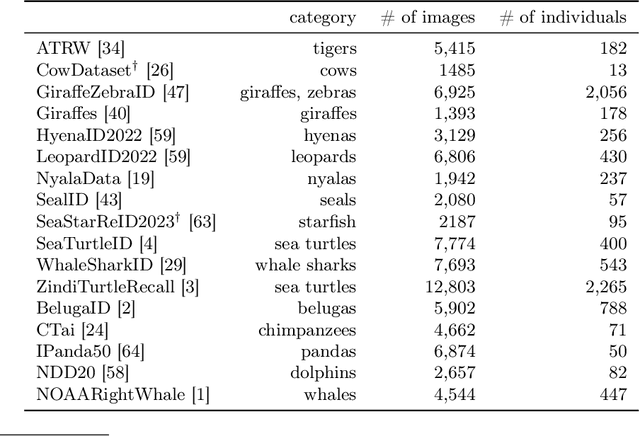


We propose a new method - WildFusion - for individual identification of a broad range of animal species. The method fuses deep scores (e.g., MegaDescriptor or DINOv2) and local matching similarity (e.g., LoFTR and LightGlue) to identify individual animals. The global and local information fusion is facilitated by similarity score calibration. In a zero-shot setting, relying on local similarity score only, WildFusion achieved mean accuracy, measured on 17 datasets, of 76.2%. This is better than the state-of-the-art model, MegaDescriptor-L, whose training set included 15 of the 17 datasets. If a dataset-specific calibration is applied, mean accuracy increases by 2.3% percentage points. WildFusion, with both local and global similarity scores, outperforms the state-of-the-art significantly - mean accuracy reached 84.0%, an increase of 8.5 percentage points; the mean relative error drops by 35%. We make the code and pre-trained models publicly available5, enabling immediate use in ecology and conservation.
EEPPR: Event-based Estimation of Periodic Phenomena Rate using Correlation in 3D
Aug 19, 2024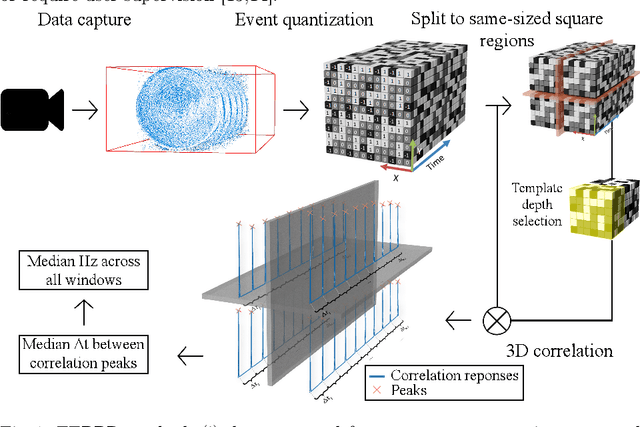

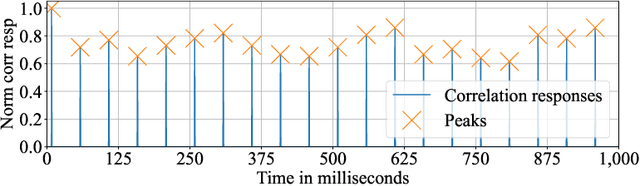
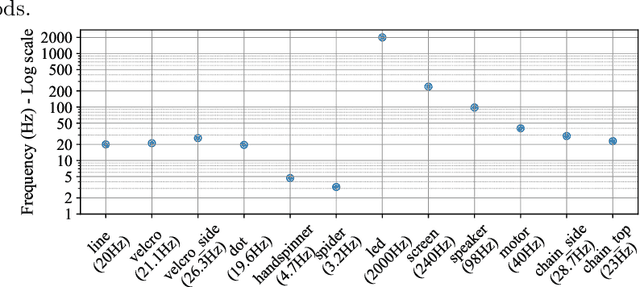
We present a novel method for measuring the period of phenomena like rotation, flicker and vibration, by an event camera, a device asynchronously reporting brightness changes at independently operating pixels with high temporal resolution. The approach assumes that for a periodic phenomenon, a highly similar set of events is generated within a spatio-temporal window at a time difference corresponding to its period. The sets of similar events are detected by a correlation in the spatio-temporal event stream space. The proposed method, EEPPR, is evaluated on a dataset of 12 sequences of periodic phenomena, i.e. flashing light and vibration, and periodic motion, e.g., rotation, ranging from 3.2 Hz to 2 kHz (equivalent to 192 - 120 000 RPM). EEPPR significantly outperforms published methods on this dataset, achieving the mean relative error of 0.1%. The dataset and codes are publicly available on GitHub.
EE3P3D: Event-based Estimation of Periodic Phenomena Frequency using 3D Correlation
Aug 13, 2024We present a novel method for measuring the frequency of periodic phenomena, e.g., rotation, flicker and vibration, by an event camera, a device asynchronously reporting brightness changes at independently operating pixels with high temporal resolution. The approach assumes that for a periodic phenomenon, a highly similar set of events is generated within a specific spatio-temporal window at a time difference corresponding to the phenomenon's period. The sets of similar events are detected by 3D spatio-temporal correlation in the event stream space. The proposed method, EE3P3D, is evaluated on a dataset of 12 sequences of periodic phenomena, i.e. flashing light and vibration, and periodic motion, e.g., rotation, ranging from 3.2 Hz to 2 kHz (equivalent to 192 - 120 000 RPM). EE3P3D significantly outperforms published methods on this dataset, achieving a mean relative error of 0.1%.
PixOOD: Pixel-Level Out-of-Distribution Detection
May 30, 2024We propose a dense image prediction out-of-distribution detection algorithm, called PixOOD, which does not require training on samples of anomalous data and is not designed for a specific application which avoids traditional training biases. In order to model the complex intra-class variability of the in-distribution data at the pixel level, we propose an online data condensation algorithm which is more robust than standard K-means and is easily trainable through SGD. We evaluate PixOOD on a wide range of problems. It achieved state-of-the-art results on four out of seven datasets, while being competitive on the rest. The source code is available at https://github.com/vojirt/PixOOD.
EE3P: Event-based Estimation of Periodic Phenomena Properties
Feb 22, 2024We introduce a novel method for measuring properties of periodic phenomena with an event camera, a device asynchronously reporting brightness changes at independently operating pixels. The approach assumes that for fast periodic phenomena, in any spatial window where it occurs, a very similar set of events is generated at the time difference corresponding to the frequency of the motion. To estimate the frequency, we compute correlations of spatio-temporal windows in the event space. The period is calculated from the time differences between the peaks of the correlation responses. The method is contactless, eliminating the need for markers, and does not need distinguishable landmarks. We evaluate the proposed method on three instances of periodic phenomena: (i) light flashes, (ii) vibration, and (iii) rotational speed. In all experiments, our method achieves a relative error lower than 0.04%, which is within the error margin of ground truth measurements.
* 9 pages, 55 figures, accepted and presented at CVWW24, published in Proceedings of the 27th Computer Vision Winter Workshop, 2024
Dense Matchers for Dense Tracking
Feb 17, 2024



Optical flow is a useful input for various applications, including 3D reconstruction, pose estimation, tracking, and structure-from-motion. Despite its utility, the field of dense long-term tracking, especially over wide baselines, has not been extensively explored. This paper extends the concept of combining multiple optical flows over logarithmically spaced intervals as proposed by MFT. We demonstrate the compatibility of MFT with different optical flow networks, yielding results that surpass their individual performance. Moreover, we present a simple yet effective combination of these networks within the MFT framework. This approach proves to be competitive with more sophisticated, non-causal methods in terms of position prediction accuracy, highlighting the potential of MFT in enhancing long-term tracking applications.
Improving 2D Human Pose Estimation across Unseen Camera Views with Synthetic Data
Jul 13, 2023



Human Pose Estimation is a thoroughly researched problem; however, most datasets focus on the side and front-view scenarios. We address the limitation by proposing a novel approach that tackles the challenges posed by extreme viewpoints and poses. We introduce a new method for synthetic data generation - RePoGen, RarE POses GENerator - with comprehensive control over pose and view to augment the COCO dataset. Experiments on a new dataset of real images show that adding RePoGen data to the COCO surpasses previous attempts to top-view pose estimation and significantly improves performance on the bottom-view dataset. Through an extensive ablation study on both the top and bottom view data, we elucidate the contributions of methodological choices and demonstrate improved performance. The code and the datasets are available on the project website.