 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Neural Architecture Search through Variance of Knowledge of Deep Network Weights
Feb 07, 2025



Deep learning has revolutionized computer vision, but it achieved its tremendous success using deep network architectures which are mostly hand-crafted and therefore likely suboptimal. Neural Architecture Search (NAS) aims to bridge this gap by following a well-defined optimization paradigm which systematically looks for the best architecture, given objective criterion such as maximal classification accuracy. The main limitation of NAS is however its astronomical computational cost, as it typically requires training each candidate network architecture from scratch. In this paper, we aim to alleviate this limitation by proposing a novel training-free proxy for image classification accuracy based on Fisher Information. The proposed proxy has a strong theoretical background in statistics and it allows estimating expected image classification accuracy of a given deep network without training the network, thus significantly reducing computational cost of standard NAS algorithms. Our training-free proxy achieves state-of-the-art results on three public datasets and in two search spaces, both when evaluated using previously proposed metrics, as well as using a new metric that we propose which we demonstrate is more informative for practical NAS applications. The source code is publicly available at http://www.github.com/ondratybl/VKDNW
WildFusion: Individual Animal Identification with Calibrated Similarity Fusion
Aug 23, 2024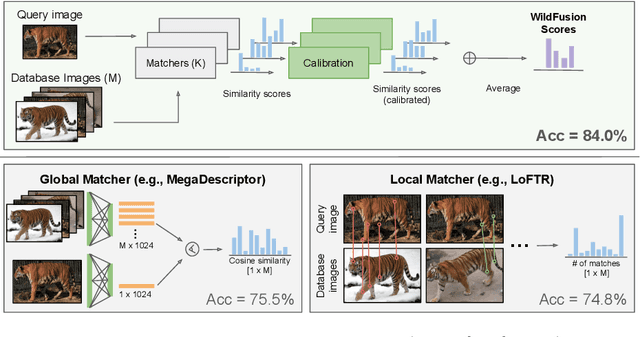
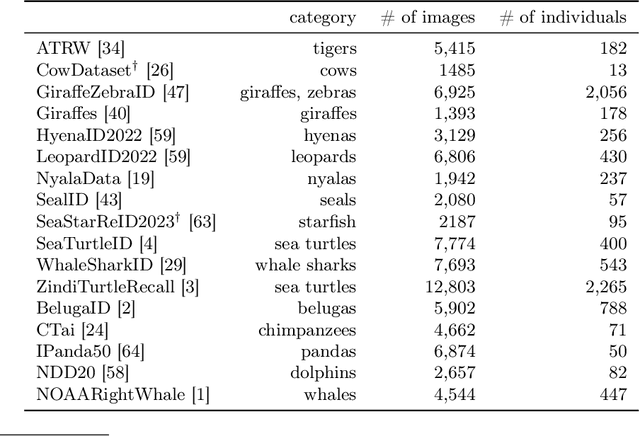


We propose a new method - WildFusion - for individual identification of a broad range of animal species. The method fuses deep scores (e.g., MegaDescriptor or DINOv2) and local matching similarity (e.g., LoFTR and LightGlue) to identify individual animals. The global and local information fusion is facilitated by similarity score calibration. In a zero-shot setting, relying on local similarity score only, WildFusion achieved mean accuracy, measured on 17 datasets, of 76.2%. This is better than the state-of-the-art model, MegaDescriptor-L, whose training set included 15 of the 17 datasets. If a dataset-specific calibration is applied, mean accuracy increases by 2.3% percentage points. WildFusion, with both local and global similarity scores, outperforms the state-of-the-art significantly - mean accuracy reached 84.0%, an increase of 8.5 percentage points; the mean relative error drops by 35%. We make the code and pre-trained models publicly available5, enabling immediate use in ecology and conservation.
Efficient Scene Text Localization and Recognition with Local Character Refinement
Apr 14, 2015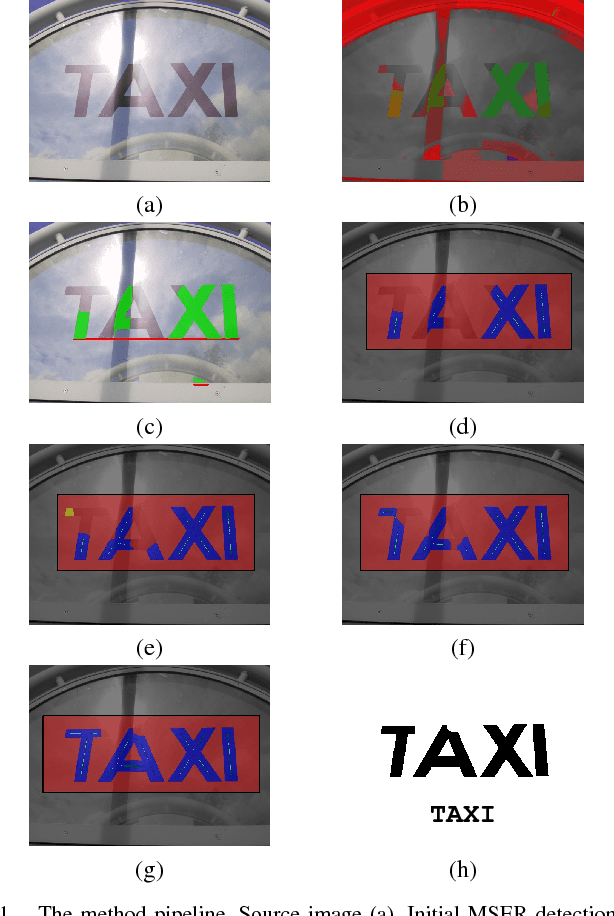
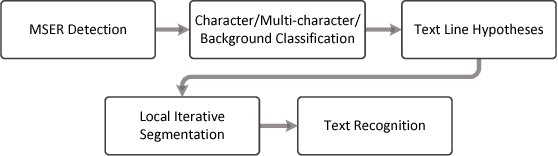

An unconstrained end-to-end text localization and recognition method is presented. The method detects initial text hypothesis in a single pass by an efficient region-based method and subsequently refines the text hypothesis using a more robust local text model, which deviates from the common assumption of region-based methods that all characters are detected as connected components. Additionally, a novel feature based on character stroke area estimation is introduced. The feature is efficiently computed from a region distance map, it is invariant to scaling and rotations and allows to efficiently detect text regions regardless of what portion of text they capture. The method runs in real time and achieves state-of-the-art text localization and recognition results on the ICDAR 2013 Robust Reading dataset.