 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILIAS: Instance-Level Image retrieval At Scale
Feb 17, 2025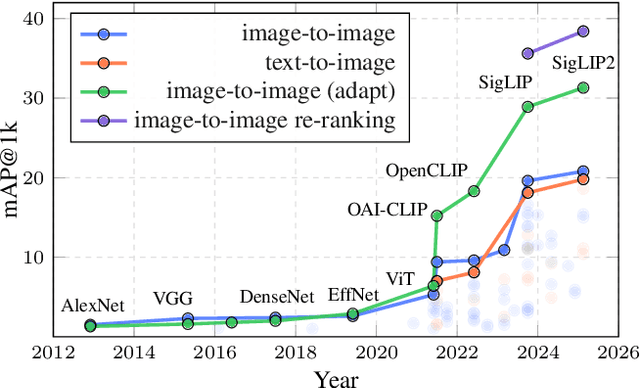
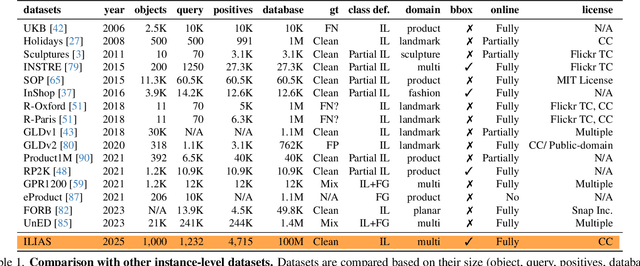

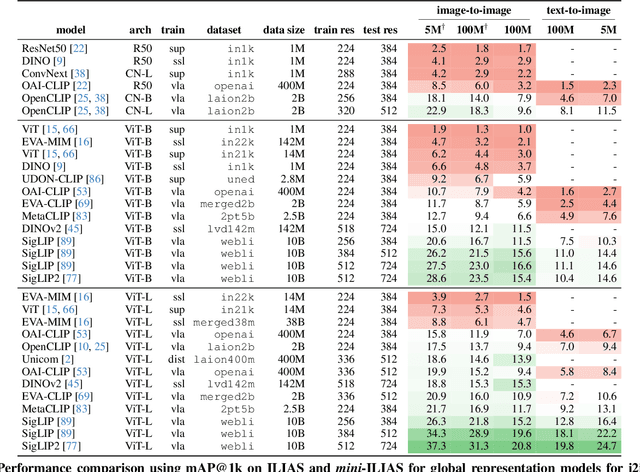
This work introduces ILIAS, a new test dataset for Instance-Level Image retrieval At Scale. It is designed to evaluate the ability of current and future foundation models and retrieval techniques to recognize particular objects. The key benefits over existing datasets include large scale, domain diversity, accurate ground truth, and a performance that is far from saturated. ILIAS includes query and positive images for 1,000 object instances, manually collected to capture challenging conditions and diverse domains. Large-scale retrieval is conducted against 100 million distractor images from YFCC100M. To avoid false negatives without extra annotation effort, we include only query objects confirmed to have emerged after 2014, i.e. the compilation date of YFCC100M. An extensive benchmarking is performed with the following observations: i) models fine-tuned on specific domains, such as landmarks or products, excel in that domain but fail on ILIAS ii) learning a linear adaptation layer using multi-domain class supervision results in performance improvements, especially for vision-language models iii) local descriptors in retrieval re-ranking are still a key ingredient, especially in the presence of severe background clutter iv) the text-to-image performance of the vision-language foundation models is surprisingly close to the corresponding image-to-image case. website: https://vrg.fel.cvut.cz/ilias/
Composed Image Retrieval for Training-Free Domain Conversion
Dec 04, 2024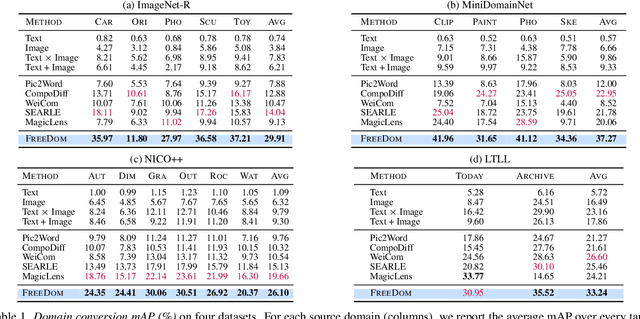
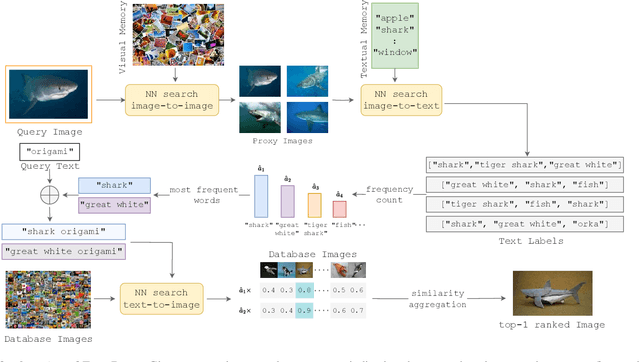


This work addresses composed image retrieval in the context of domain conversion, where the content of a query image is retrieved in the domain specified by the query text. We show that a strong vision-language model provides sufficient descriptive power without additional training. The query image is mapped to the text input space using textual inversion. Unlike common practice that invert in the continuous space of text tokens, we use the discrete word space via a nearest-neighbor search in a text vocabulary. With this inversion, the image is softly mapped across the vocabulary and is made more robust using retrieval-based augmentation. Database images are retrieved by a weighted ensemble of text queries combining mapped words with the domain text. Our method outperforms prior art by a large margin on standard and newly introduced benchmarks. Code: https://github.com/NikosEfth/freedom
Crafting Distribution Shifts for Validation and Training in Single Source Domain Generalization
Sep 29, 2024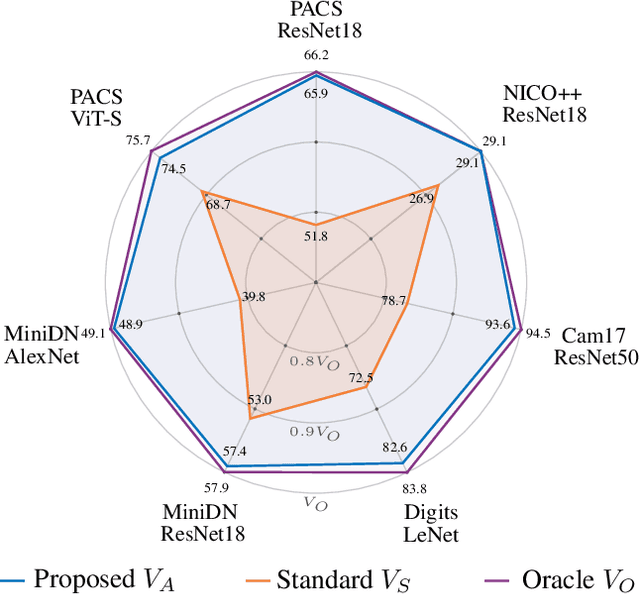
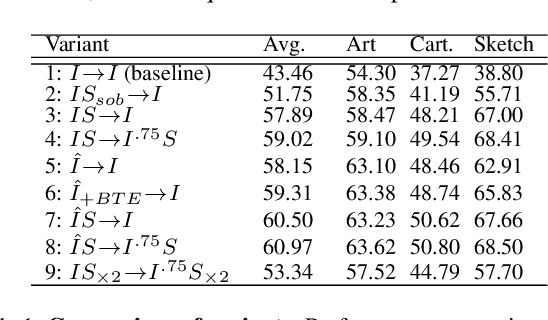

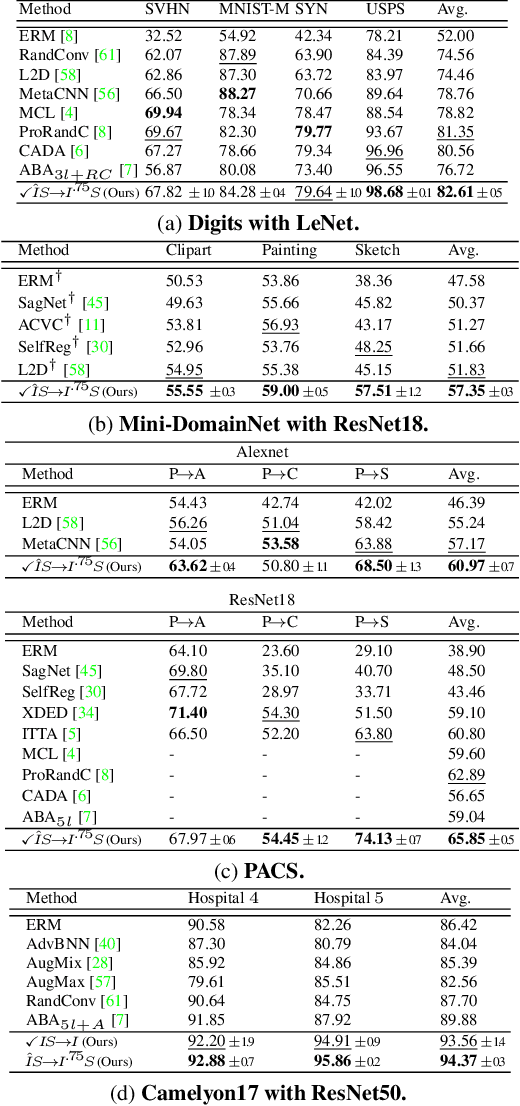
Single-source domain generalization attempts to learn a model on a source domain and deploy it to unseen target domains. Limiting access only to source domain data imposes two key challenges - how to train a model that can generalize and how to verify that it does. The standard practice of validation on the training distribution does not accurately reflect the model's generalization ability, while validation on the test distribution is a malpractice to avoid. In this work, we construct an independent validation set by transforming source domain images with a comprehensive list of augmentations, covering a broad spectrum of potential distribution shifts in target domains. We demonstrate a high correlation between validation and test performance for multiple methods and across various datasets. The proposed validation achieves a relative accuracy improvement over the standard validation equal to 15.4% or 1.6% when used for method selection or learning rate tuning, respectively. Furthermore, we introduce a novel family of methods that increase the shape bias through enhanced edge maps. To benefit from the augmentations during training and preserve the independence of the validation set, a k-fold validation process is designed to separate the augmentation types used in training and validation. The method that achieves the best performance on the augmented validation is selected from the proposed family. It achieves state-of-the-art performance on various standard benchmarks. Code at: https://github.com/NikosEfth/crafting-shifts
Composed Image Retrieval for Remote Sensing
May 29, 2024
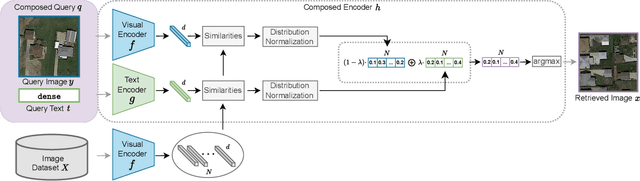


This work introduces composed image retrieval to remote sensing. It allows to query a large image archive by image examples alternated by a textual description, enriching the descriptive power over unimodal queries, either visual or textual. Various attributes can be modified by the textual part, such as shape, color, or context. A novel method fusing image-to-image and text-to-image similarity is introduced. We demonstrate that a vision-language model possesses sufficient descriptive power and no further learning step or training data are necessary. We present a new evaluation benchmark focused on color, context, density, existence, quantity, and shape modifications. Our work not only sets the state-of-the-art for this task, but also serves as a foundational step in addressing a gap in the field of remote sensing image retrieval. Code at: https://github.com/billpsomas/rscir
Edge Augmentation for Large-Scale Sketch Recognition without Sketches
Feb 26, 2022



This work addresses scaling up the sketch classification task into a large number of categories. Collecting sketches for training is a slow and tedious process that has so far precluded any attempts to large-scale sketch recognition. We overcome the lack of training sketch data by exploiting labeled collections of natural images that are easier to obtain. To bridge the domain gap we present a novel augmentation technique that is tailored to the task of learning sketch recognition from a training set of natural images. Randomization is introduced in the parameters of edge detection and edge selection. Natural images are translated to a pseudo-novel domain called "randomized Binary Thin Edges" (rBTE), which is used as a training domain instead of natural images. The ability to scale up is demonstrated by training CNN-based sketch recognition of more than 2.5 times larger number of categories than used previously. For this purpose, a dataset of natural images from 874 categories is constructed by combining a number of popular computer vision datasets. The categories are selected to be suitable for sketch recognition. To estimate the performance, a subset of 393 categories with sketches is also collected.