 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILIAS: Instance-Level Image retrieval At Scale
Feb 17, 2025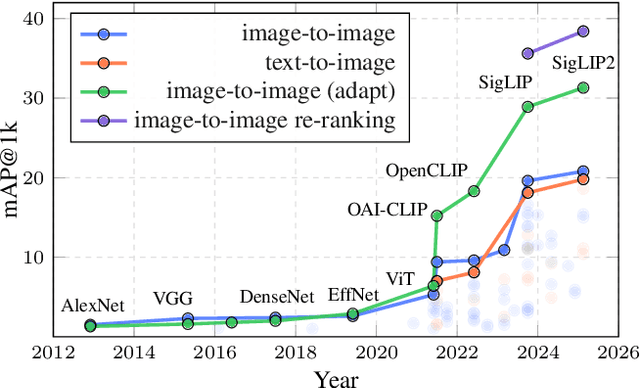
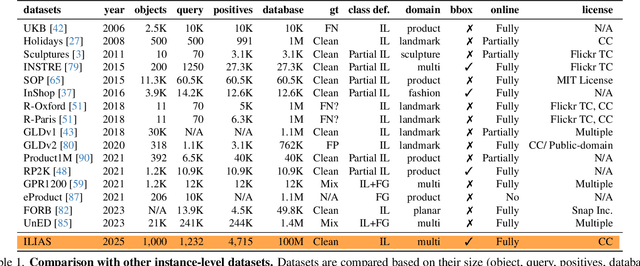

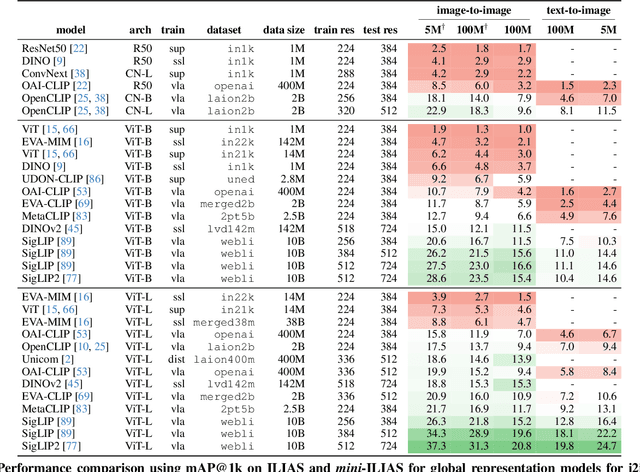
This work introduces ILIAS, a new test dataset for Instance-Level Image retrieval At Scale. It is designed to evaluate the ability of current and future foundation models and retrieval techniques to recognize particular objects. The key benefits over existing datasets include large scale, domain diversity, accurate ground truth, and a performance that is far from saturated. ILIAS includes query and positive images for 1,000 object instances, manually collected to capture challenging conditions and diverse domains. Large-scale retrieval is conducted against 100 million distractor images from YFCC100M. To avoid false negatives without extra annotation effort, we include only query objects confirmed to have emerged after 2014, i.e. the compilation date of YFCC100M. An extensive benchmarking is performed with the following observations: i) models fine-tuned on specific domains, such as landmarks or products, excel in that domain but fail on ILIAS ii) learning a linear adaptation layer using multi-domain class supervision results in performance improvements, especially for vision-language models iii) local descriptors in retrieval re-ranking are still a key ingredient, especially in the presence of severe background clutter iv) the text-to-image performance of the vision-language foundation models is surprisingly close to the corresponding image-to-image case. website: https://vrg.fel.cvut.cz/ilias/
Composed Image Retrieval for Training-Free Domain Conversion
Dec 04, 2024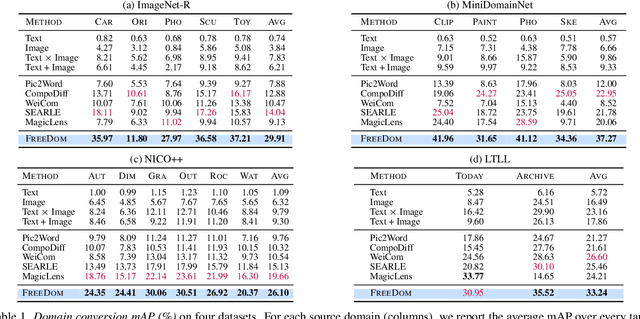
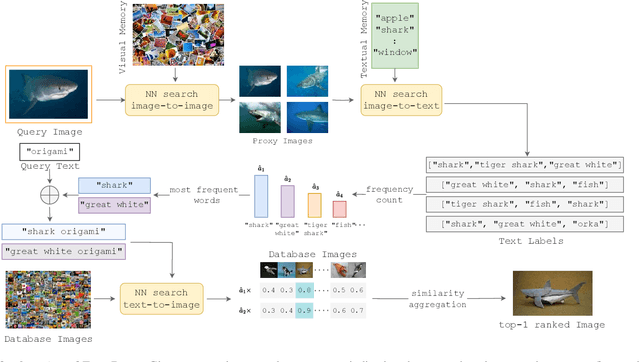


This work addresses composed image retrieval in the context of domain conversion, where the content of a query image is retrieved in the domain specified by the query text. We show that a strong vision-language model provides sufficient descriptive power without additional training. The query image is mapped to the text input space using textual inversion. Unlike common practice that invert in the continuous space of text tokens, we use the discrete word space via a nearest-neighbor search in a text vocabulary. With this inversion, the image is softly mapped across the vocabulary and is made more robust using retrieval-based augmentation. Database images are retrieved by a weighted ensemble of text queries combining mapped words with the domain text. Our method outperforms prior art by a large margin on standard and newly introduced benchmarks. Code: https://github.com/NikosEfth/freedom
Co-Segmentation without any Pixel-level Supervision with Application to Large-Scale Sketch Classification
Oct 17, 2024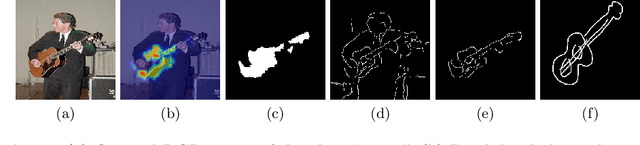
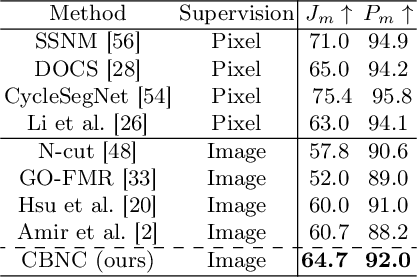
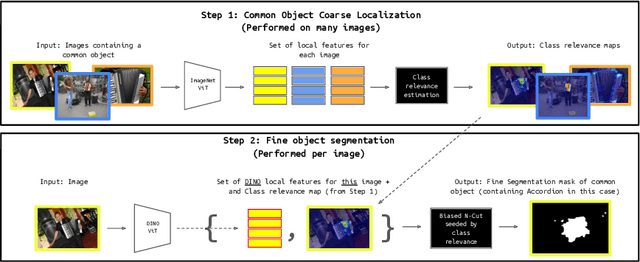
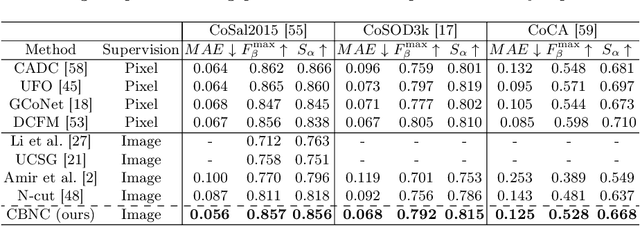
This work proposes a novel method for object co-segmentation, i.e. pixel-level localization of a common object in a set of images, that uses no pixel-level supervision for training. Two pre-trained Vision Transformer (ViT) models are exploited: ImageNet classification-trained ViT, whose features are used to estimate rough object localization through intra-class token relevance, and a self-supervised DINO-ViT for intra-image token relevance. On recent challenging benchmarks, the method achieves state-of-the-art performance among methods trained with the same level of supervision (image labels) while being competitive with methods trained with pixel-level supervision (binary masks). The benefits of the proposed co-segmentation method are further demonstrated in the task of large-scale sketch recognition, that is, the classification of sketches into a wide range of categories. The limited amount of hand-drawn sketch training data is leveraged by exploiting readily available image-level-annotated datasets of natural images containing a large number of classes. To bridge the domain gap, the classifier is trained on a sketch-like proxy domain derived from edges detected on natural images. We show that sketch recognition significantly benefits when the classifier is trained on sketch-like structures extracted from the co-segmented area rather than from the full image. Code: https://github.com/nikosips/CBNC .
Crafting Distribution Shifts for Validation and Training in Single Source Domain Generalization
Sep 29, 2024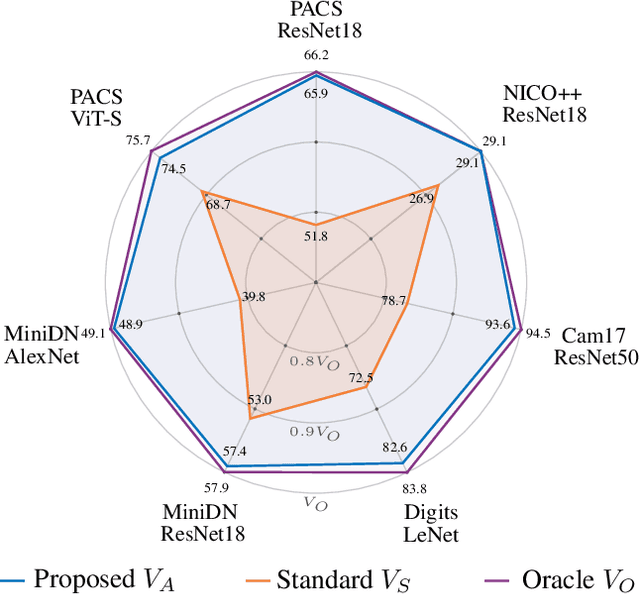
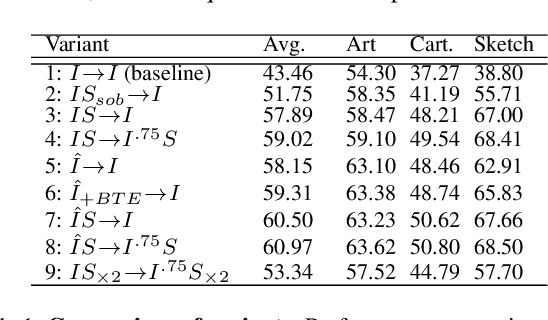

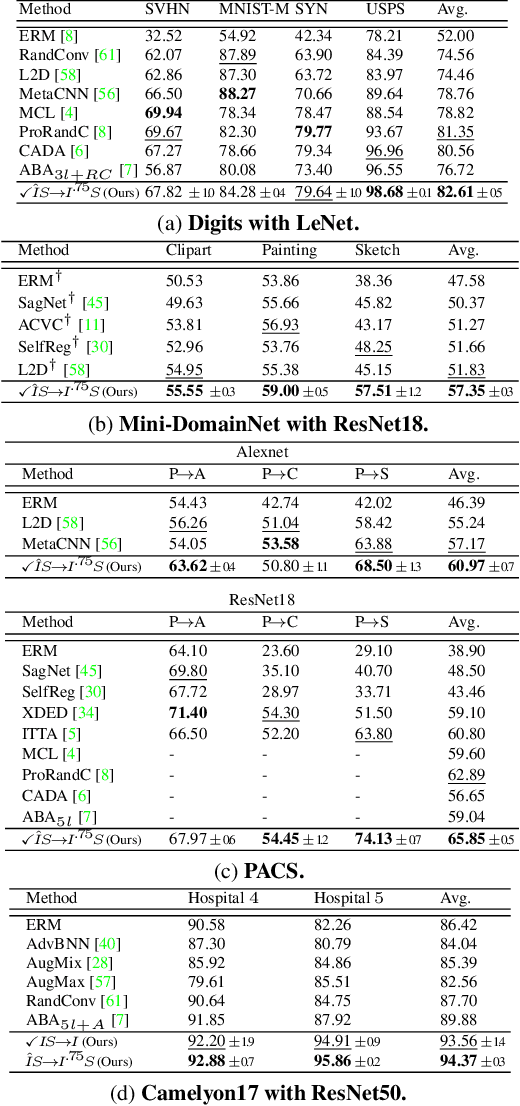
Single-source domain generalization attempts to learn a model on a source domain and deploy it to unseen target domains. Limiting access only to source domain data imposes two key challenges - how to train a model that can generalize and how to verify that it does. The standard practice of validation on the training distribution does not accurately reflect the model's generalization ability, while validation on the test distribution is a malpractice to avoid. In this work, we construct an independent validation set by transforming source domain images with a comprehensive list of augmentations, covering a broad spectrum of potential distribution shifts in target domains. We demonstrate a high correlation between validation and test performance for multiple methods and across various datasets. The proposed validation achieves a relative accuracy improvement over the standard validation equal to 15.4% or 1.6% when used for method selection or learning rate tuning, respectively. Furthermore, we introduce a novel family of methods that increase the shape bias through enhanced edge maps. To benefit from the augmentations during training and preserve the independence of the validation set, a k-fold validation process is designed to separate the augmentation types used in training and validation. The method that achieves the best performance on the augmented validation is selected from the proposed family. It achieves state-of-the-art performance on various standard benchmarks. Code at: https://github.com/NikosEfth/crafting-shifts
UDON: Universal Dynamic Online distillatioN for generic image representations
Jun 12, 2024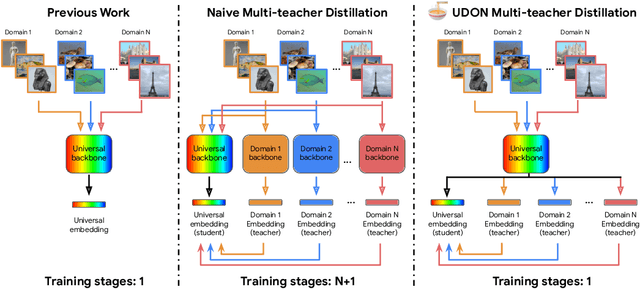

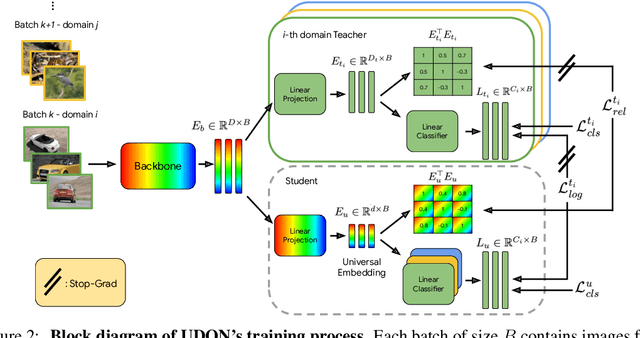
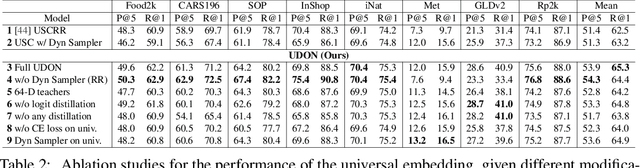
Universal image representations are critical in enabling real-world fine-grained and instance-level recognition applications, where objects and entities from any domain must be identified at large scale. Despite recent advances, existing methods fail to capture important domain-specific knowledge, while also ignoring differences in data distribution across different domains. This leads to a large performance gap between efficient universal solutions and expensive approaches utilising a collection of specialist models, one for each domain. In this work, we make significant strides towards closing this gap, by introducing a new learning technique, dubbed UDON (Universal Dynamic Online DistillatioN). UDON employs multi-teacher distillation, where each teacher is specialized in one domain, to transfer detailed domain-specific knowledge into the student universal embedding. UDON's distillation approach is not only effective, but also very efficient, by sharing most model parameters between the student and all teachers, where all models are jointly trained in an online manner. UDON also comprises a sampling technique which adapts the training process to dynamically allocate batches to domains which are learned slower and require more frequent processing. This boosts significantly the learning of complex domains which are characterised by a large number of classes and long-tail distributions. With comprehensive experiments, we validate each component of UDON, and showcase significant improvements over the state of the art in the recent UnED benchmark. Code: https://github.com/nikosips/UDON .
Dark Side Augmentation: Generating Diverse Night Examples for Metric Learning
Sep 28, 2023Image retrieval methods based on CNN descriptors rely on metric learning from a large number of diverse examples of positive and negative image pairs. Domains, such as night-time images, with limited availability and variability of training data suffer from poor retrieval performance even with methods performing well on standard benchmarks. We propose to train a GAN-based synthetic-image generator, translating available day-time image examples into night images. Such a generator is used in metric learning as a form of augmentation, supplying training data to the scarce domain. Various types of generators are evaluated and analyzed. We contribute with a novel light-weight GAN architecture that enforces the consistency between the original and translated image through edge consistency. The proposed architecture also allows a simultaneous training of an edge detector that operates on both night and day images. To further increase the variability in the training examples and to maximize the generalization of the trained model, we propose a novel method of diverse anchor mining. The proposed method improves over the state-of-the-art results on a standard Tokyo 24/7 day-night retrieval benchmark while preserving the performance on Oxford and Paris datasets. This is achieved without the need of training image pairs of matching day and night images. The source code is available at https://github.com/mohwald/gandtr .
* 11 pages, 4 figures, 8 tables
Towards Universal Image Embeddings: A Large-Scale Dataset and Challenge for Generic Image Representations
Sep 04, 2023Fine-grained and instance-level recognition methods are commonly trained and evaluated on specific domains, in a model per domain scenario. Such an approach, however, is impractical in real large-scale applications. In this work, we address the problem of universal image embedding, where a single universal model is trained and used in multiple domains. First, we leverage existing domain-specific datasets to carefully construct a new large-scale public benchmark for the evaluation of universal image embeddings, with 241k query images, 1.4M index images and 2.8M training images across 8 different domains and 349k classes. We define suitable metrics, training and evaluation protocols to foster future research in this area. Second, we provide a comprehensive experimental evaluation on the new dataset, demonstrating that existing approaches and simplistic extensions lead to worse performance than an assembly of models trained for each domain separately. Finally, we conducted a public research competition on this topic, leveraging industrial datasets, which attracted the participation of more than 1k teams worldwide. This exercise generated many interesting research ideas and findings which we present in detail. Project webpage: https://cmp.felk.cvut.cz/univ_emb/
Object-Guided Day-Night Visual Localization in Urban Scenes
Feb 09, 2022
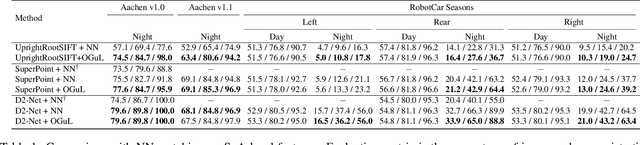
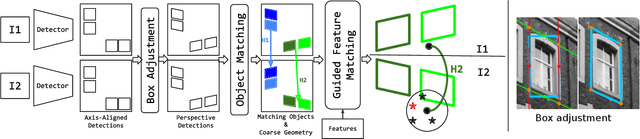

We introduce Object-Guided Localization (OGuL) based on a novel method of local-feature matching. Direct matching of local features is sensitive to significant changes in illumination. In contrast, object detection often survives severe changes in lighting conditions. The proposed method first detects semantic objects and establishes correspondences of those objects between images. Object correspondences provide local coarse alignment of the images in the form of a planar homography. These homographies are consequently used to guide the matching of local features. Experiments on standard urban localization datasets (Aachen, Extended-CMU-Season, RobotCar-Season) show that OGuL significantly improves localization results with as simple local features as SIFT, and its performance competes with the state-of-the-art CNN-based methods trained for day-to-night localization.
The 2021 Image Similarity Dataset and Challenge
Jul 01, 2021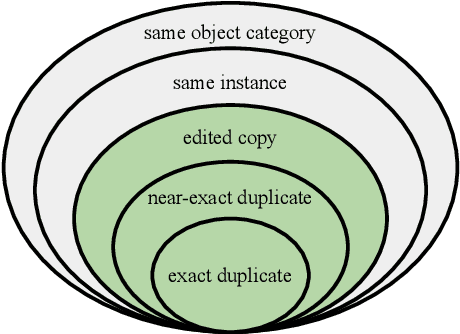
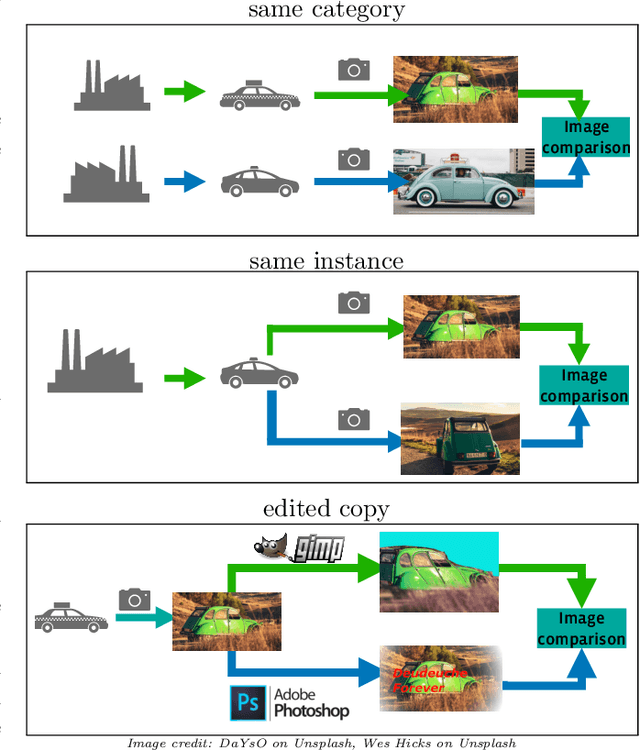

This paper introduces a new benchmark for large-scale image similarity detection. This benchmark is used for the Image Similarity Challenge at NeurIPS'21 (ISC2021). The goal is to determine whether a query image is a modified copy of any image in a reference corpus of size 1~million. The benchmark features a variety of image transformations such as automated transformations, hand-crafted image edits and machine-learning based manipulations. This mimics real-life cases appearing in social media, for example for integrity-related problems dealing with misinformation and objectionable content. The strength of the image manipulations, and therefore the difficulty of the benchmark, is calibrated according to the performance of a set of baseline approaches. Both the query and reference set contain a majority of "distractor" images that do not match, which corresponds to a real-life needle-in-haystack setting, and the evaluation metric reflects that. We expect the DISC21 benchmark to promote image copy detection as an important and challenging computer vision task and refresh the state of the art.
Learning and aggregating deep local descriptors for instance-level recognition
Jul 26, 2020
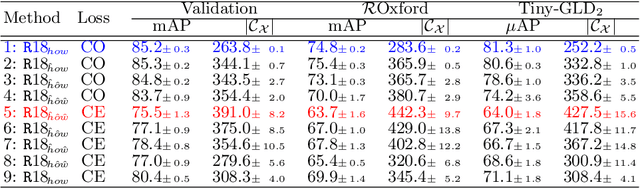
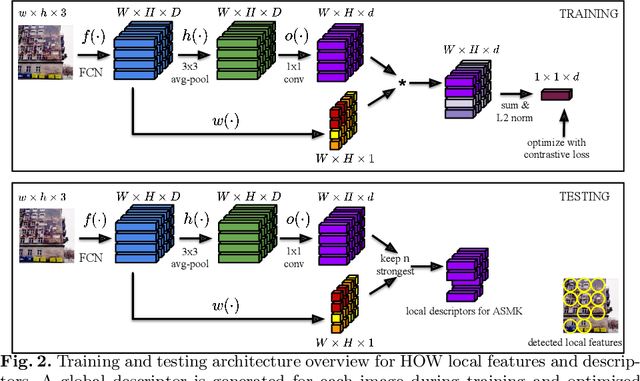
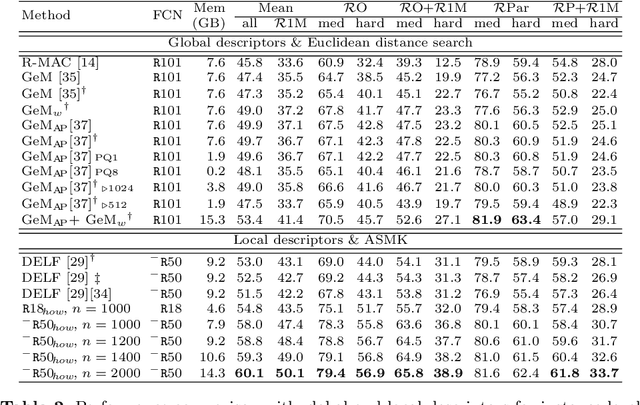
We propose an efficient method to learn deep local descriptors for instance-level recognition. The training only requires examples of positive and negative image pairs and is performed as metric learning of sum-pooled global image descriptors. At inference, the local descriptors are provided by the activations of internal components of the network. We demonstrate why such an approach learns local descriptors that work well for image similarity estimation with classical efficient match kernel methods. The experimental validation studies the trade-off between performance and memory requirements of the state-of-the-art image search approach based on match kernels. Compared to existing local descriptors, the proposed ones perform better in two instance-level recognition tasks and keep memory requirements lower. We experimentally show that global descriptors are not effective enough at large scale and that local descriptors are essential. We achieve state-of-the-art performance, in some cases even with a backbone network as small as ResNet18.