 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Human Reconstruction and Animation using Feed-Forward Gaussian Splatting
Apr 11, 2026We present a generalizable feed-forward Gaussian splatting framework for human 3D reconstruction and real-time animation that operates directly on multi-view RGB images and their associated SMPL-X poses. Unlike prior methods that rely on depth supervision, fixed input views, UV map, or repeated feed-forward inference for each target view or pose, our approach predicts, in a canonical pose, a set of 3D Gaussian primitives associated with each SMPL-X vertex. One Gaussian is regularized to remain close to the SMPL-X surface, providing a strong geometric prior and stable correspondence to the parametric body model, while an additional small set of unconstrained Gaussians per vertex allows the representation to capture geometric structures that deviate from the parametric surface, such as clothing and hair. In contrast to recent approaches such as HumanRAM, which require repeated network inference to synthesize novel poses, our method produces an animatable human representation from a single forward pass; by explicitly associating Gaussian primitives with SMPL-X vertices, the reconstructed model can be efficiently animated via linear blend skinning without further network evaluation. We evaluate our method on the THuman 2.1, AvatarReX and THuman 4.0 datasets, where it achieves reconstruction quality comparable to state-of-the-art methods while uniquely supporting real-time animation and interactive applications. Code and pre-trained models are available at https://github.com/Devdoot57/HumanGS .
PhyEduVideo: A Benchmark for Evaluating Text-to-Video Models for Physics Education
Jan 02, 2026Generative AI models, particularly Text-to-Video (T2V) systems, offer a promising avenue for transforming science education by automating the creation of engaging and intuitive visual explanations. In this work, we take a first step toward evaluating their potential in physics education by introducing a dedicated benchmark for explanatory video generation. The benchmark is designed to assess how well T2V models can convey core physics concepts through visual illustrations. Each physics concept in our benchmark is decomposed into granular teaching points, with each point accompanied by a carefully crafted prompt intended for visual explanation of the teaching point. T2V models are evaluated on their ability to generate accurate videos in response to these prompts. Our aim is to systematically explore the feasibility of using T2V models to generate high-quality, curriculum-aligned educational content-paving the way toward scalable, accessible, and personalized learning experiences powered by AI. Our evaluation reveals that current models produce visually coherent videos with smooth motion and minimal flickering, yet their conceptual accuracy is less reliable. Performance in areas such as mechanics, fluids, and optics is encouraging, but models struggle with electromagnetism and thermodynamics, where abstract interactions are harder to depict. These findings underscore the gap between visual quality and conceptual correctness in educational video generation. We hope this benchmark helps the community close that gap and move toward T2V systems that can deliver accurate, curriculum-aligned physics content at scale. The benchmark and accompanying codebase are publicly available at https://github.com/meghamariamkm/PhyEduVideo.
A Dataset for Semantic Segmentation in the Presence of Unknowns
Mar 28, 2025Before deployment in the real-world deep neural networks require thorough evaluation of how they handle both knowns, inputs represented in the training data, and unknowns (anomalies). This is especially important for scene understanding tasks with safety critical applications, such as in autonomous driving. Existing datasets allow evaluation of only knowns or unknowns - but not both, which is required to establish "in the wild" suitability of deep neural network models. To bridge this gap, we propose a novel anomaly segmentation dataset, ISSU, that features a diverse set of anomaly inputs from cluttered real-world environments. The dataset is twice larger than existing anomaly segmentation datasets, and provides a training, validation and test set for controlled in-domain evaluation. The test set consists of a static and temporal part, with the latter comprised of videos. The dataset provides annotations for both closed-set (knowns) and anomalies, enabling closed-set and open-set evaluation. The dataset covers diverse conditions, such as domain and cross-sensor shift, illumination variation and allows ablation of anomaly detection methods with respect to these variations. Evaluation results of current state-of-the-art methods confirm the need for improvements especially in domain-generalization, small and large object segmentation.
ILIAS: Instance-Level Image retrieval At Scale
Feb 17, 2025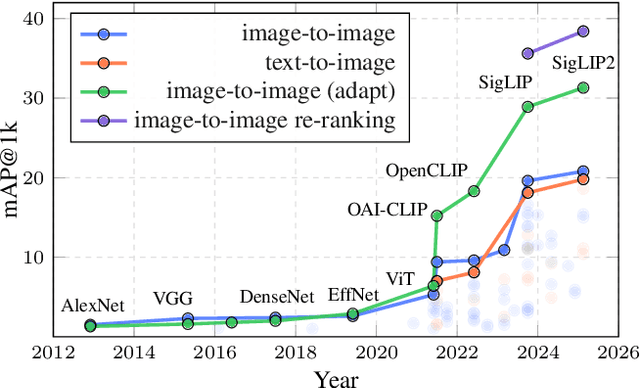
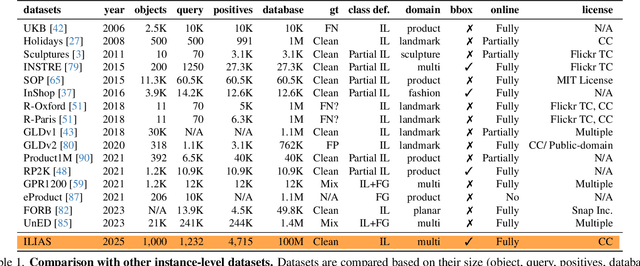

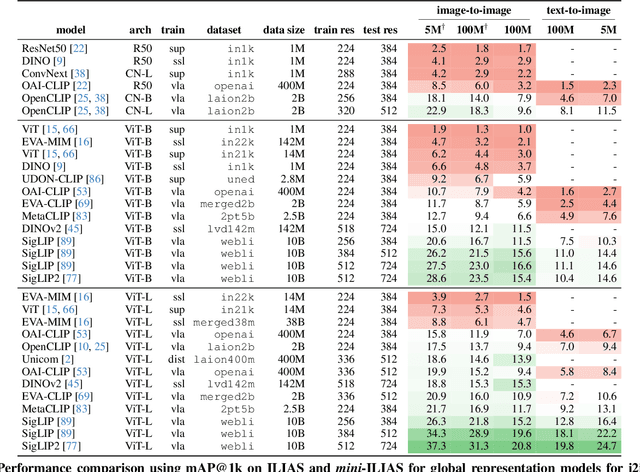
This work introduces ILIAS, a new test dataset for Instance-Level Image retrieval At Scale. It is designed to evaluate the ability of current and future foundation models and retrieval techniques to recognize particular objects. The key benefits over existing datasets include large scale, domain diversity, accurate ground truth, and a performance that is far from saturated. ILIAS includes query and positive images for 1,000 object instances, manually collected to capture challenging conditions and diverse domains. Large-scale retrieval is conducted against 100 million distractor images from YFCC100M. To avoid false negatives without extra annotation effort, we include only query objects confirmed to have emerged after 2014, i.e. the compilation date of YFCC100M. An extensive benchmarking is performed with the following observations: i) models fine-tuned on specific domains, such as landmarks or products, excel in that domain but fail on ILIAS ii) learning a linear adaptation layer using multi-domain class supervision results in performance improvements, especially for vision-language models iii) local descriptors in retrieval re-ranking are still a key ingredient, especially in the presence of severe background clutter iv) the text-to-image performance of the vision-language foundation models is surprisingly close to the corresponding image-to-image case. website: https://vrg.fel.cvut.cz/ilias/
Composed Image Retrieval for Training-Free Domain Conversion
Dec 04, 2024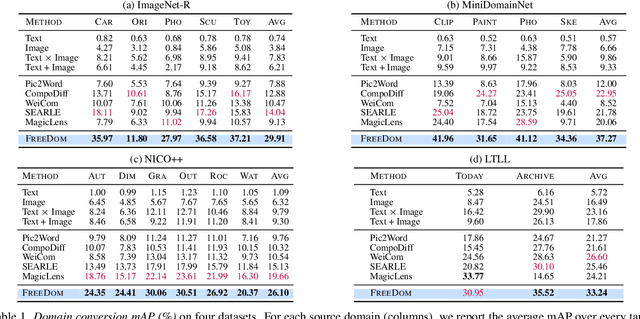
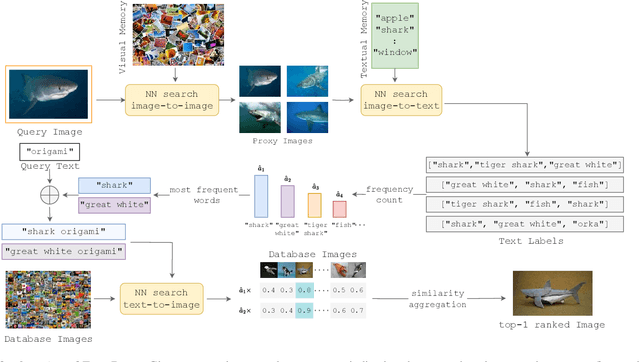


This work addresses composed image retrieval in the context of domain conversion, where the content of a query image is retrieved in the domain specified by the query text. We show that a strong vision-language model provides sufficient descriptive power without additional training. The query image is mapped to the text input space using textual inversion. Unlike common practice that invert in the continuous space of text tokens, we use the discrete word space via a nearest-neighbor search in a text vocabulary. With this inversion, the image is softly mapped across the vocabulary and is made more robust using retrieval-based augmentation. Database images are retrieved by a weighted ensemble of text queries combining mapped words with the domain text. Our method outperforms prior art by a large margin on standard and newly introduced benchmarks. Code: https://github.com/NikosEfth/freedom
Differentiable Product Quantization for Memory Efficient Camera Relocalization
Jul 23, 2024



Camera relocalization relies on 3D models of the scene with a large memory footprint that is incompatible with the memory budget of several applications. One solution to reduce the scene memory size is map compression by removing certain 3D points and descriptor quantization. This achieves high compression but leads to performance drop due to information loss. To address the memory performance trade-off, we train a light-weight scene-specific auto-encoder network that performs descriptor quantization-dequantization in an end-to-end differentiable manner updating both product quantization centroids and network parameters through back-propagation. In addition to optimizing the network for descriptor reconstruction, we encourage it to preserve the descriptor-matching performance with margin-based metric loss functions. Results show that for a local descriptor memory of only 1MB, the synergistic combination of the proposed network and map compression achieves the best performance on the Aachen Day-Night compared to existing compression methods.
Training Ensembles with Inliers and Outliers for Semi-supervised Active Learning
Jul 07, 2023
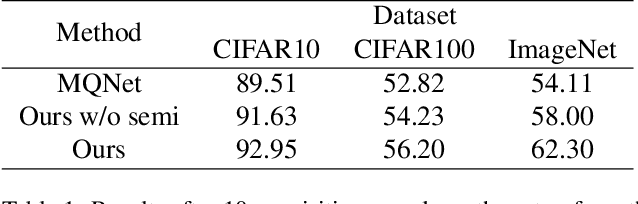


Deep active learning in the presence of outlier examples poses a realistic yet challenging scenario. Acquiring unlabeled data for annotation requires a delicate balance between avoiding outliers to conserve the annotation budget and prioritizing useful inlier examples for effective training. In this work, we present an approach that leverages three highly synergistic components, which are identified as key ingredients: joint classifier training with inliers and outliers, semi-supervised learning through pseudo-labeling, and model ensembling. Our work demonstrates that ensembling significantly enhances the accuracy of pseudo-labeling and improves the quality of data acquisition. By enabling semi-supervision through the joint training process, where outliers are properly handled, we observe a substantial boost in classifier accuracy through the use of all available unlabeled examples. Notably, we reveal that the integration of joint training renders explicit outlier detection unnecessary; a conventional component for acquisition in prior work. The three key components align seamlessly with numerous existing approaches. Through empirical evaluations, we showcase that their combined use leads to a performance increase. Remarkably, despite its simplicity, our proposed approach outperforms all other methods in terms of performance. Code: https://github.com/vladan-stojnic/active-outliers
HSCNet++: Hierarchical Scene Coordinate Classification and Regression for Visual Localization with Transformer
May 05, 2023Visual localization is critical to many applications in computer vision and robotics. To address single-image RGB localization, state-of-the-art feature-based methods match local descriptors between a query image and a pre-built 3D model. Recently, deep neural networks have been exploited to regress the mapping between raw pixels and 3D coordinates in the scene, and thus the matching is implicitly performed by the forward pass through the network. However, in a large and ambiguous environment, learning such a regression task directly can be difficult for a single network. In this work, we present a new hierarchical scene coordinate network to predict pixel scene coordinates in a coarse-to-fine manner from a single RGB image. The proposed method, which is an extension of HSCNet, allows us to train compact models which scale robustly to large environments. It sets a new state-of-the-art for single-image localization on the 7-Scenes, 12 Scenes, Cambridge Landmarks datasets, and the combined indoor scenes.
Digging Into Self-Supervised Learning of Feature Descriptors
Oct 10, 2021

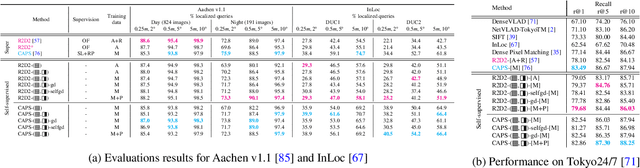

Fully-supervised CNN-based approaches for learning local image descriptors have shown remarkable results in a wide range of geometric tasks. However, most of them require per-pixel ground-truth keypoint correspondence data which is difficult to acquire at scale. To address this challenge, recent weakly- and self-supervised methods can learn feature descriptors from relative camera poses or using only synthetic rigid transformations such as homographies. In this work, we focus on understanding the limitations of existing self-supervised approaches and propose a set of improvements that combined lead to powerful feature descriptors. We show that increasing the search space from in-pair to in-batch for hard negative mining brings consistent improvement. To enhance the discriminativeness of feature descriptors, we propose a coarse-to-fine method for mining local hard negatives from a wider search space by using global visual image descriptors. We demonstrate that a combination of synthetic homography transformation, color augmentation, and photorealistic image stylization produces useful representations that are viewpoint and illumination invariant. The feature descriptors learned by the proposed approach perform competitively and surpass their fully- and weakly-supervised counterparts on various geometric benchmarks such as image-based localization, sparse feature matching, and image retrieval.
Continual Learning for Image-Based Camera Localization
Aug 20, 2021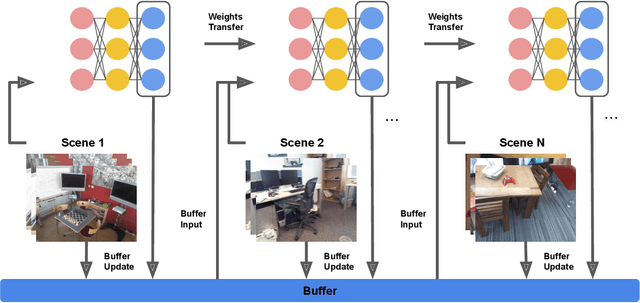

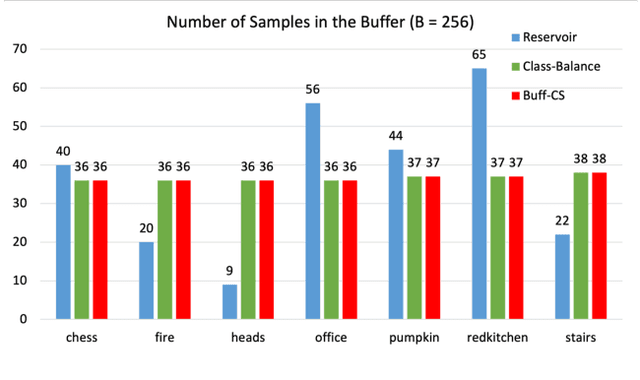

For several emerging technologies such as augmented reality, autonomous driving and robotics, visual localization is a critical component. Directly regressing camera pose/3D scene coordinates from the input image using deep neural networks has shown great potential. However, such methods assume a stationary data distribution with all scenes simultaneously available during training. In this paper, we approach the problem of visual localization in a continual learning setup -- whereby the model is trained on scenes in an incremental manner. Our results show that similar to the classification domain, non-stationary data induces catastrophic forgetting in deep networks for visual localization. To address this issue, a strong baseline based on storing and replaying images from a fixed buffer is proposed. Furthermore, we propose a new sampling method based on coverage score (Buff-CS) that adapts the existing sampling strategies in the buffering process to the problem of visual localization. Results demonstrate consistent improvements over standard buffering methods on two challenging datasets -- 7Scenes, 12Scenes, and also 19Scenes by combining the former scenes.