 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Ranking Distillation for Image Retrieval
Paper and Code
Jul 13, 2020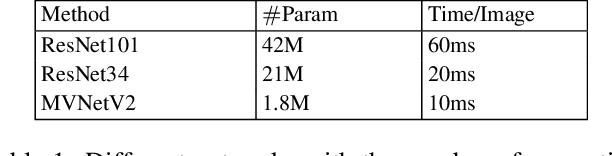

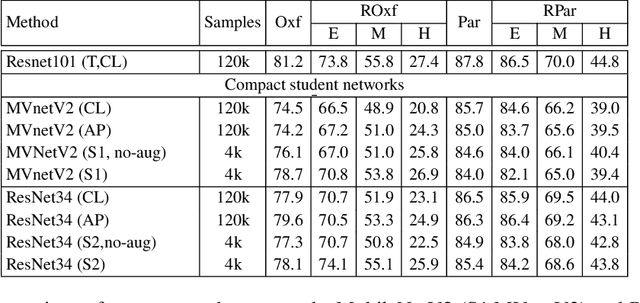

Recent advances in deep learning has lead to rapid developments in the field of image retrieval. However, the best performing architectures incur significant computational cost. Recent approaches tackle this issue using knowledge distillation to transfer knowledge from a deeper and heavier architecture to a much smaller network. In this paper we address knowledge distillation for metric learning problems. Unlike previous approaches, our proposed method jointly addresses the following constraints i) limited queries to teacher model, ii) black box teacher model with access to the final output representation, and iii) small fraction of original training data without any ground-truth labels. In addition, the distillation method does not require the student and teacher to have same dimensionality. Addressing these constraints reduces computation requirements, dependency on large-scale training datasets and addresses practical scenarios of limited or partial access to private data such as teacher models or the corresponding training data/labels. The key idea is to augment the original training set with additional samples by performing linear interpolation in the final output representation space. Distillation is then performed in the joint space of original and augmented teacher-student sample representations. Results demonstrate that our approach can match baseline models trained with full supervision. In low training sample settings, our approach outperforms the fully supervised approach on two challenging image retrieval datasets, ROxford5k and RParis6k \cite{Roxf} with the least possible teacher supervision.