 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Composed Image Retrieval for Applied Earth Observation
May 23, 2026Remote sensing composed image retrieval (RSCIR) enables search in large satellite image archives using composed queries that combine a reference image with a textual modifier. Although RSCIR offers a flexible interface for expressing targeted retrieval intent, the transferability of modern composition methods to Earth observation (EO) imagery and their relevance to operational EO workflows remain underexplored. We address this gap through a unified benchmark and an application-oriented study. First, we systematically adapt and evaluate representative composed image retrieval methods with six vision-language backbones on PatternCom under a standardized protocol, analyzing their behavior across backbones, composition strategies, and query types. Second, we introduce xView2-CIR, a change-centric dataset for disaster and damage monitoring, where retrieval is conditioned on scene identity and a target post-event state. Our results show that training-free composition methods provide strong and scalable baselines for EO retrieval, while change-centric retrieval presents different challenges from attribute-based retrieval, particularly due to the need to preserve scene identity. Overall, this study establishes a practical benchmark for RSCIR and positions composed retrieval as a complementary tool for remote sensing image retrieval, archive exploration, and change analysis. The dataset and code are available at https://github.com/billpsomas/rscir.
EchoVQA: Enabling Conversational Assistance for Point-of-Care Cardiac Ultrasound
May 22, 2026Point-of-care transthoracic echocardiography (TTE) enables cardiac assessment in virtually any clinical setting, yet its diagnostic utility remains constrained by the expertise required for image acquisition and interpretation. Visual question answering (VQA) offers a promising paradigm for bridging this expertise gap through interactive clinical assistance, but existing echocardiography VQA datasets are limited in scale, restricted to high-quality images, and only cover a few views. We introduce EchoVQA, the first large-scale VQA dataset for echocardiography, comprising 14,299 images and 74,819 question-answer pairs. The dataset integrates public sources (EchoNet-Dynamic, CAMUS) with our own point-of-care acquisitions from two handheld probes (Lumify, Clarius), spanning diverse views and including both high-quality and suboptimal images. Uniquely, EchoVQA includes acquisition guidance questions to help users optimize transducer positioning toward a diagnostic apical 4-chamber view for left ventricular ejection fraction estimation -- a challenging task for novice operators in point-of-care settings. We further develop a parameter-efficient method based on multimodal learnable prompts achieving state-of-the-art performance on most benchmarks, including EchoVQA, with significantly less trainable parameters than existing state-of-the-art approaches.
Deep TPC: Temporal-Prior Conditioning for Time Series Forecasting
Feb 18, 2026LLM-for-time series (TS) methods typically treat time shallowly, injecting positional or prompt-based cues once at the input of a largely frozen decoder, which limits temporal reasoning as this information degrades through the layers. We introduce Temporal-Prior Conditioning (TPC), which elevates time to a first-class modality that conditions the model at multiple depths. TPC attaches a small set of learnable time series tokens to the patch stream; at selected layers these tokens cross-attend to temporal embeddings derived from compact, human-readable temporal descriptors encoded by the same frozen LLM, then feed temporal context back via self-attention. This disentangles time series signal and temporal information while maintaining a low parameter budget. We show that by training only the cross-attention modules and explicitly disentangling time series signal and temporal information, TPC consistently outperforms both full fine-tuning and shallow conditioning strategies, achieving state-of-the-art performance in long-term forecasting across diverse datasets. Code available at: https://github.com/fil-mp/Deep_tpc
Attention, Please! Revisiting Attentive Probing for Masked Image Modeling
Jun 11, 2025As fine-tuning (FT) becomes increasingly impractical at scale, probing is emerging as the preferred evaluation protocol for self-supervised learning (SSL). Yet, the standard linear probing (LP) fails to adequately reflect the potential of models trained with Masked Image Modeling (MIM), due to the distributed nature of patch tokens. This motivates the need for attentive probing, an alternative that uses attention to selectively aggregate patch-level features. Despite its growing adoption, attentive probing remains under-explored, with existing methods suffering from excessive parameterization and poor computational efficiency. In this work, we revisit attentive probing through the lens of the accuracy-efficiency trade-off. We conduct a systematic study of existing methods, analyzing their mechanisms and benchmarking their performance. We introduce efficient probing (EP), a multi-query cross-attention mechanism that eliminates redundant projections, reduces the number of trainable parameters, and achieves up to a 10$\times$ speed-up over conventional multi-head attention. Despite its simplicity, EP outperforms LP and prior attentive probing approaches across seven benchmarks, generalizes well beyond MIM to diverse pre-training paradigms, produces interpretable attention maps, and achieves strong gains in low-shot and layer-wise settings. Code available at https://github.com/billpsomas/efficient-probing.
DeepMLF: Multimodal language model with learnable tokens for deep fusion in sentiment analysis
Apr 15, 2025While multimodal fusion has been extensively studied in Multimodal Sentiment Analysis (MSA), the role of fusion depth and multimodal capacity allocation remains underexplored. In this work, we position fusion depth, scalability, and dedicated multimodal capacity as primary factors for effective fusion. We introduce DeepMLF, a novel multimodal language model (LM) with learnable tokens tailored toward deep fusion. DeepMLF leverages an audiovisual encoder and a pretrained decoder LM augmented with multimodal information across its layers. We append learnable tokens to the LM that: 1) capture modality interactions in a controlled fashion and 2) preserve independent information flow for each modality. These fusion tokens gather linguistic information via causal self-attention in LM Blocks and integrate with audiovisual information through cross-attention MM Blocks. Serving as dedicated multimodal capacity, this design enables progressive fusion across multiple layers, providing depth in the fusion process. Our training recipe combines modality-specific losses and language modelling loss, with the decoder LM tasked to predict ground truth polarity. Across three MSA benchmarks with varying dataset characteristics, DeepMLF achieves state-of-the-art performance. Our results confirm that deeper fusion leads to better performance, with optimal fusion depths (5-7) exceeding those of existing approaches. Additionally, our analysis on the number of fusion tokens reveals that small token sets ($\sim$20) achieve optimal performance. We examine the importance of representation learning order (fusion curriculum) through audiovisual encoder initialization experiments. Our ablation studies demonstrate the superiority of the proposed fusion design and gating while providing a holistic examination of DeepMLF's scalability to LLMs, and the impact of each training objective and embedding regularization.
Composed Image Retrieval for Training-Free Domain Conversion
Dec 04, 2024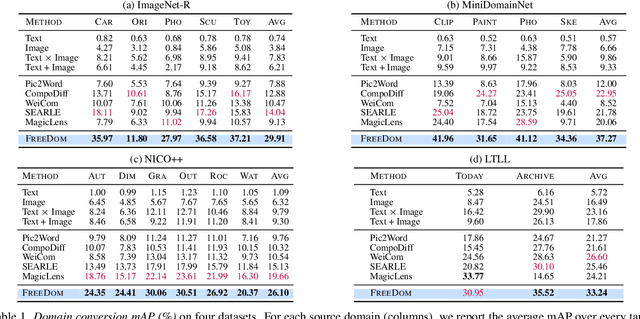


This work addresses composed image retrieval in the context of domain conversion, where the content of a query image is retrieved in the domain specified by the query text. We show that a strong vision-language model provides sufficient descriptive power without additional training. The query image is mapped to the text input space using textual inversion. Unlike common practice that invert in the continuous space of text tokens, we use the discrete word space via a nearest-neighbor search in a text vocabulary. With this inversion, the image is softly mapped across the vocabulary and is made more robust using retrieval-based augmentation. Database images are retrieved by a weighted ensemble of text queries combining mapped words with the domain text. Our method outperforms prior art by a large margin on standard and newly introduced benchmarks. Code: https://github.com/NikosEfth/freedom
Composed Image Retrieval for Remote Sensing
May 29, 2024
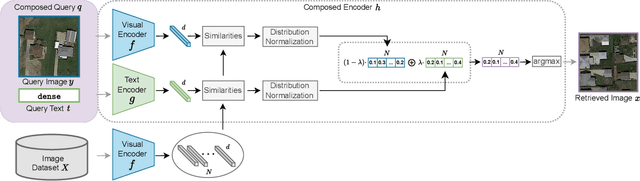


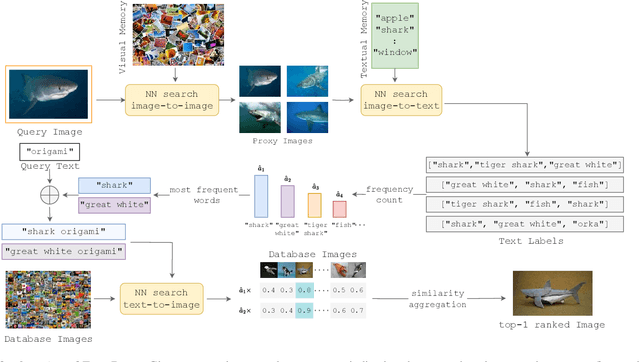
This work introduces composed image retrieval to remote sensing. It allows to query a large image archive by image examples alternated by a textual description, enriching the descriptive power over unimodal queries, either visual or textual. Various attributes can be modified by the textual part, such as shape, color, or context. A novel method fusing image-to-image and text-to-image similarity is introduced. We demonstrate that a vision-language model possesses sufficient descriptive power and no further learning step or training data are necessary. We present a new evaluation benchmark focused on color, context, density, existence, quantity, and shape modifications. Our work not only sets the state-of-the-art for this task, but also serves as a foundational step in addressing a gap in the field of remote sensing image retrieval. Code at: https://github.com/billpsomas/rscir
A Learning Paradigm for Interpretable Gradients
Apr 23, 2024


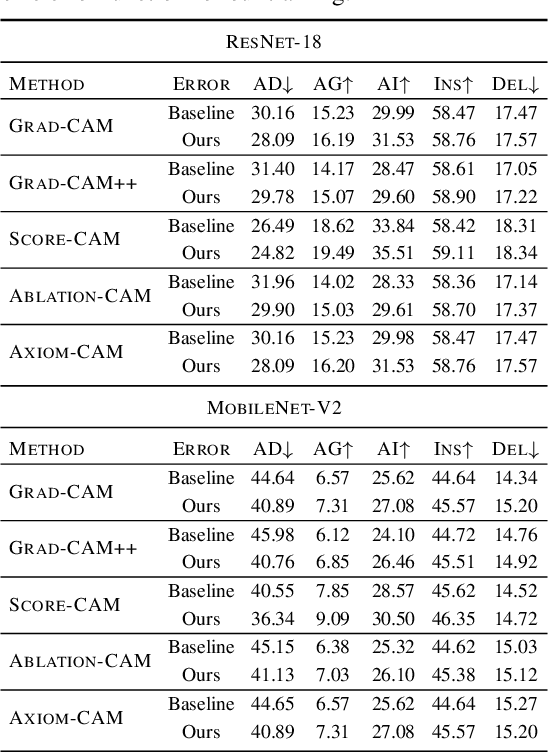
This paper studies interpretability of convolutional networks by means of saliency maps. Most approaches based on Class Activation Maps (CAM) combine information from fully connected layers and gradient through variants of backpropagation. However, it is well understood that gradients are noisy and alternatives like guided backpropagation have been proposed to obtain better visualization at inference. In this work, we present a novel training approach to improve the quality of gradients for interpretability. In particular, we introduce a regularization loss such that the gradient with respect to the input image obtained by standard backpropagation is similar to the gradient obtained by guided backpropagation. We find that the resulting gradient is qualitatively less noisy and improves quantitatively the interpretability properties of different networks, using several interpretability methods.
CA-Stream: Attention-based pooling for interpretable image recognition
Apr 23, 2024
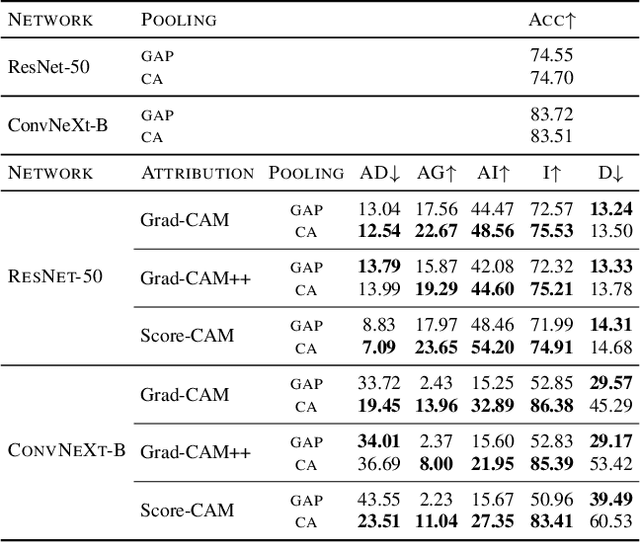

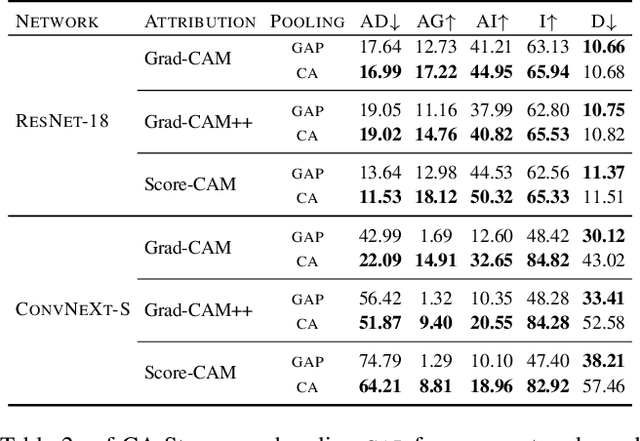
Explanations obtained from transformer-based architectures in the form of raw attention, can be seen as a class-agnostic saliency map. Additionally, attention-based pooling serves as a form of masking the in feature space. Motivated by this observation, we design an attention-based pooling mechanism intended to replace Global Average Pooling (GAP) at inference. This mechanism, called Cross-Attention Stream (CA-Stream), comprises a stream of cross attention blocks interacting with features at different network depths. CA-Stream enhances interpretability in models, while preserving recognition performance.
On Train-Test Class Overlap and Detection for Image Retrieval
Apr 01, 2024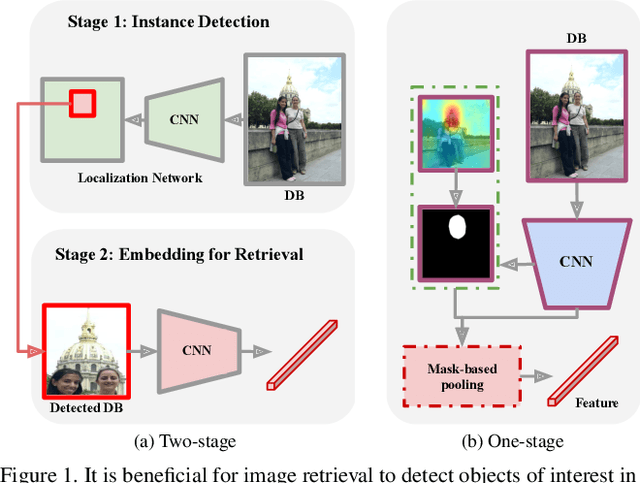



How important is it for training and evaluation sets to not have class overlap in image retrieval? We revisit Google Landmarks v2 clean, the most popular training set, by identifying and removing class overlap with Revisited Oxford and Paris [34], the most popular evaluation set. By comparing the original and the new RGLDv2-clean on a benchmark of reproduced state-of-the-art methods, our findings are striking. Not only is there a dramatic drop in performance, but it is inconsistent across methods, changing the ranking.What does it take to focus on objects or interest and ignore background clutter when indexing? Do we need to train an object detector and the representation separately? Do we need location supervision? We introduce Single-stage Detect-to-Retrieve (CiDeR), an end-to-end, single-stage pipeline to detect objects of interest and extract a global image representation. We outperform previous state-of-the-art on both existing training sets and the new RGLDv2-clean. Our dataset is available at https://github.com/dealicious-inc/RGLDv2-clean.