 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Masks Needed: Explainable AI for Deriving Segmentation from Classification
Aug 06, 2025Medical image segmentation is vital for modern healthcare and is a key element of computer-aided diagnosis. While recent advancements in computer vision have explored unsupervised segmentation using pre-trained models, these methods have not been translated well to the medical imaging domain. In this work, we introduce a novel approach that fine-tunes pre-trained models specifically for medical images, achieving accurate segmentation with extensive processing. Our method integrates Explainable AI to generate relevance scores, enhancing the segmentation process. Unlike traditional methods that excel in standard benchmarks but falter in medical applications, our approach achieves improved results on datasets like CBIS-DDSM, NuInsSeg and Kvasir-SEG.
Cluster Contrast for Unsupervised Visual Representation Learning
Jul 16, 2025We introduce Cluster Contrast (CueCo), a novel approach to unsupervised visual representation learning that effectively combines the strengths of contrastive learning and clustering methods. Inspired by recent advancements, CueCo is designed to simultaneously scatter and align feature representations within the feature space. This method utilizes two neural networks, a query and a key, where the key network is updated through a slow-moving average of the query outputs. CueCo employs a contrastive loss to push dissimilar features apart, enhancing inter-class separation, and a clustering objective to pull together features of the same cluster, promoting intra-class compactness. Our method achieves 91.40% top-1 classification accuracy on CIFAR-10, 68.56% on CIFAR-100, and 78.65% on ImageNet-100 using linear evaluation with a ResNet-18 backbone. By integrating contrastive learning with clustering, CueCo sets a new direction for advancing unsupervised visual representation learning.
Image compositing is all you need for data augmentation
Feb 19, 2025This paper investigates the impact of various data augmentation techniques on the performance of object detection models. Specifically, we explore classical augmentation methods, image compositing, and advanced generative models such as Stable Diffusion XL and ControlNet. The objective of this work is to enhance model robustness and improve detection accuracy, particularly when working with limited annotated data. Using YOLOv8, we fine-tune the model on a custom dataset consisting of commercial and military aircraft, applying different augmentation strategies. Our experiments show that image compositing offers the highest improvement in detection performance, as measured by precision, recall, and mean Average Precision (mAP@0.50). Other methods, including Stable Diffusion XL and ControlNet, also demonstrate significant gains, highlighting the potential of advanced data augmentation techniques for object detection tasks. The results underline the importance of dataset diversity and augmentation in achieving better generalization and performance in real-world applications. Future work will explore the integration of semi-supervised learning methods and further optimizations to enhance model performance across larger and more complex datasets.
Distilling Invariant Representations with Dual Augmentation
Oct 12, 2024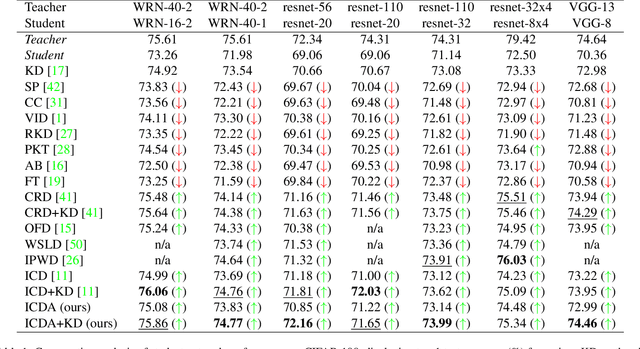
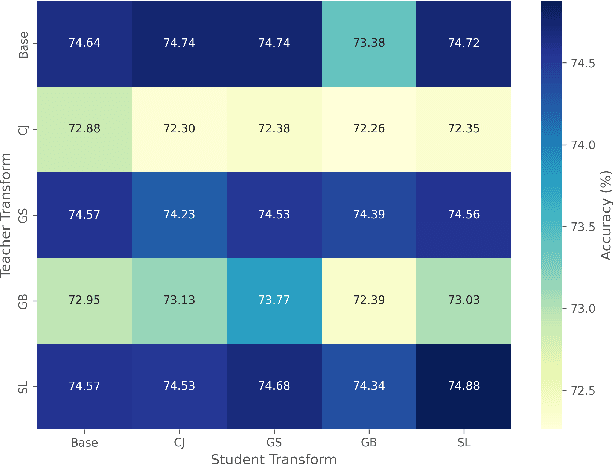
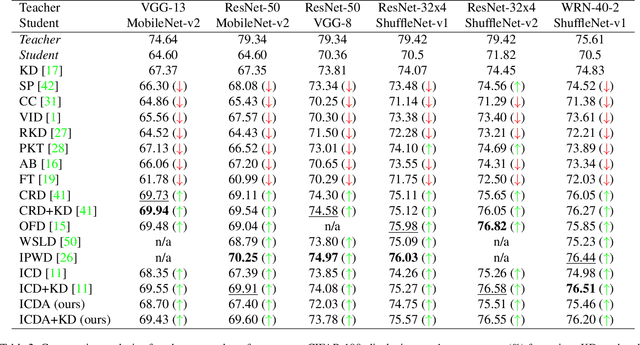

Knowledge distillation (KD) has been widely used to transfer knowledge from large, accurate models (teachers) to smaller, efficient ones (students). Recent methods have explored enforcing consistency by incorporating causal interpretations to distill invariant representations. In this work, we extend this line of research by introducing a dual augmentation strategy to promote invariant feature learning in both teacher and student models. Our approach leverages different augmentations applied to both models during distillation, pushing the student to capture robust, transferable features. This dual augmentation strategy complements invariant causal distillation by ensuring that the learned representations remain stable across a wider range of data variations and transformations. Extensive experiments on CIFAR-100 demonstrate the effectiveness of this approach, achieving competitive results in same-architecture KD.
SynCo: Synthetic Hard Negatives in Contrastive Learning for Better Unsupervised Visual Representations
Oct 03, 2024Contrastive learning has become a dominant approach in self-supervised visual representation learning, with hard negatives-samples that closely resemble the anchor-being key to enhancing the discriminative power of learned representations. However, efficiently leveraging hard negatives remains a challenge due to the difficulty in identifying and incorporating them without significantly increasing computational costs. To address this, we introduce SynCo (Synthetic Negatives in Contrastive learning), a novel contrastive learning approach that improves model performance by generating synthetic hard negatives. Built on the MoCo framework, SynCo introduces six novel strategies for creating diverse synthetic hard negatives that can be generated on-the-fly with minimal computational overhead. SynCo achieves faster training and better representation learning, achieving a top-1 accuracy of 68.1% in ImageNet linear evaluation after only 200 epochs on pretraining, surpassing MoCo's 67.5% with the same ResNet-50 encoder. Additionally, it transfers more effectively to detection tasks: on the PASCAL VOC, it outperforms both the supervised baseline and MoCo, achieving an AP of 82.5%; on the COCO dataset, it sets a new benchmark with 40.4% AP for bounding box detection and 35.4% AP for instance segmentation. Our synthetic hard negative generation procedure significantly enhances the quality of visual representations learned through self-supervised contrastive learning. Code is available at https://github.com/giakoumoglou/synco.
Passenger hazard perception based on EEG signals for highly automated driving vehicles
Aug 29, 2024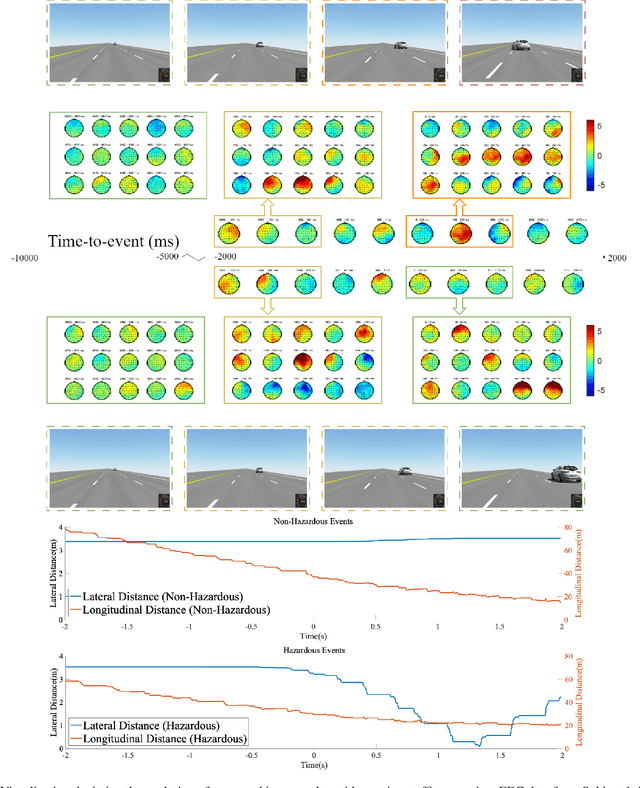
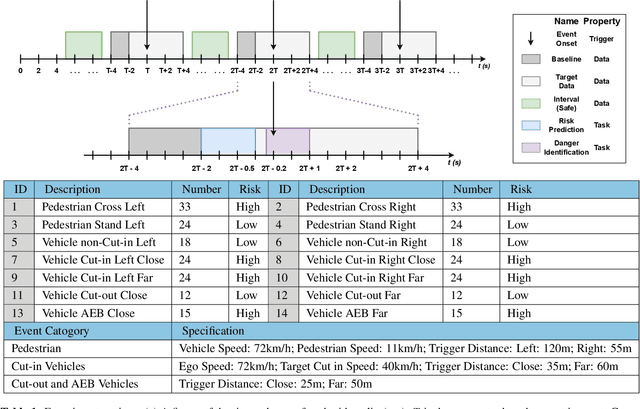
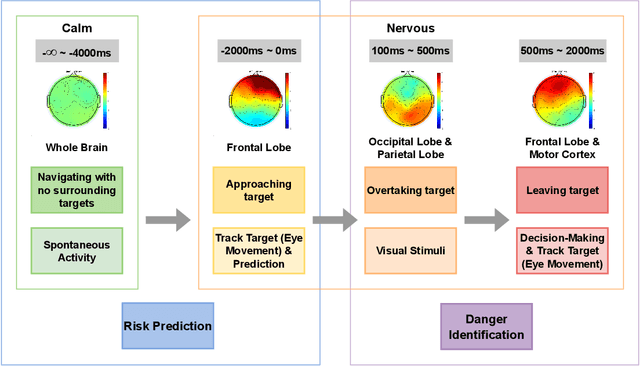
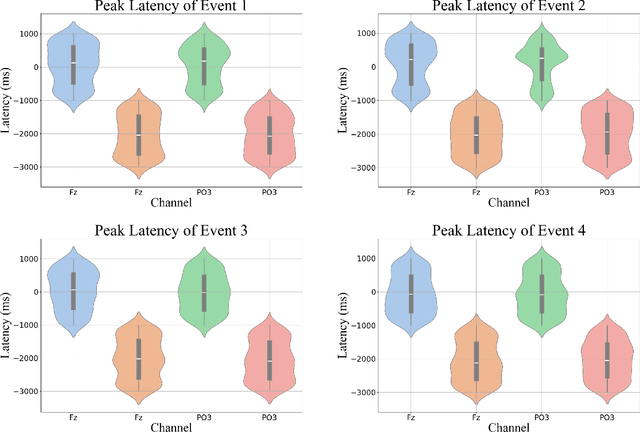
Enhancing the safety of autonomous vehicles is crucial, especially given recent accidents involving automated systems. As passengers in these vehicles, humans' sensory perception and decision-making can be integrated with autonomous systems to improve safety. This study explores neural mechanisms in passenger-vehicle interactions, leading to the development of a Passenger Cognitive Model (PCM) and the Passenger EEG Decoding Strategy (PEDS). Central to PEDS is a novel Convolutional Recurrent Neural Network (CRNN) that captures spatial and temporal EEG data patterns. The CRNN, combined with stacking algorithms, achieves an accuracy of $85.0\% \pm 3.18\%$. Our findings highlight the predictive power of pre-event EEG data, enhancing the detection of hazardous scenarios and offering a network-driven framework for safer autonomous vehicles.
Size Aware Cross-shape Scribble Supervision for Medical Image Segmentation
Aug 24, 2024



Scribble supervision, a common form of weakly supervised learning, involves annotating pixels using hand-drawn curve lines, which helps reduce the cost of manual labelling. This technique has been widely used in medical image segmentation tasks to fasten network training. However, scribble supervision has limitations in terms of annotation consistency across samples and the availability of comprehensive groundtruth information. Additionally, it often grapples with the challenge of accommodating varying scale targets, particularly in the context of medical images. In this paper, we propose three novel methods to overcome these challenges, namely, 1) the cross-shape scribble annotation method; 2) the pseudo mask method based on cross shapes; and 3) the size-aware multi-branch method. The parameter and structure design are investigated in depth. Experimental results show that the proposed methods have achieved significant improvement in mDice scores across multiple polyp datasets. Notably, the combination of these methods outperforms the performance of state-of-the-art scribble supervision methods designed for medical image segmentation.
Mean Height Aided Post-Processing for Pedestrian Detection
Aug 24, 2024The design of pedestrian detectors seldom considers the unique characteristics of this task and usually follows the common strategies for general object detection. To explore the potential of these characteristics, we take the perspective effect in pedestrian datasets as an example and propose the mean height aided suppression for post-processing. This method rejects predictions that fall at levels with a low possibility of containing any pedestrians or that have an abnormal height compared to the average. To achieve this, the existence score and mean height generators are proposed. Comprehensive experiments on various datasets and detectors are performed; the choice of hyper-parameters is discussed in depth. The proposed method is easy to implement and is plug-and-play. Results show that the proposed methods significantly improve detection accuracy when applied to different existing pedestrian detectors and datasets. The combination of mean height aided suppression with particular detectors outperforms state-of-the-art pedestrian detectors on Caltech and Citypersons datasets.
Relational Representation Distillation
Jul 19, 2024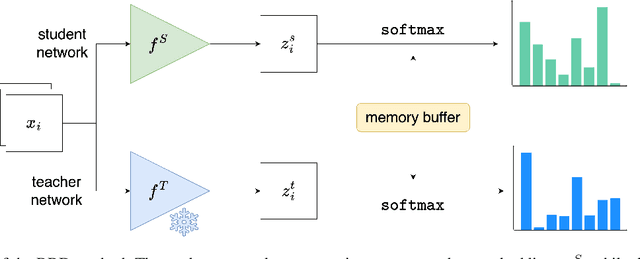
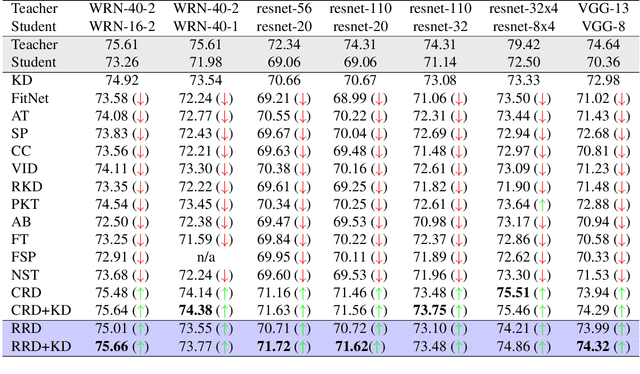
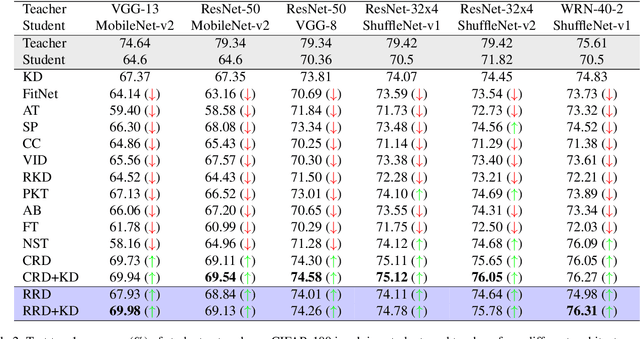
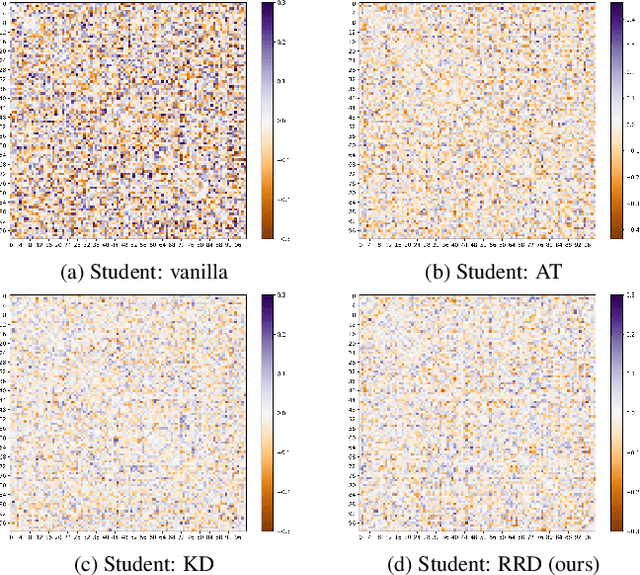
Knowledge distillation (KD) is an effective method for transferring knowledge from a large, well-trained teacher model to a smaller, more efficient student model. Despite its success, one of the main challenges in KD is ensuring the efficient transfer of complex knowledge while maintaining the student's computational efficiency. Unlike previous works that applied contrastive objectives promoting explicit negative instances, we introduce Relational Representation Distillation (RRD). Our approach leverages pairwise similarities to explore and reinforce the relationships between the teacher and student models. Inspired by self-supervised learning principles, it uses a relaxed contrastive loss that focuses on similarity rather than exact replication. This method aligns the output distributions of teacher samples in a large memory buffer, improving the robustness and performance of the student model without the need for strict negative instance differentiation. Our approach demonstrates superior performance on CIFAR-100, outperforming traditional KD techniques and surpassing 13 state-of-the-art methods. It also transfers successfully to other datasets like Tiny ImageNet and STL-10. The code will be made public soon.
Invariant Consistency for Knowledge Distillation
Jul 16, 2024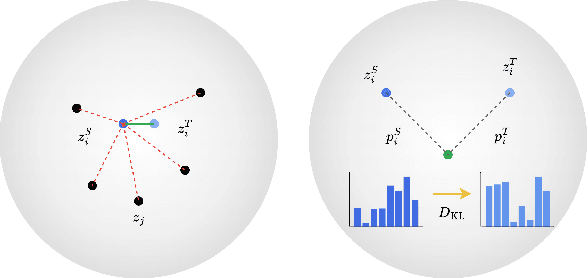
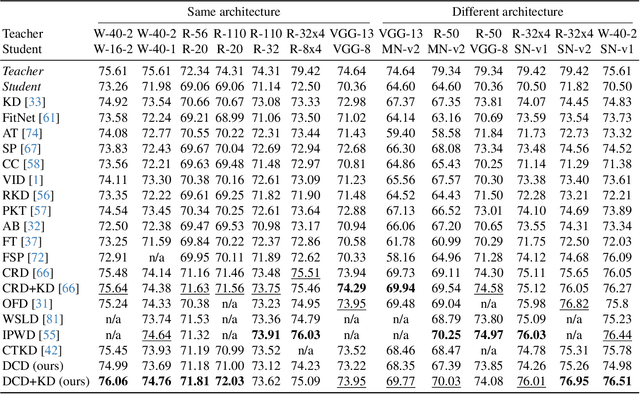

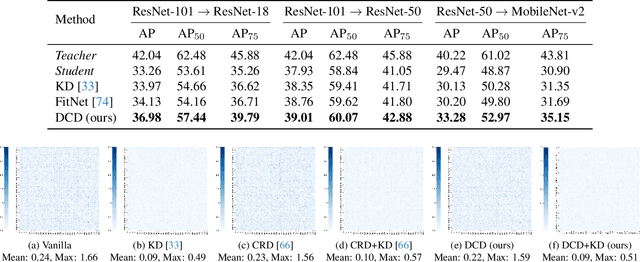
Knowledge distillation (KD) involves transferring the knowledge from one neural network to another, often from a larger, well-trained model (teacher) to a smaller, more efficient model (student). Traditional KD methods minimize the Kullback-Leibler (KL) divergence between the probabilistic outputs of the teacher and student networks. However, this approach often overlooks crucial structural knowledge embedded within the teacher's network. In this paper, we introduce Invariant Consistency Distillation (ICD), a novel methodology designed to enhance KD by ensuring that the student model's representations are consistent with those of the teacher. Our approach combines contrastive learning with an explicit invariance penalty, capturing significantly more information from the teacher's representation of the data. Our results on CIFAR-100 demonstrate that ICD outperforms traditional KD techniques and surpasses 13 state-of-the-art methods. In some cases, the student model even exceeds the teacher model in terms of accuracy. Furthermore, we successfully transfer our method to other datasets, including Tiny ImageNet and STL-10. The code will be made public soon.