 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Consistency for Knowledge Distillation
Paper and Code
Jul 16, 2024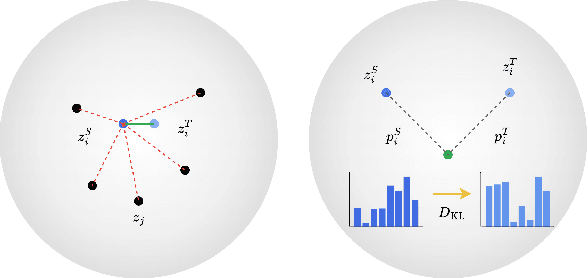
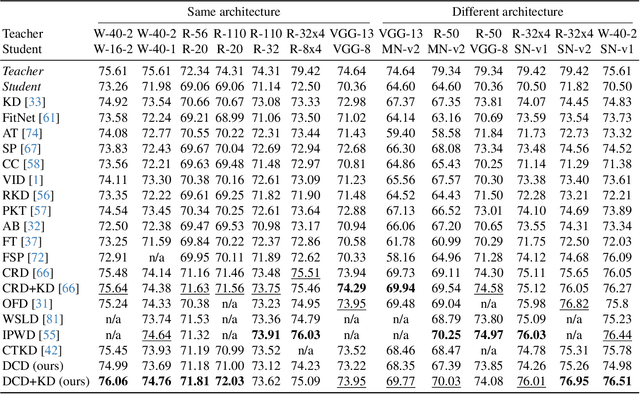

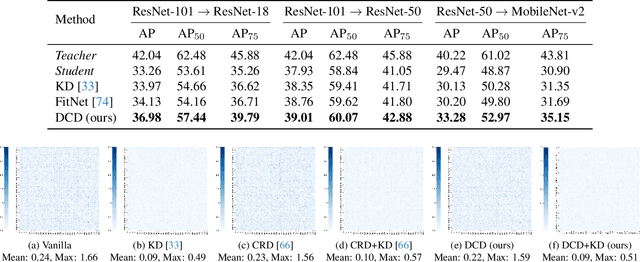
Knowledge distillation (KD) involves transferring the knowledge from one neural network to another, often from a larger, well-trained model (teacher) to a smaller, more efficient model (student). Traditional KD methods minimize the Kullback-Leibler (KL) divergence between the probabilistic outputs of the teacher and student networks. However, this approach often overlooks crucial structural knowledge embedded within the teacher's network. In this paper, we introduce Invariant Consistency Distillation (ICD), a novel methodology designed to enhance KD by ensuring that the student model's representations are consistent with those of the teacher. Our approach combines contrastive learning with an explicit invariance penalty, capturing significantly more information from the teacher's representation of the data. Our results on CIFAR-100 demonstrate that ICD outperforms traditional KD techniques and surpasses 13 state-of-the-art methods. In some cases, the student model even exceeds the teacher model in terms of accuracy. Furthermore, we successfully transfer our method to other datasets, including Tiny ImageNet and STL-10. The code will be made public soon.