 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster Contrast for Unsupervised Visual Representation Learning
Jul 16, 2025We introduce Cluster Contrast (CueCo), a novel approach to unsupervised visual representation learning that effectively combines the strengths of contrastive learning and clustering methods. Inspired by recent advancements, CueCo is designed to simultaneously scatter and align feature representations within the feature space. This method utilizes two neural networks, a query and a key, where the key network is updated through a slow-moving average of the query outputs. CueCo employs a contrastive loss to push dissimilar features apart, enhancing inter-class separation, and a clustering objective to pull together features of the same cluster, promoting intra-class compactness. Our method achieves 91.40% top-1 classification accuracy on CIFAR-10, 68.56% on CIFAR-100, and 78.65% on ImageNet-100 using linear evaluation with a ResNet-18 backbone. By integrating contrastive learning with clustering, CueCo sets a new direction for advancing unsupervised visual representation learning.
Distilling Invariant Representations with Dual Augmentation
Oct 12, 2024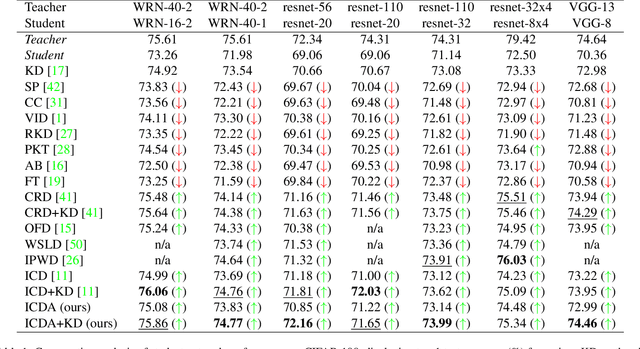
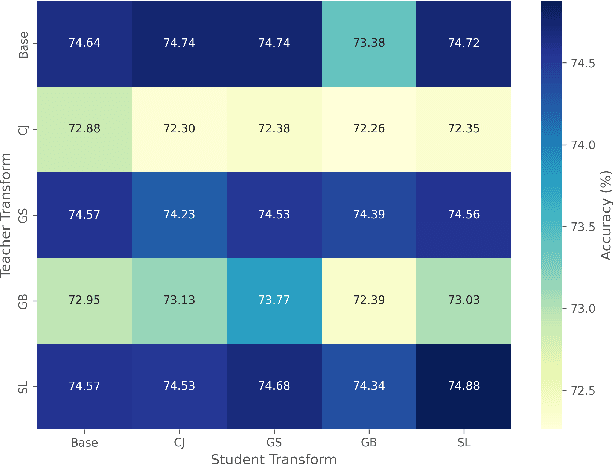
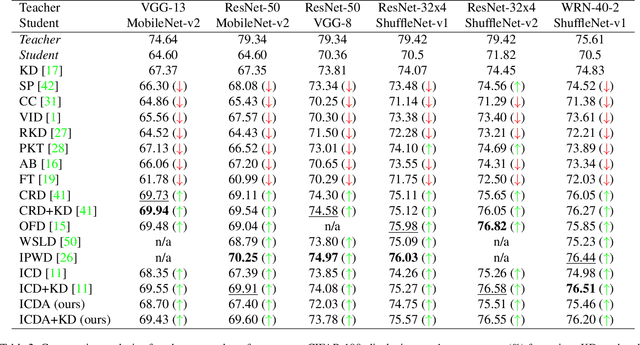

Knowledge distillation (KD) has been widely used to transfer knowledge from large, accurate models (teachers) to smaller, efficient ones (students). Recent methods have explored enforcing consistency by incorporating causal interpretations to distill invariant representations. In this work, we extend this line of research by introducing a dual augmentation strategy to promote invariant feature learning in both teacher and student models. Our approach leverages different augmentations applied to both models during distillation, pushing the student to capture robust, transferable features. This dual augmentation strategy complements invariant causal distillation by ensuring that the learned representations remain stable across a wider range of data variations and transformations. Extensive experiments on CIFAR-100 demonstrate the effectiveness of this approach, achieving competitive results in same-architecture KD.
SynCo: Synthetic Hard Negatives in Contrastive Learning for Better Unsupervised Visual Representations
Oct 03, 2024Contrastive learning has become a dominant approach in self-supervised visual representation learning, with hard negatives-samples that closely resemble the anchor-being key to enhancing the discriminative power of learned representations. However, efficiently leveraging hard negatives remains a challenge due to the difficulty in identifying and incorporating them without significantly increasing computational costs. To address this, we introduce SynCo (Synthetic Negatives in Contrastive learning), a novel contrastive learning approach that improves model performance by generating synthetic hard negatives. Built on the MoCo framework, SynCo introduces six novel strategies for creating diverse synthetic hard negatives that can be generated on-the-fly with minimal computational overhead. SynCo achieves faster training and better representation learning, achieving a top-1 accuracy of 68.1% in ImageNet linear evaluation after only 200 epochs on pretraining, surpassing MoCo's 67.5% with the same ResNet-50 encoder. Additionally, it transfers more effectively to detection tasks: on the PASCAL VOC, it outperforms both the supervised baseline and MoCo, achieving an AP of 82.5%; on the COCO dataset, it sets a new benchmark with 40.4% AP for bounding box detection and 35.4% AP for instance segmentation. Our synthetic hard negative generation procedure significantly enhances the quality of visual representations learned through self-supervised contrastive learning. Code is available at https://github.com/giakoumoglou/synco.
Relational Representation Distillation
Jul 19, 2024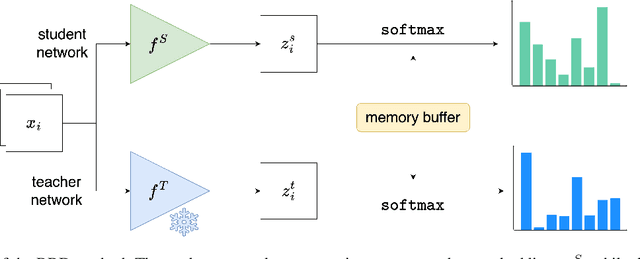
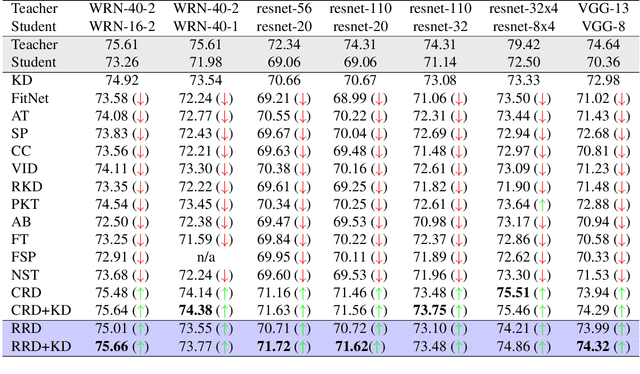
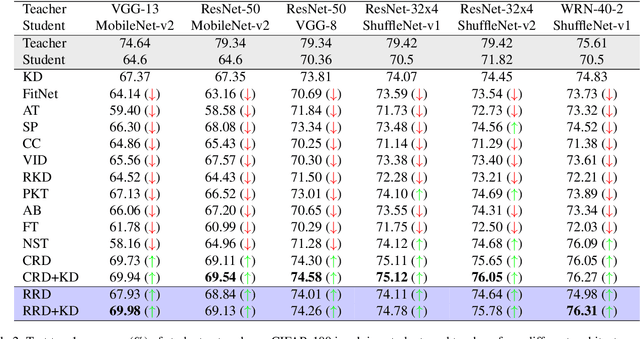
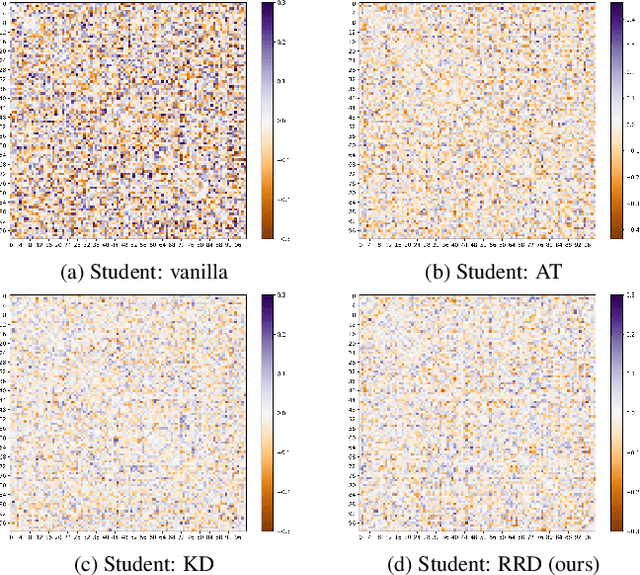
Knowledge distillation (KD) is an effective method for transferring knowledge from a large, well-trained teacher model to a smaller, more efficient student model. Despite its success, one of the main challenges in KD is ensuring the efficient transfer of complex knowledge while maintaining the student's computational efficiency. Unlike previous works that applied contrastive objectives promoting explicit negative instances, we introduce Relational Representation Distillation (RRD). Our approach leverages pairwise similarities to explore and reinforce the relationships between the teacher and student models. Inspired by self-supervised learning principles, it uses a relaxed contrastive loss that focuses on similarity rather than exact replication. This method aligns the output distributions of teacher samples in a large memory buffer, improving the robustness and performance of the student model without the need for strict negative instance differentiation. Our approach demonstrates superior performance on CIFAR-100, outperforming traditional KD techniques and surpassing 13 state-of-the-art methods. It also transfers successfully to other datasets like Tiny ImageNet and STL-10. The code will be made public soon.
Invariant Consistency for Knowledge Distillation
Jul 16, 2024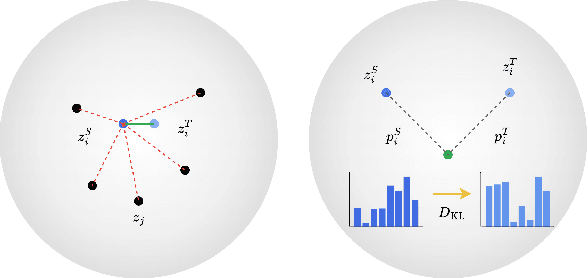
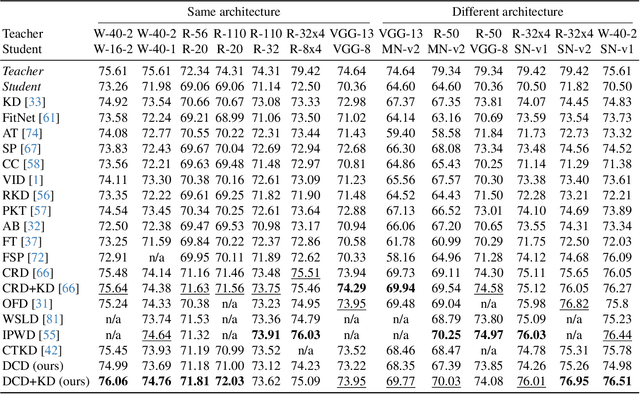

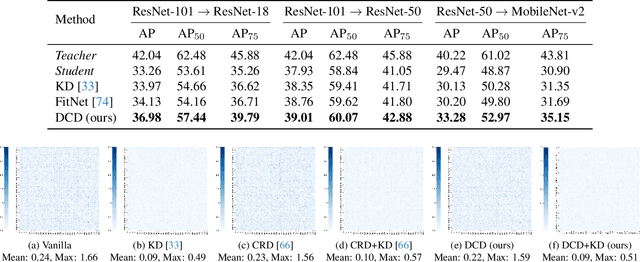
Knowledge distillation (KD) involves transferring the knowledge from one neural network to another, often from a larger, well-trained model (teacher) to a smaller, more efficient model (student). Traditional KD methods minimize the Kullback-Leibler (KL) divergence between the probabilistic outputs of the teacher and student networks. However, this approach often overlooks crucial structural knowledge embedded within the teacher's network. In this paper, we introduce Invariant Consistency Distillation (ICD), a novel methodology designed to enhance KD by ensuring that the student model's representations are consistent with those of the teacher. Our approach combines contrastive learning with an explicit invariance penalty, capturing significantly more information from the teacher's representation of the data. Our results on CIFAR-100 demonstrate that ICD outperforms traditional KD techniques and surpasses 13 state-of-the-art methods. In some cases, the student model even exceeds the teacher model in terms of accuracy. Furthermore, we successfully transfer our method to other datasets, including Tiny ImageNet and STL-10. The code will be made public soon.
A review on discriminative self-supervised learning methods
May 08, 2024
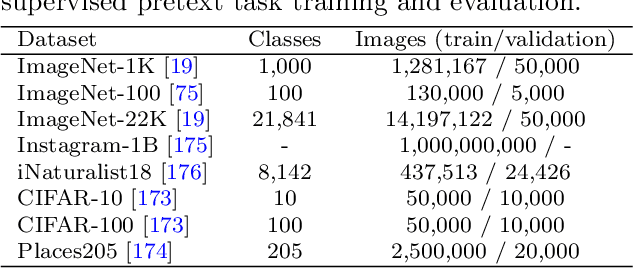

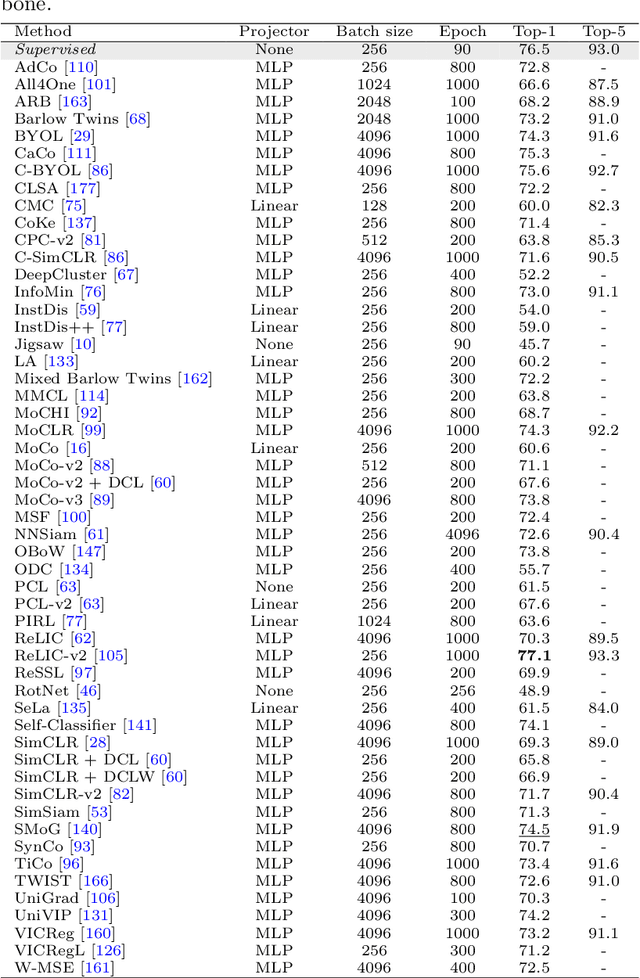
In the field of computer vision, self-supervised learning has emerged as a method to extract robust features from unlabeled data, where models derive labels autonomously from the data itself, without the need for manual annotation. This paper provides a comprehensive review of discriminative approaches of self-supervised learning within the domain of computer vision, examining their evolution and current status. Through an exploration of various methods including contrastive, self-distillation, knowledge distillation, feature decorrelation, and clustering techniques, we investigate how these approaches leverage the abundance of unlabeled data. Finally, we have comparison of self-supervised learning methods on the standard ImageNet classification benchmark.