 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Invariant Representations with Dual Augmentation
Paper and Code
Oct 12, 2024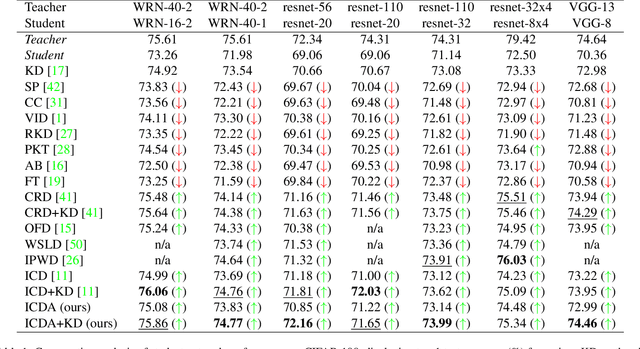
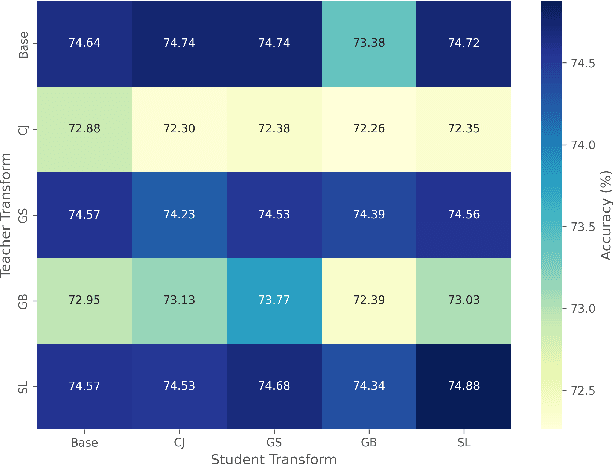
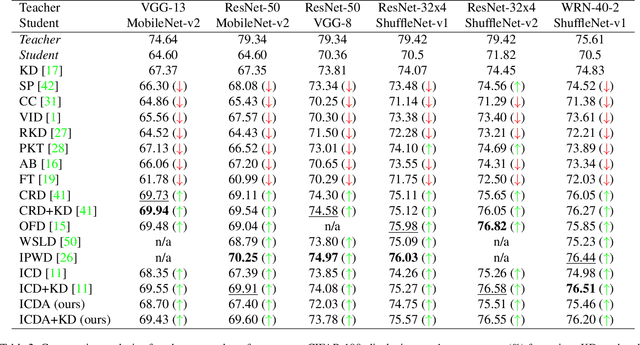

Knowledge distillation (KD) has been widely used to transfer knowledge from large, accurate models (teachers) to smaller, efficient ones (students). Recent methods have explored enforcing consistency by incorporating causal interpretations to distill invariant representations. In this work, we extend this line of research by introducing a dual augmentation strategy to promote invariant feature learning in both teacher and student models. Our approach leverages different augmentations applied to both models during distillation, pushing the student to capture robust, transferable features. This dual augmentation strategy complements invariant causal distillation by ensuring that the learned representations remain stable across a wider range of data variations and transformations. Extensive experiments on CIFAR-100 demonstrate the effectiveness of this approach, achieving competitive results in same-architecture KD.