 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndroTMem: From Interaction Trajectories to Anchored Memory in Long-Horizon GUI Agents
Mar 19, 2026Long-horizon GUI agents are a key step toward real-world deployment, yet effective interaction memory under prevailing paradigms remains under-explored. Replaying full interaction sequences is redundant and amplifies noise, while summaries often erase dependency-critical information and traceability. We present AndroTMem, a diagnostic framework for anchored memory in long-horizon Android GUI agents. Its core benchmark, AndroTMem-Bench, comprises 1,069 tasks with 34,473 interaction steps (avg. 32.1 per task, max. 65). We evaluate agents with TCR (Task Complete Rate), focusing on tasks whose completion requires carrying forward critical intermediate state; AndroTMem-Bench is designed to enforce strong step-to-step causal dependencies, making sparse yet essential intermediate states decisive for downstream actions and centering interaction memory in evaluation. Across open- and closed-source GUI agents, we observe a consistent pattern: as interaction sequences grow longer, performance drops are driven mainly by within-task memory failures, not isolated perception errors or local action mistakes. Guided by this diagnosis, we propose Anchored State Memory (ASM), which represents interaction sequences as a compact set of causally linked intermediate-state anchors to enable subgoal-targeted retrieval and attribution-aware decision making. Across multiple settings and 12 evaluated GUI agents, ASM consistently outperforms full-sequence replay and summary-based baselines, improving TCR by 5%-30.16% and AMS by 4.93%-24.66%, indicating that anchored, structured memory effectively mitigates the interaction-memory bottleneck in long-horizon GUI tasks. The code, benchmark, and related resources are publicly available at [https://github.com/CVC2233/AndroTMem](https://github.com/CVC2233/AndroTMem).
A Two-Stage GPU Kernel Tuner Combining Semantic Refactoring and Search-Based Optimization
Jan 21, 2026GPU code optimization is a key performance bottleneck for HPC workloads as well as large-model training and inference. Although compiler optimizations and hand-written kernels can partially alleviate this issue, achieving near-hardware-limit performance still relies heavily on manual code refactoring and parameter tuning. Recent progress in LLM-agent-based kernel generation and optimization has been reported, yet many approaches primarily focus on direct code rewriting, where parameter choices are often implicit and hard to control, or require human intervention, leading to unstable performance gains. This paper introduces a template-based rewriting layer on top of an agent-driven iterative loop: kernels are semantically refactored into explicitly parameterizable templates, and template parameters are then optimized via search-based autotuning, yielding more stable and higher-quality speedups. Experiments on a set of real-world kernels demonstrate speedups exceeding 3x in the best case. We extract representative CUDA kernels from SGLang as evaluation targets; the proposed agentic tuner iteratively performs templating, testing, analysis, and planning, and leverages profiling feedback to execute constrained parameter search under hardware resource limits. Compared to agent-only direct rewriting, the template-plus-search design significantly reduces the randomness of iterative optimization, making the process more interpretable and enabling a more systematic approach toward high-performance configurations. The proposed method can be further extended to OpenCL, HIP, and other backends to deliver automated performance optimization for real production workloads.
Joint DOA and Non-circular Phase Estimation of Non-circular Signals for Antenna Arrays: Block Sparse Bayesian Learning Method
Jan 14, 2026This letter proposes a block sparse Bayesian learning (BSBL) algorithm of non-circular (NC) signals for direction-of-arrival (DOA) estimation, which is suitable for arbitrary unknown NC phases. The block sparse NC signal representation model is constructed through a permutation strategy, capturing the available intra-block structure information to enhance recovery performance. After that, we create the sparse probability model and derive the cost function under BSBL framework. Finally, the fast marginal likelihood maximum (FMLM) algorithm is introduced, enabling the rapid implementation of signal recovery by the addition and removal of basis functions. Simulation results demonstrate the effectiveness and the superior performance of our proposed method.
Passenger hazard perception based on EEG signals for highly automated driving vehicles
Aug 29, 2024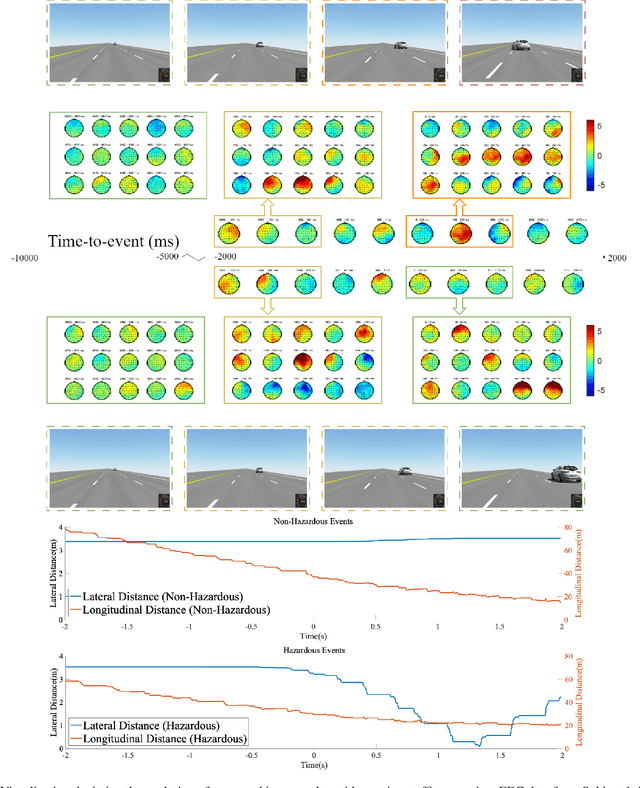
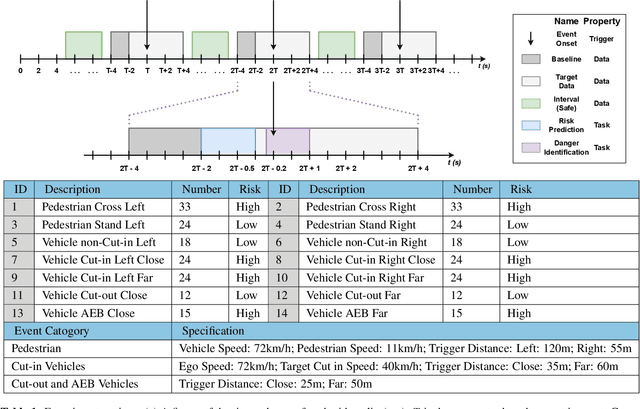
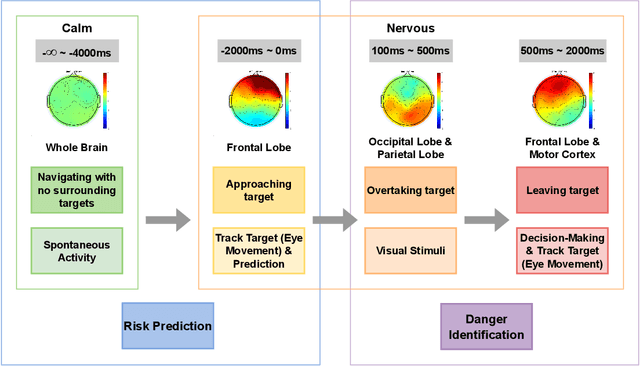
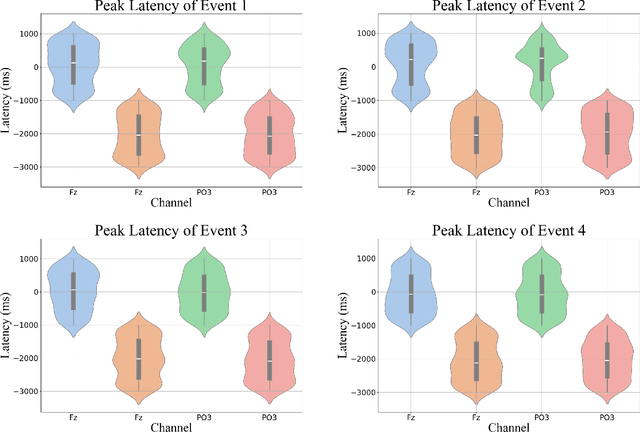
Enhancing the safety of autonomous vehicles is crucial, especially given recent accidents involving automated systems. As passengers in these vehicles, humans' sensory perception and decision-making can be integrated with autonomous systems to improve safety. This study explores neural mechanisms in passenger-vehicle interactions, leading to the development of a Passenger Cognitive Model (PCM) and the Passenger EEG Decoding Strategy (PEDS). Central to PEDS is a novel Convolutional Recurrent Neural Network (CRNN) that captures spatial and temporal EEG data patterns. The CRNN, combined with stacking algorithms, achieves an accuracy of $85.0\% \pm 3.18\%$. Our findings highlight the predictive power of pre-event EEG data, enhancing the detection of hazardous scenarios and offering a network-driven framework for safer autonomous vehicles.
InScope: A New Real-world 3D Infrastructure-side Collaborative Perception Dataset for Open Traffic Scenarios
Jul 31, 2024



Perception systems of autonomous vehicles are susceptible to occlusion, especially when examined from a vehicle-centric perspective. Such occlusion can lead to overlooked object detections, e.g., larger vehicles such as trucks or buses may create blind spots where cyclists or pedestrians could be obscured, accentuating the safety concerns associated with such perception system limitations. To mitigate these challenges, the vehicle-to-everything (V2X) paradigm suggests employing an infrastructure-side perception system (IPS) to complement autonomous vehicles with a broader perceptual scope. Nevertheless, the scarcity of real-world 3D infrastructure-side datasets constrains the advancement of V2X technologies. To bridge these gaps, this paper introduces a new 3D infrastructure-side collaborative perception dataset, abbreviated as inscope. Notably, InScope is the first dataset dedicated to addressing occlusion challenges by strategically deploying multiple-position Light Detection and Ranging (LiDAR) systems on the infrastructure side. Specifically, InScope encapsulates a 20-day capture duration with 303 tracking trajectories and 187,787 3D bounding boxes annotated by experts. Through analysis of benchmarks, four different benchmarks are presented for open traffic scenarios, including collaborative 3D object detection, multisource data fusion, data domain transfer, and 3D multiobject tracking tasks. Additionally, a new metric is designed to quantify the impact of occlusion, facilitating the evaluation of detection degradation ratios among various algorithms. The Experimental findings showcase the enhanced performance of leveraging InScope to assist in detecting and tracking 3D multiobjects in real-world scenarios, particularly in tracking obscured, small, and distant objects. The dataset and benchmarks are available at https://github.com/xf-zh/InScope.
Towards Explainable Artificial Intelligence (XAI): A Data Mining Perspective
Jan 13, 2024



Given the complexity and lack of transparency in deep neural networks (DNNs), extensive efforts have been made to make these systems more interpretable or explain their behaviors in accessible terms. Unlike most reviews, which focus on algorithmic and model-centric perspectives, this work takes a "data-centric" view, examining how data collection, processing, and analysis contribute to explainable AI (XAI). We categorize existing work into three categories subject to their purposes: interpretations of deep models, referring to feature attributions and reasoning processes that correlate data points with model outputs; influences of training data, examining the impact of training data nuances, such as data valuation and sample anomalies, on decision-making processes; and insights of domain knowledge, discovering latent patterns and fostering new knowledge from data and models to advance social values and scientific discovery. Specifically, we distill XAI methodologies into data mining operations on training and testing data across modalities, such as images, text, and tabular data, as well as on training logs, checkpoints, models and other DNN behavior descriptors. In this way, our study offers a comprehensive, data-centric examination of XAI from a lens of data mining methods and applications.
Efficient Sparse Least Absolute Deviation Regression with Differential Privacy
Jan 02, 2024



In recent years, privacy-preserving machine learning algorithms have attracted increasing attention because of their important applications in many scientific fields. However, in the literature, most privacy-preserving algorithms demand learning objectives to be strongly convex and Lipschitz smooth, which thus cannot cover a wide class of robust loss functions (e.g., quantile/least absolute loss). In this work, we aim to develop a fast privacy-preserving learning solution for a sparse robust regression problem. Our learning loss consists of a robust least absolute loss and an $\ell_1$ sparse penalty term. To fast solve the non-smooth loss under a given privacy budget, we develop a Fast Robust And Privacy-Preserving Estimation (FRAPPE) algorithm for least absolute deviation regression. Our algorithm achieves a fast estimation by reformulating the sparse LAD problem as a penalized least square estimation problem and adopts a three-stage noise injection to guarantee the $(\epsilon,\delta)$-differential privacy. We show that our algorithm can achieve better privacy and statistical accuracy trade-off compared with the state-of-the-art privacy-preserving regression algorithms. In the end, we conduct experiments to verify the efficiency of our proposed FRAPPE algorithm.
Dual Radar: A Multi-modal Dataset with Dual 4D Radar for Autonomous Driving
Oct 23, 2023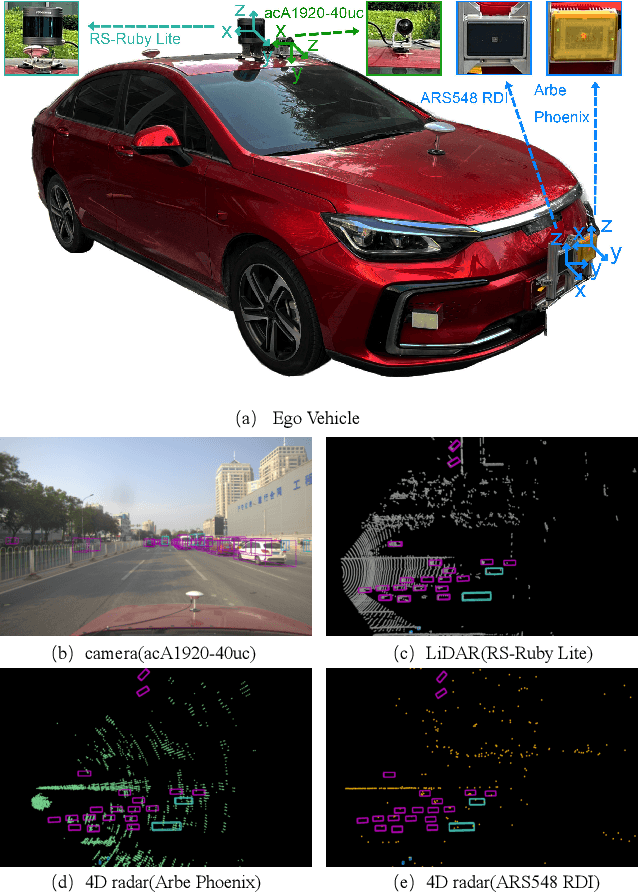
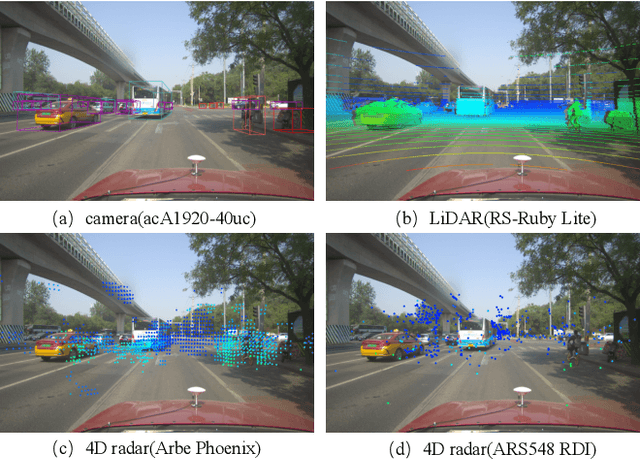
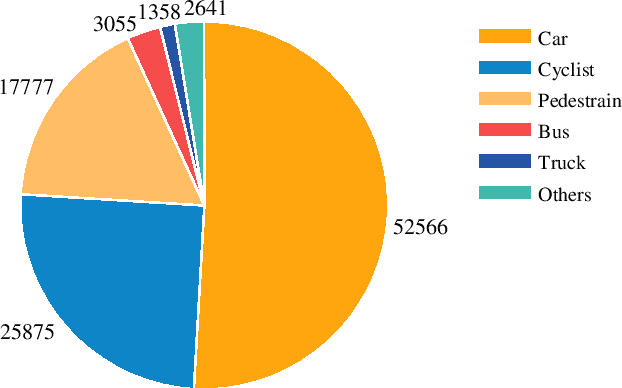
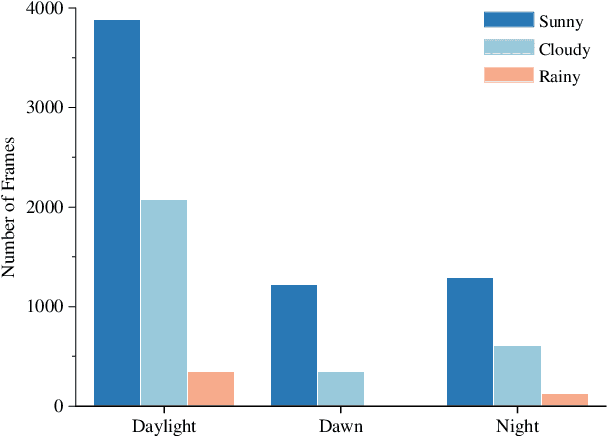
Radar has stronger adaptability in adverse scenarios for autonomous driving environmental perception compared to widely adopted cameras and LiDARs. Compared with commonly used 3D radars, the latest 4D radars have precise vertical resolution and higher point cloud density, making it a highly promising sensor for autonomous driving in complex environmental perception. However, due to the much higher noise than LiDAR, manufacturers choose different filtering strategies, resulting in an inverse ratio between noise level and point cloud density. There is still a lack of comparative analysis on which method is beneficial for deep learning-based perception algorithms in autonomous driving. One of the main reasons is that current datasets only adopt one type of 4D radar, making it difficult to compare different 4D radars in the same scene. Therefore, in this paper, we introduce a novel large-scale multi-modal dataset featuring, for the first time, two types of 4D radars captured simultaneously. This dataset enables further research into effective 4D radar perception algorithms.Our dataset consists of 151 consecutive series, most of which last 20 seconds and contain 10,007 meticulously synchronized and annotated frames. Moreover, our dataset captures a variety of challenging driving scenarios, including many road conditions, weather conditions, nighttime and daytime with different lighting intensities and periods. Our dataset annotates consecutive frames, which can be applied to 3D object detection and tracking, and also supports the study of multi-modal tasks. We experimentally validate our dataset, providing valuable results for studying different types of 4D radars. This dataset is released on https://github.com/adept-thu/Dual-Radar.
Natural Language based Context Modeling and Reasoning with LLMs: A Tutorial
Sep 24, 2023Large language models (LLMs) have become phenomenally surging, since 2018--two decades after introducing context-awareness into computing systems. Through taking into account the situations of ubiquitous devices, users and the societies, context-aware computing has enabled a wide spectrum of innovative applications, such as assisted living, location-based social network services and so on. To recognize contexts and make decisions for actions accordingly, various artificial intelligence technologies, such as Ontology and OWL, have been adopted as representations for context modeling and reasoning. Recently, with the rise of LLMs and their improved natural language understanding and reasoning capabilities, it has become feasible to model contexts using natural language and perform context reasoning by interacting with LLMs such as ChatGPT and GPT-4. In this tutorial, we demonstrate the use of texts, prompts, and autonomous agents (AutoAgents) that enable LLMs to perform context modeling and reasoning without requiring fine-tuning of the model. We organize and introduce works in the related field, and name this computing paradigm as the LLM-driven Context-aware Computing (LCaC). In the LCaC paradigm, users' requests, sensors reading data, and the command to actuators are supposed to be represented as texts. Given the text of users' request and sensor data, the AutoAgent models the context by prompting and sends to the LLM for context reasoning. LLM generates a plan of actions and responds to the AutoAgent, which later follows the action plan to foster context-awareness. To prove the concepts, we use two showcases--(1) operating a mobile z-arm in an apartment for assisted living, and (2) planning a trip and scheduling the itinerary in a context-aware and personalized manner.
Efficient Quality-Diversity Optimization through Diverse Quality Species
Apr 14, 2023



A prevalent limitation of optimizing over a single objective is that it can be misguided, becoming trapped in local optimum. This can be rectified by Quality-Diversity (QD) algorithms, where a population of high-quality and diverse solutions to a problem is preferred. Most conventional QD approaches, for example, MAP-Elites, explicitly manage a behavioral archive where solutions are broken down into predefined niches. In this work, we show that a diverse population of solutions can be found without the limitation of needing an archive or defining the range of behaviors in advance. Instead, we break down solutions into independently evolving species and use unsupervised skill discovery to learn diverse, high-performing solutions. We show that this can be done through gradient-based mutations that take on an information theoretic perspective of jointly maximizing mutual information and performance. We propose Diverse Quality Species (DQS) as an alternative to archive-based QD algorithms. We evaluate it over several simulated robotic environments and show that it can learn a diverse set of solutions from varying species. Furthermore, our results show that DQS is more sample-efficient and performant when compared to other QD algorithms. Relevant code and hyper-parameters are available at: https://github.com/rwickman/NEAT_RL.