 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFix the Loss, Not the Radius: Rethinking the Adversarial Perturbation of Sharpness-Aware Minimization
May 11, 2026Sharpness-Aware Minimization (SAM) improves generalization by minimizing the worst-case loss within a fixed parameter-space radius neighborhood. SAM and its variants mainly rely on a first-order linearized surrogate, while flat minima are inherently a second-order (curvature) notion.We revisit this mismatch and propose Loss-Equated SAM (LE-SAM), which inverts the traditional SAM mechanism that fixed perturbation radius with a fixed loss-space budget,effectively removing gradient-norm-dominated learning signals and shifting optimization toward curvature-dominated terms. Extensive experiments across diverse benchmarks and tasks demonstrate the strong generalization ability of LESAM that consistently outperforms SAM and even its variants, achieving the state-of-the-art performance.
Rethinking Loss Reweighting for Imbalance Learning as an Inverse Problem: A Neural Collapse Point of View
May 11, 2026Loss reweighting is a widely used strategy for long-tailed classification, but existing reweighting strategies often rely on heuristics and rarely define a well-specified target. Inspired by Neural Collapse (NC), the ideal simplex Equiangular Tight Frame (ETF) terminal geometry suggests equal per-class average loss as a reasonable target for reweighting. Based on the ideal equal loss objective, we consider loss reweighting as an inverse problem and propose an inverse-view reweighting strategy that infers class weights dynamically to match this ideal objective. Empirically, NC metrics suggest our method can effectively reduce the loss imbalance coefficient and closer alignment with NC geometry while consistently outperforming strong long-tailed baselines on different datasets.
Seeing the Scene Matters: Revealing Forgetting in Video Understanding Models with a Scene-Aware Long-Video Benchmark
Mar 28, 2026Long video understanding (LVU) remains a core challenge in multimodal learning. Although recent vision-language models (VLMs) have made notable progress, existing benchmarks mainly focus on either fine-grained perception or coarse summarization, offering limited insight into temporal understanding over long contexts. In this work, we define a scene as a coherent segment of a video in which both visual and semantic contexts remain consistent, aligning with human perception. This leads us to a key question: can current VLMs reason effectively over long, scene-level contexts? To answer this, we introduce a new benchmark, SceneBench, designed to provide scene-level challenges. Our evaluation reveals a sharp drop in accuracy when VLMs attempt to answer scene-level questions, indicating significant forgetting of long-range context. To further validate these findings, we propose Scene Retrieval-Augmented Generation (Scene-RAG), which constructs a dynamic scene memory by retrieving and integrating relevant context across scenes. This Scene-RAG improves VLM performance by +2.50%, confirming that current models still struggle with long-context retention. We hope SceneBench will encourage future research toward VLMs with more robust, human-like video comprehension.
FusDreamer: Label-efficient Remote Sensing World Model for Multimodal Data Classification
Mar 18, 2025World models significantly enhance hierarchical understanding, improving data integration and learning efficiency. To explore the potential of the world model in the remote sensing (RS) field, this paper proposes a label-efficient remote sensing world model for multimodal data fusion (FusDreamer). The FusDreamer uses the world model as a unified representation container to abstract common and high-level knowledge, promoting interactions across different types of data, \emph{i.e.}, hyperspectral (HSI), light detection and ranging (LiDAR), and text data. Initially, a new latent diffusion fusion and multimodal generation paradigm (LaMG) is utilized for its exceptional information integration and detail retention capabilities. Subsequently, an open-world knowledge-guided consistency projection (OK-CP) module incorporates prompt representations for visually described objects and aligns language-visual features through contrastive learning. In this way, the domain gap can be bridged by fine-tuning the pre-trained world models with limited samples. Finally, an end-to-end multitask combinatorial optimization (MuCO) strategy can capture slight feature bias and constrain the diffusion process in a collaboratively learnable direction. Experiments conducted on four typical datasets indicate the effectiveness and advantages of the proposed FusDreamer. The corresponding code will be released at https://github.com/Cimy-wang/FusDreamer.
InScope: A New Real-world 3D Infrastructure-side Collaborative Perception Dataset for Open Traffic Scenarios
Jul 31, 2024



Perception systems of autonomous vehicles are susceptible to occlusion, especially when examined from a vehicle-centric perspective. Such occlusion can lead to overlooked object detections, e.g., larger vehicles such as trucks or buses may create blind spots where cyclists or pedestrians could be obscured, accentuating the safety concerns associated with such perception system limitations. To mitigate these challenges, the vehicle-to-everything (V2X) paradigm suggests employing an infrastructure-side perception system (IPS) to complement autonomous vehicles with a broader perceptual scope. Nevertheless, the scarcity of real-world 3D infrastructure-side datasets constrains the advancement of V2X technologies. To bridge these gaps, this paper introduces a new 3D infrastructure-side collaborative perception dataset, abbreviated as inscope. Notably, InScope is the first dataset dedicated to addressing occlusion challenges by strategically deploying multiple-position Light Detection and Ranging (LiDAR) systems on the infrastructure side. Specifically, InScope encapsulates a 20-day capture duration with 303 tracking trajectories and 187,787 3D bounding boxes annotated by experts. Through analysis of benchmarks, four different benchmarks are presented for open traffic scenarios, including collaborative 3D object detection, multisource data fusion, data domain transfer, and 3D multiobject tracking tasks. Additionally, a new metric is designed to quantify the impact of occlusion, facilitating the evaluation of detection degradation ratios among various algorithms. The Experimental findings showcase the enhanced performance of leveraging InScope to assist in detecting and tracking 3D multiobjects in real-world scenarios, particularly in tracking obscured, small, and distant objects. The dataset and benchmarks are available at https://github.com/xf-zh/InScope.
LMBAO: A Landmark Map for Bundle Adjustment Odometry in LiDAR SLAM
Sep 19, 2022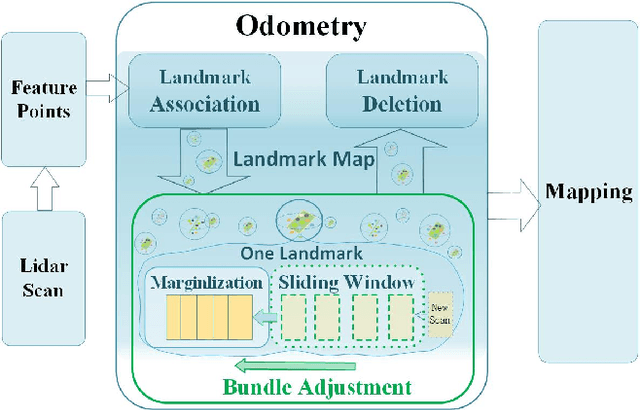
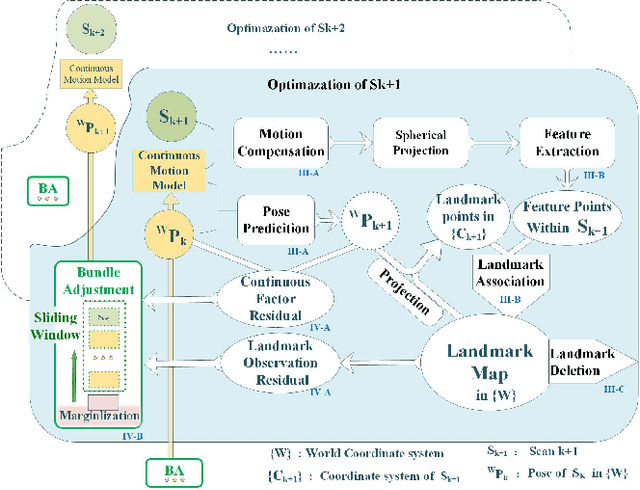
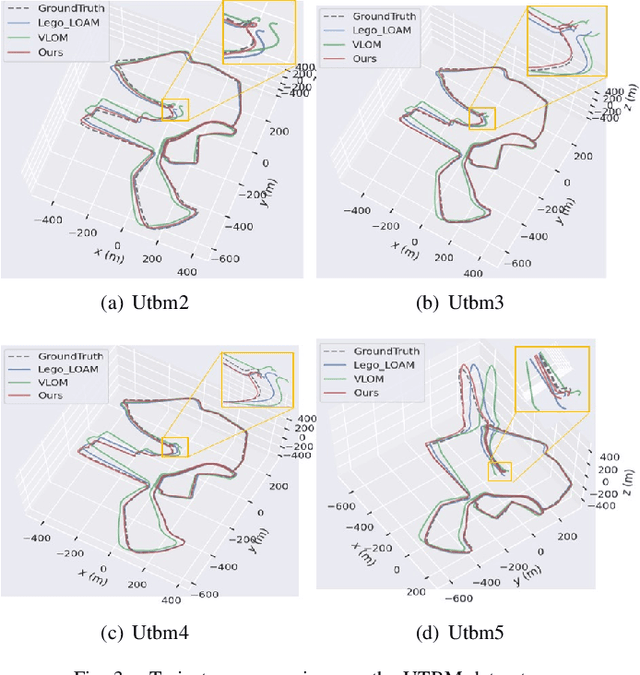

LiDAR odometry is one of the essential parts of LiDAR simultaneous localization and mapping (SLAM). However, existing LiDAR odometry tends to match a new scan simply iteratively with previous fixed-pose scans, gradually accumulating errors. Furthermore, as an effective joint optimization mechanism, bundle adjustment (BA) cannot be directly introduced into real-time odometry due to the intensive computation of large-scale global landmarks. Therefore, this letter designs a new strategy named a landmark map for bundle adjustment odometry (LMBAO) in LiDAR SLAM to solve these problems. First, BA-based odometry is further developed with an active landmark maintenance strategy for a more accurate local registration and avoiding cumulative errors. Specifically, this paper keeps entire stable landmarks on the map instead of just their feature points in the sliding window and deletes the landmarks according to their active grade. Next, the sliding window length is reduced, and marginalization is performed to retain the scans outside the window but corresponding to active landmarks on the map, greatly simplifying the computation and improving the real-time properties. In addition, experiments on three challenging datasets show that our algorithm achieves real-time performance in outdoor driving and outperforms state-of-the-art LiDAR SLAM algorithms, including Lego-LOAM and VLOM.
ASPCNet: A Deep Adaptive Spatial Pattern Capsule Network for Hyperspectral Image Classification
Apr 25, 2021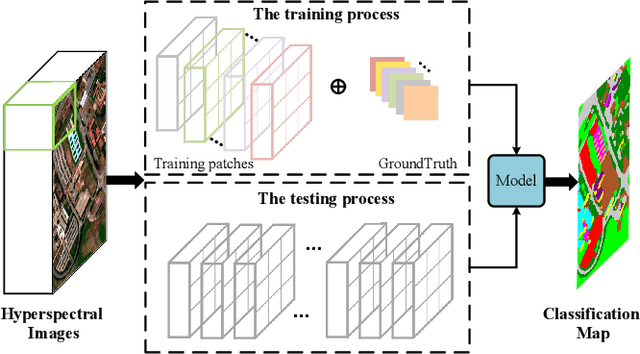

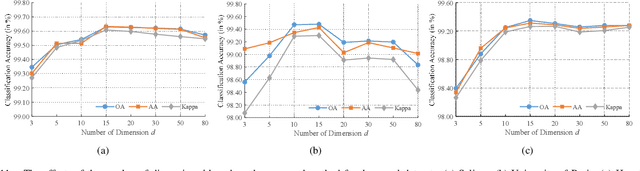
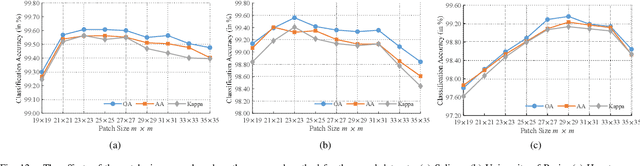
Previous studies have shown the great potential of capsule networks for the spatial contextual feature extraction from {hyperspectral images (HSIs)}. However, the sampling locations of the convolutional kernels of capsules are fixed and cannot be adaptively changed according to the inconsistent semantic information of HSIs. Based on this observation, this paper proposes an adaptive spatial pattern capsule network (ASPCNet) architecture by developing an adaptive spatial pattern (ASP) unit, that can rotate the sampling location of convolutional kernels on the basis of an enlarged receptive field. Note that this unit can learn more discriminative representations of HSIs with fewer parameters. Specifically, two cascaded ASP-based convolution operations (ASPConvs) are applied to input images to learn relatively high-level semantic features, transmitting hierarchical structures among capsules more accurately than the use of the most fundamental features. Furthermore, the semantic features are fed into ASP-based conv-capsule operations (ASPCaps) to explore the shapes of objects among the capsules in an adaptive manner, further exploring the potential of capsule networks. Finally, the class labels of image patches centered on test samples can be determined according to the fully connected capsule layer. Experiments on three public datasets demonstrate that ASPCNet can yield competitive performance with higher accuracies than state-of-the-art methods.