 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogAD: Cognitive-Hierarchy Guided End-to-End Autonomous Driving
May 27, 2025While end-to-end autonomous driving has advanced significantly, prevailing methods remain fundamentally misaligned with human cognitive principles in both perception and planning. In this paper, we propose CogAD, a novel end-to-end autonomous driving model that emulates the hierarchical cognition mechanisms of human drivers. CogAD implements dual hierarchical mechanisms: global-to-local context processing for human-like perception and intent-conditioned multi-mode trajectory generation for cognitively-inspired planning. The proposed method demonstrates three principal advantages: comprehensive environmental understanding through hierarchical perception, robust planning exploration enabled by multi-level planning, and diverse yet reasonable multi-modal trajectory generation facilitated by dual-level uncertainty modeling. Extensive experiments on nuScenes and Bench2Drive demonstrate that CogAD achieves state-of-the-art performance in end-to-end planning, exhibiting particular superiority in long-tail scenarios and robust generalization to complex real-world driving conditions.
DPR-CAE: Capsule Autoencoder with Dynamic Part Representation for Image Parsing
Apr 30, 2021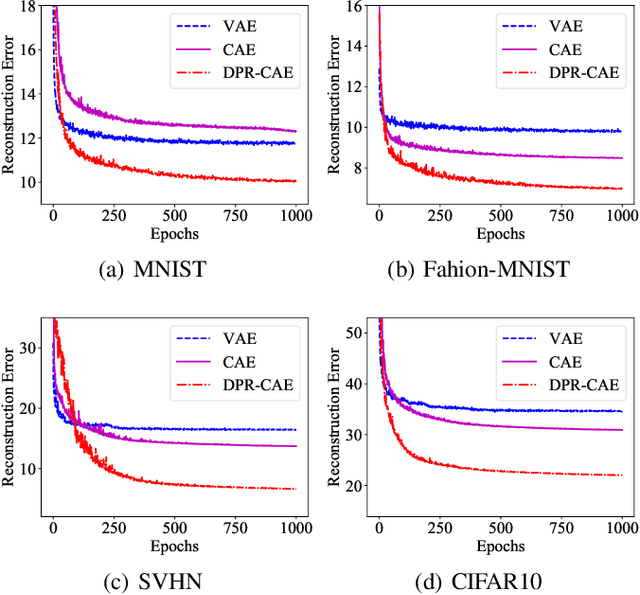
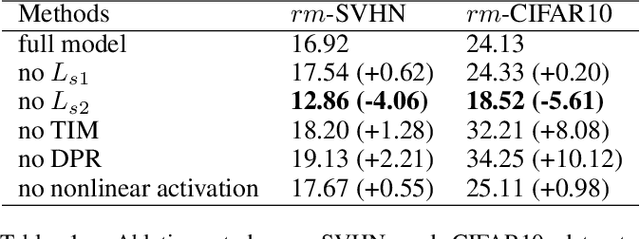

Parsing an image into a hierarchy of objects, parts, and relations is important and also challenging in many computer vision tasks. This paper proposes a simple and effective capsule autoencoder to address this issue, called DPR-CAE. In our approach, the encoder parses the input into a set of part capsules, including pose, intensity, and dynamic vector. The decoder introduces a novel dynamic part representation (DPR) by combining the dynamic vector and a shared template bank. These part representations are then regulated by corresponding capsules to composite the final output in an interpretable way. Besides, an extra translation-invariant module is proposed to avoid directly learning the uncertain scene-part relationship in our DPR-CAE, which makes the resulting method achieves a promising performance gain on $rm$-MNIST and $rm$-Fashion-MNIST. % to model the scene-object relationship DPR-CAE can be easily combined with the existing stacked capsule autoencoder and experimental results show it significantly improves performance in terms of unsupervised object classification. Our code is available in the Appendix.
ASPCNet: A Deep Adaptive Spatial Pattern Capsule Network for Hyperspectral Image Classification
Apr 25, 2021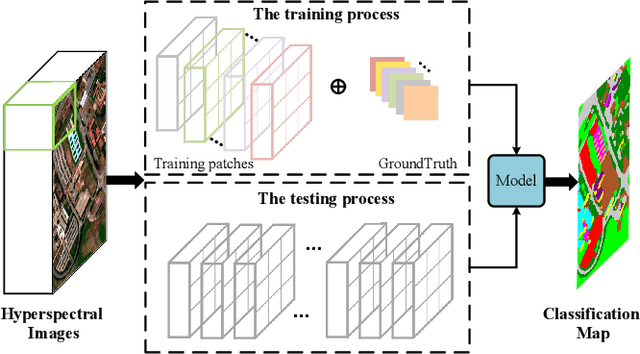

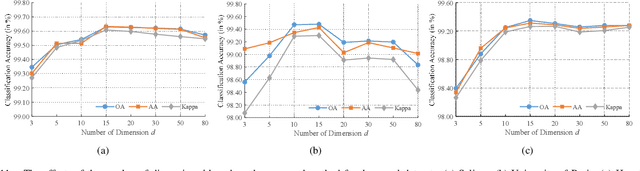
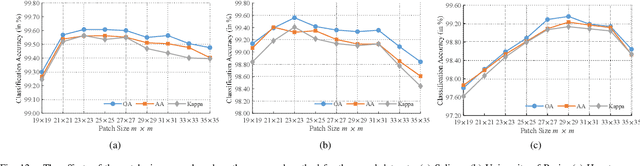
Previous studies have shown the great potential of capsule networks for the spatial contextual feature extraction from {hyperspectral images (HSIs)}. However, the sampling locations of the convolutional kernels of capsules are fixed and cannot be adaptively changed according to the inconsistent semantic information of HSIs. Based on this observation, this paper proposes an adaptive spatial pattern capsule network (ASPCNet) architecture by developing an adaptive spatial pattern (ASP) unit, that can rotate the sampling location of convolutional kernels on the basis of an enlarged receptive field. Note that this unit can learn more discriminative representations of HSIs with fewer parameters. Specifically, two cascaded ASP-based convolution operations (ASPConvs) are applied to input images to learn relatively high-level semantic features, transmitting hierarchical structures among capsules more accurately than the use of the most fundamental features. Furthermore, the semantic features are fed into ASP-based conv-capsule operations (ASPCaps) to explore the shapes of objects among the capsules in an adaptive manner, further exploring the potential of capsule networks. Finally, the class labels of image patches centered on test samples can be determined according to the fully connected capsule layer. Experiments on three public datasets demonstrate that ASPCNet can yield competitive performance with higher accuracies than state-of-the-art methods.
MMA Regularization: Decorrelating Weights of Neural Networks by Maximizing the Minimal Angles
Jun 06, 2020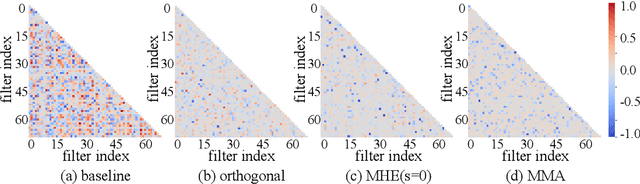
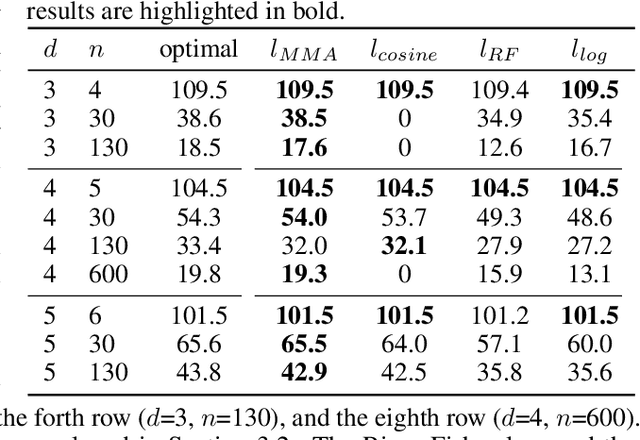
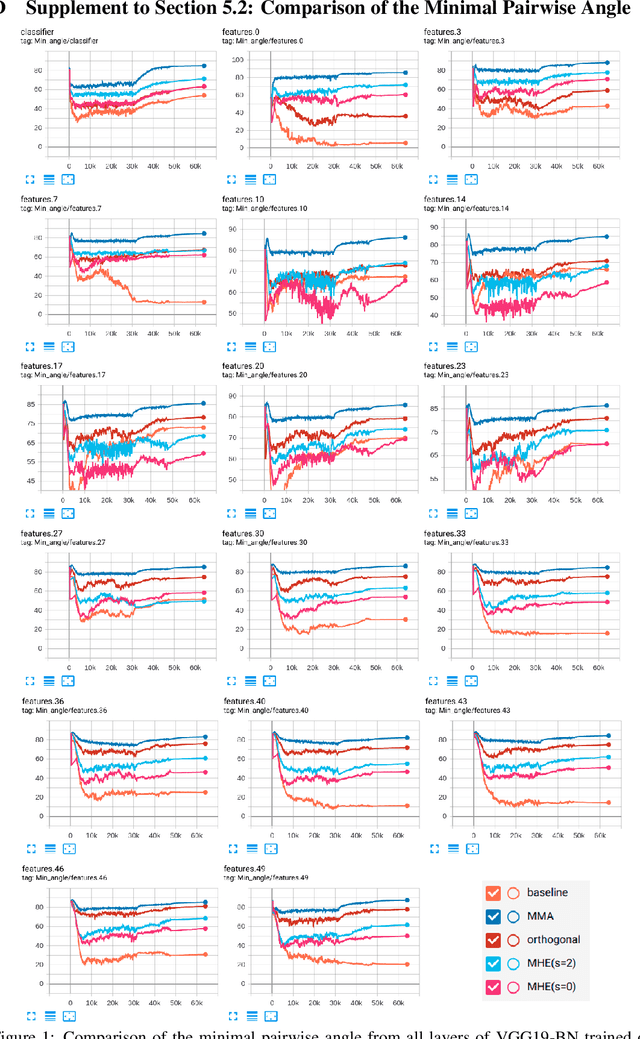
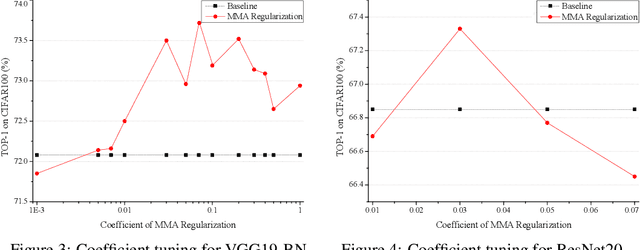
The strong correlation between neurons or filters can significantly weaken the generalization ability of neural networks. Inspired by the well-known Tammes problem, we propose a novel diversity regularization method to address this issue, which makes the normalized weight vectors of neurons or filters distributed on a hypersphere as uniformly as possible, through maximizing the minimal pairwise angles (MMA). This method can easily exert its effect by plugging the MMA regularization term into the loss function with negligible computational overhead. The MMA regularization is simple, efficient, and effective. Therefore, it can be used as a basic regularization method in neural network training. Extensive experiments demonstrate that MMA regularization is able to enhance the generalization ability of various modern models and achieves considerable performance improvements on CIFAR100 and TinyImageNet datasets. In addition, experiments on face verification show that MMA regularization is also effective for feature learning.
SAIS: Single-stage Anchor-free Instance Segmentation
Dec 03, 2019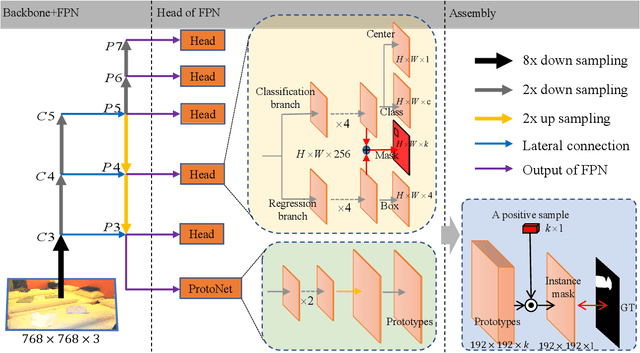
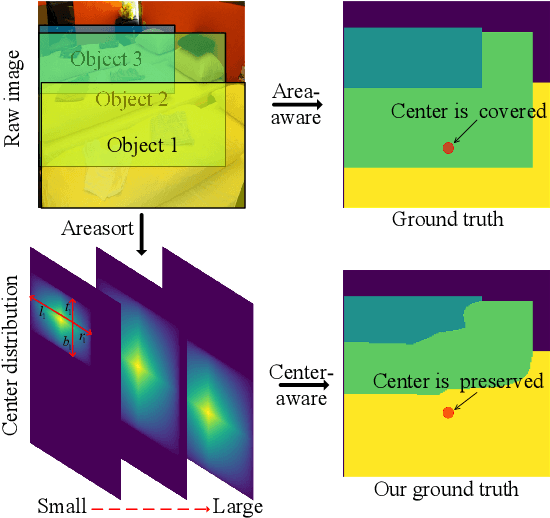

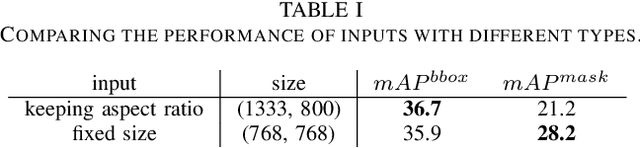
In this paper, we propose a simple yet efficientinstance segmentation approach based on the single-stage anchor-free detector, termed SAIS. In our approach, the instancesegmentation task consists of two parallel subtasks which re-spectively predict the mask coefficients and the mask prototypes.Then, instance masks are generated by linearly combining theprototypes with the mask coefficients. To enhance the quality ofinstance mask, the information from regression and classificationis fused to predict the mask coefficients. In addition, center-aware target is designed to preserve the center coordination ofeach instance, which achieves a stable improvement in instancesegmentation. The experiment on MS COCO shows that SAISachieves the performance of the exiting state-of-the-art single-stage methods with a much less memory footpr