 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Bitstream-Corrupted Video Restoration: Methods and Results
Apr 09, 2026This paper reports on the NTIRE 2026 Challenge on Bitstream-Corrupted Video Restoration (BSCVR). The challenge aims to advance research on recovering visually coherent videos from corrupted bitstreams, whose decoding often produces severe spatial-temporal artifacts and content distortion. Built upon recent progress in bitstream-corrupted video recovery, the challenge provides a common benchmark for evaluating restoration methods under realistic corruption settings. We describe the dataset, evaluation protocol, and participating methods, and summarize the final results and main technical trends. The challenge highlights the difficulty of this emerging task and provides useful insights for future research on robust video restoration under practical bitstream corruption.
Prototypical Progressive Alignment and Reweighting for Generalizable Semantic Segmentation
Jul 16, 2025



Generalizable semantic segmentation aims to perform well on unseen target domains, a critical challenge due to real-world applications requiring high generalizability. Class-wise prototypes, representing class centroids, serve as domain-invariant cues that benefit generalization due to their stability and semantic consistency. However, this approach faces three challenges. First, existing methods often adopt coarse prototypical alignment strategies, which may hinder performance. Second, naive prototypes computed by averaging source batch features are prone to overfitting and may be negatively affected by unrelated source data. Third, most methods treat all source samples equally, ignoring the fact that different features have varying adaptation difficulties. To address these limitations, we propose a novel framework for generalizable semantic segmentation: Prototypical Progressive Alignment and Reweighting (PPAR), leveraging the strong generalization ability of the CLIP model. Specifically, we define two prototypes: the Original Text Prototype (OTP) and Visual Text Prototype (VTP), generated via CLIP to serve as a solid base for alignment. We then introduce a progressive alignment strategy that aligns features in an easy-to-difficult manner, reducing domain gaps gradually. Furthermore, we propose a prototypical reweighting mechanism that estimates the reliability of source data and adjusts its contribution, mitigating the effect of irrelevant or harmful features (i.e., reducing negative transfer). We also provide a theoretical analysis showing the alignment between our method and domain generalization theory. Extensive experiments across multiple benchmarks demonstrate that PPAR achieves state-of-the-art performance, validating its effectiveness.
Depth-Sensitive Soft Suppression with RGB-D Inter-Modal Stylization Flow for Domain Generalization Semantic Segmentation
May 11, 2025

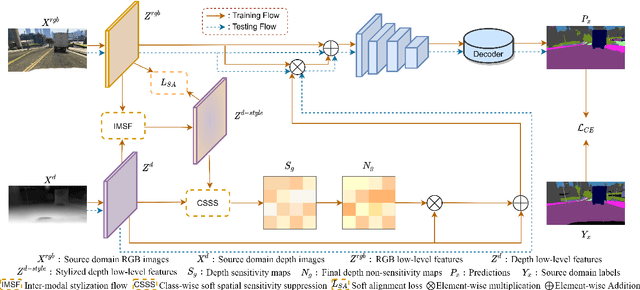
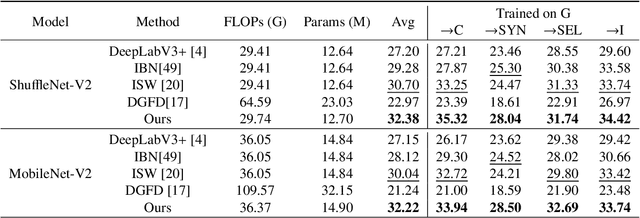
Unsupervised Domain Adaptation (UDA) aims to align source and target domain distributions to close the domain gap, but still struggles with obtaining the target data. Fortunately, Domain Generalization (DG) excels without the need for any target data. Recent works expose that depth maps contribute to improved generalized performance in the UDA tasks, but they ignore the noise and holes in depth maps due to device and environmental factors, failing to sufficiently and effectively learn domain-invariant representation. Although high-sensitivity region suppression has shown promising results in learning domain-invariant features, existing methods cannot be directly applicable to depth maps due to their unique characteristics. Hence, we propose a novel framework, namely Depth-Sensitive Soft Suppression with RGB-D inter-modal stylization flow (DSSS), focusing on learning domain-invariant features from depth maps for the DG semantic segmentation. Specifically, we propose the RGB-D inter-modal stylization flow to generate stylized depth maps for sensitivity detection, cleverly utilizing RGB information as the stylization source. Then, a class-wise soft spatial sensitivity suppression is designed to identify and emphasize non-sensitive depth features that contain more domain-invariant information. Furthermore, an RGB-D soft alignment loss is proposed to ensure that the stylized depth maps only align part of the RGB features while still retaining the unique depth information. To our best knowledge, our DSSS framework is the first work to integrate RGB and Depth information in the multi-class DG semantic segmentation task. Extensive experiments over multiple backbone networks show that our framework achieves remarkable performance improvement.
Wave-Mamba: Wavelet State Space Model for Ultra-High-Definition Low-Light Image Enhancement
Aug 02, 2024Ultra-high-definition (UHD) technology has attracted widespread attention due to its exceptional visual quality, but it also poses new challenges for low-light image enhancement (LLIE) techniques. UHD images inherently possess high computational complexity, leading existing UHD LLIE methods to employ high-magnification downsampling to reduce computational costs, which in turn results in information loss. The wavelet transform not only allows downsampling without loss of information, but also separates the image content from the noise. It enables state space models (SSMs) to avoid being affected by noise when modeling long sequences, thus making full use of the long-sequence modeling capability of SSMs. On this basis, we propose Wave-Mamba, a novel approach based on two pivotal insights derived from the wavelet domain: 1) most of the content information of an image exists in the low-frequency component, less in the high-frequency component. 2) The high-frequency component exerts a minimal influence on the outcomes of low-light enhancement. Specifically, to efficiently model global content information on UHD images, we proposed a low-frequency state space block (LFSSBlock) by improving SSMs to focus on restoring the information of low-frequency sub-bands. Moreover, we propose a high-frequency enhance block (HFEBlock) for high-frequency sub-band information, which uses the enhanced low-frequency information to correct the high-frequency information and effectively restore the correct high-frequency details. Through comprehensive evaluation, our method has demonstrated superior performance, significantly outshining current leading techniques while maintaining a more streamlined architecture. The code is available at https://github.com/AlexZou14/Wave-Mamba.
Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution
May 09, 2024Stereo image super-resolution utilizes the cross-view complementary information brought by the disparity effect of left and right perspective images to reconstruct higher-quality images. Cascading feature extraction modules and cross-view feature interaction modules to make use of the information from stereo images is the focus of numerous methods. However, this adds a great deal of network parameters and structural redundancy. To facilitate the application of stereo image super-resolution in downstream tasks, we propose an efficient Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution (MFFSSR). Specifically, MFFSSR utilizes the Hybrid Attention Feature Extraction Block (HAFEB) to extract multi-level intra-view features. Using the channel separation strategy, HAFEB can efficiently interact with the embedded cross-view interaction module. This structural configuration can efficiently mine features inside the view while improving the efficiency of cross-view information sharing. Hence, reconstruct image details and textures more accurately. Abundant experiments demonstrate the effectiveness of MFFSSR. We achieve superior performance with fewer parameters. The source code is available at https://github.com/KarosLYX/MFFSSR.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024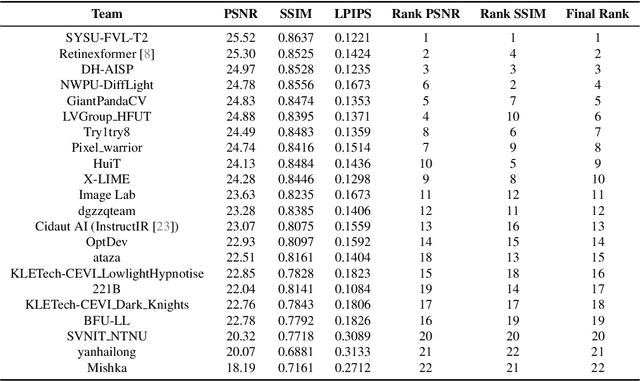

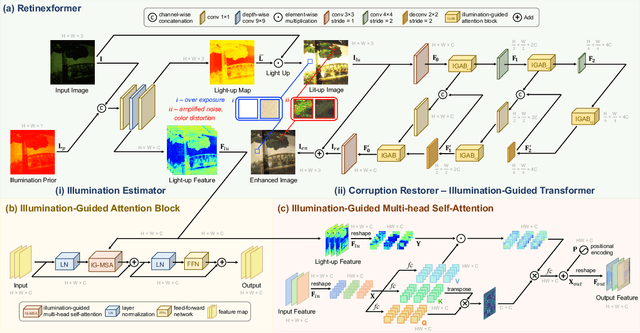

This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
VQCNIR: Clearer Night Image Restoration with Vector-Quantized Codebook
Dec 16, 2023Night photography often struggles with challenges like low light and blurring, stemming from dark environments and prolonged exposures. Current methods either disregard priors and directly fitting end-to-end networks, leading to inconsistent illumination, or rely on unreliable handcrafted priors to constrain the network, thereby bringing the greater error to the final result. We believe in the strength of data-driven high-quality priors and strive to offer a reliable and consistent prior, circumventing the restrictions of manual priors. In this paper, we propose Clearer Night Image Restoration with Vector-Quantized Codebook (VQCNIR) to achieve remarkable and consistent restoration outcomes on real-world and synthetic benchmarks. To ensure the faithful restoration of details and illumination, we propose the incorporation of two essential modules: the Adaptive Illumination Enhancement Module (AIEM) and the Deformable Bi-directional Cross-Attention (DBCA) module. The AIEM leverages the inter-channel correlation of features to dynamically maintain illumination consistency between degraded features and high-quality codebook features. Meanwhile, the DBCA module effectively integrates texture and structural information through bi-directional cross-attention and deformable convolution, resulting in enhanced fine-grained detail and structural fidelity across parallel decoders. Extensive experiments validate the remarkable benefits of VQCNIR in enhancing image quality under low-light conditions, showcasing its state-of-the-art performance on both synthetic and real-world datasets. The code is available at https://github.com/AlexZou14/VQCNIR.
Calibration-based Dual Prototypical Contrastive Learning Approach for Domain Generalization Semantic Segmentation
Sep 25, 2023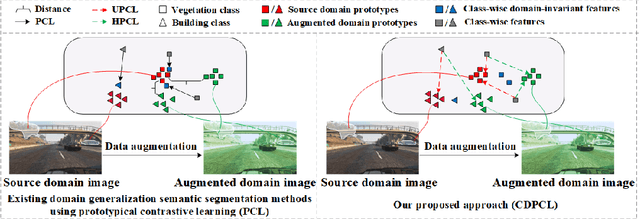
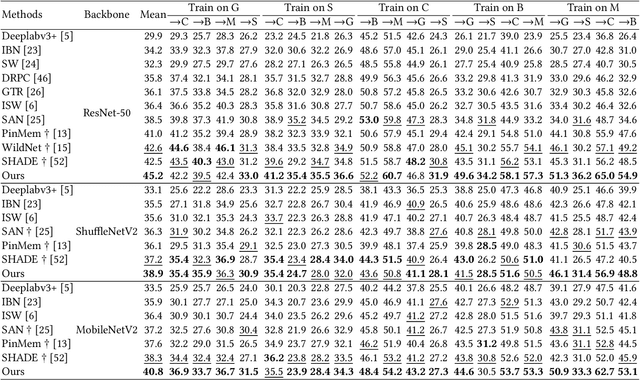
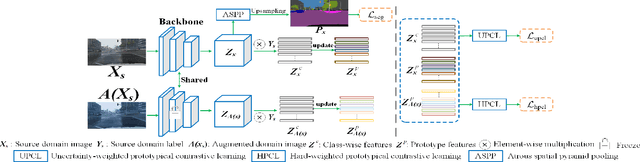
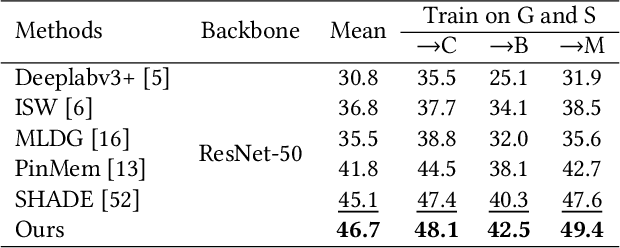
Prototypical contrastive learning (PCL) has been widely used to learn class-wise domain-invariant features recently. These methods are based on the assumption that the prototypes, which are represented as the central value of the same class in a certain domain, are domain-invariant. Since the prototypes of different domains have discrepancies as well, the class-wise domain-invariant features learned from the source domain by PCL need to be aligned with the prototypes of other domains simultaneously. However, the prototypes of the same class in different domains may be different while the prototypes of different classes may be similar, which may affect the learning of class-wise domain-invariant features. Based on these observations, a calibration-based dual prototypical contrastive learning (CDPCL) approach is proposed to reduce the domain discrepancy between the learned class-wise features and the prototypes of different domains for domain generalization semantic segmentation. It contains an uncertainty-guided PCL (UPCL) and a hard-weighted PCL (HPCL). Since the domain discrepancies of the prototypes of different classes may be different, we propose an uncertainty probability matrix to represent the domain discrepancies of the prototypes of all the classes. The UPCL estimates the uncertainty probability matrix to calibrate the weights of the prototypes during the PCL. Moreover, considering that the prototypes of different classes may be similar in some circumstances, which means these prototypes are hard-aligned, the HPCL is proposed to generate a hard-weighted matrix to calibrate the weights of the hard-aligned prototypes during the PCL. Extensive experiments demonstrate that our approach achieves superior performance over current approaches on domain generalization semantic segmentation tasks.
Cross-View Hierarchy Network for Stereo Image Super-Resolution
Apr 13, 2023Stereo image super-resolution aims to improve the quality of high-resolution stereo image pairs by exploiting complementary information across views. To attain superior performance, many methods have prioritized designing complex modules to fuse similar information across views, yet overlooking the importance of intra-view information for high-resolution reconstruction. It also leads to problems of wrong texture in recovered images. To address this issue, we explore the interdependencies between various hierarchies from intra-view and propose a novel method, named Cross-View-Hierarchy Network for Stereo Image Super-Resolution (CVHSSR). Specifically, we design a cross-hierarchy information mining block (CHIMB) that leverages channel attention and large kernel convolution attention to extract both global and local features from the intra-view, enabling the efficient restoration of accurate texture details. Additionally, a cross-view interaction module (CVIM) is proposed to fuse similar features from different views by utilizing cross-view attention mechanisms, effectively adapting to the binocular scene. Extensive experiments demonstrate the effectiveness of our method. CVHSSR achieves the best stereo image super-resolution performance than other state-of-the-art methods while using fewer parameters. The source code and pre-trained models are available at https://github.com/AlexZou14/CVHSSR.
A Class-wise Non-salient Region Generalized Framework for Video Semantic Segmentation
Dec 29, 2022



Video semantic segmentation (VSS) is beneficial for dealing with dynamic scenes due to the continuous property of the real-world environment. On the one hand, some methods alleviate the predicted inconsistent problem between continuous frames. On the other hand, other methods employ the previous frame as the prior information to assist in segmenting the current frame. Although the previous methods achieve superior performances on the independent and identically distributed (i.i.d) data, they can not generalize well on other unseen domains. Thus, we explore a new task, the video generalizable semantic segmentation (VGSS) task that considers both continuous frames and domain generalization. In this paper, we propose a class-wise non-salient region generalized (CNSG) framework for the VGSS task. Concretely, we first define the class-wise non-salient feature, which describes features of the class-wise non-salient region that carry more generalizable information. Then, we propose a class-wise non-salient feature reasoning strategy to select and enhance the most generalized channels adaptively. Finally, we propose an inter-frame non-salient centroid alignment loss to alleviate the predicted inconsistent problem in the VGSS task. We also extend our video-based framework to the image-based generalizable semantic segmentation (IGSS) task. Experiments demonstrate that our CNSG framework yields significant improvement in the VGSS and IGSS tasks.