 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Hierarchy Network for Stereo Image Super-Resolution
Apr 13, 2023Stereo image super-resolution aims to improve the quality of high-resolution stereo image pairs by exploiting complementary information across views. To attain superior performance, many methods have prioritized designing complex modules to fuse similar information across views, yet overlooking the importance of intra-view information for high-resolution reconstruction. It also leads to problems of wrong texture in recovered images. To address this issue, we explore the interdependencies between various hierarchies from intra-view and propose a novel method, named Cross-View-Hierarchy Network for Stereo Image Super-Resolution (CVHSSR). Specifically, we design a cross-hierarchy information mining block (CHIMB) that leverages channel attention and large kernel convolution attention to extract both global and local features from the intra-view, enabling the efficient restoration of accurate texture details. Additionally, a cross-view interaction module (CVIM) is proposed to fuse similar features from different views by utilizing cross-view attention mechanisms, effectively adapting to the binocular scene. Extensive experiments demonstrate the effectiveness of our method. CVHSSR achieves the best stereo image super-resolution performance than other state-of-the-art methods while using fewer parameters. The source code and pre-trained models are available at https://github.com/AlexZou14/CVHSSR.
Perceiving and Modeling Density is All You Need for Image Dehazing
Nov 18, 2021

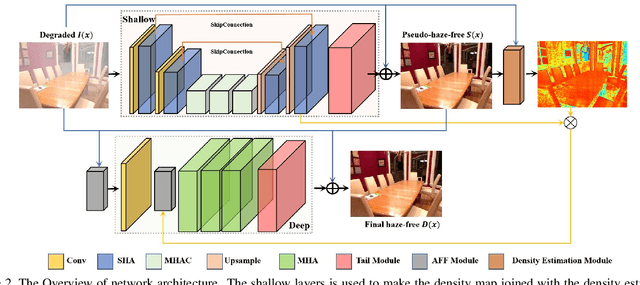

In the real world, the degradation of images taken under haze can be quite complex, where the spatial distribution of haze is varied from image to image. Recent methods adopt deep neural networks to recover clean scenes from hazy images directly. However, due to the paradox caused by the variation of real captured haze and the fixed degradation parameters of the current networks, the generalization ability of recent dehazing methods on real-world hazy images is not ideal.To address the problem of modeling real-world haze degradation, we propose to solve this problem by perceiving and modeling density for uneven haze distribution. We propose a novel Separable Hybrid Attention (SHA) module to encode haze density by capturing features in the orthogonal directions to achieve this goal. Moreover, a density map is proposed to model the uneven distribution of the haze explicitly. The density map generates positional encoding in a semi-supervised way. Such a haze density perceiving and modeling capture the unevenly distributed degeneration at the feature level effectively. Through a suitable combination of SHA and density map, we design a novel dehazing network architecture, which achieves a good complexity-performance trade-off. The extensive experiments on two large-scale datasets demonstrate that our method surpasses all state-of-the-art approaches by a large margin both quantitatively and qualitatively, boosting the best published PSNR metric from 28.53 dB to 33.49 dB on the Haze4k test dataset and from 37.17 dB to 38.41 dB on the SOTS indoor test dataset.
SDWNet: A Straight Dilated Network with Wavelet Transformation for Image Deblurring
Oct 12, 2021

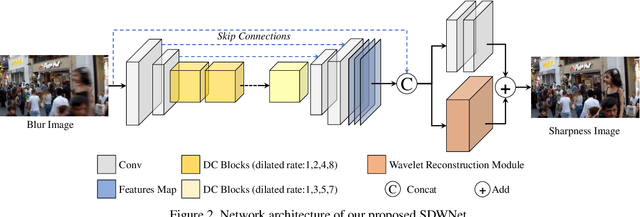

Image deblurring is a classical computer vision problem that aims to recover a sharp image from a blurred image. To solve this problem, existing methods apply the Encode-Decode architecture to design the complex networks to make a good performance. However, most of these methods use repeated up-sampling and down-sampling structures to expand the receptive field, which results in texture information loss during the sampling process and some of them design the multiple stages that lead to difficulties with convergence. Therefore, our model uses dilated convolution to enable the obtainment of the large receptive field with high spatial resolution. Through making full use of the different receptive fields, our method can achieve better performance. On this basis, we reduce the number of up-sampling and down-sampling and design a simple network structure. Besides, we propose a novel module using the wavelet transform, which effectively helps the network to recover clear high-frequency texture details. Qualitative and quantitative evaluations of real and synthetic datasets show that our deblurring method is comparable to existing algorithms in terms of performance with much lower training requirements. The source code and pre-trained models are available at https://github.com/FlyEgle/SDWNet.
InstantNet: Automated Generation and Deployment of Instantaneously Switchable-Precision Networks
Apr 22, 2021



The promise of Deep Neural Network (DNN) powered Internet of Thing (IoT) devices has motivated a tremendous demand for automated solutions to enable fast development and deployment of efficient (1) DNNs equipped with instantaneous accuracy-efficiency trade-off capability to accommodate the time-varying resources at IoT devices and (2) dataflows to optimize DNNs' execution efficiency on different devices. Therefore, we propose InstantNet to automatically generate and deploy instantaneously switchable-precision networks which operate at variable bit-widths. Extensive experiments show that the proposed InstantNet consistently outperforms state-of-the-art designs.
Few-shot Image Classification: Just Use a Library of Pre-trained Feature Extractors and a Simple Classifier
Jan 03, 2021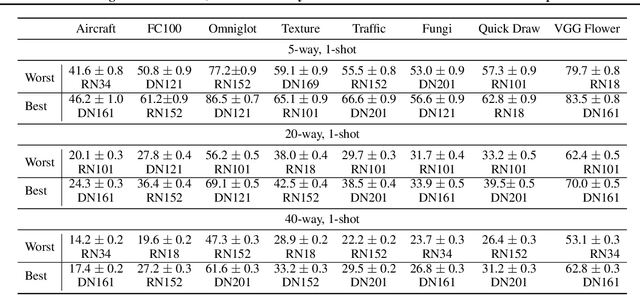
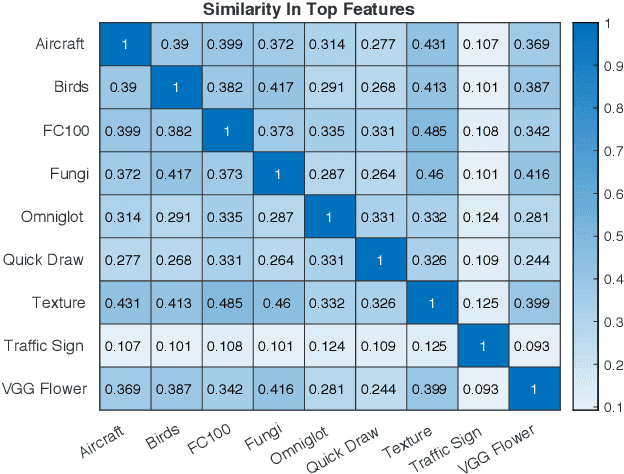
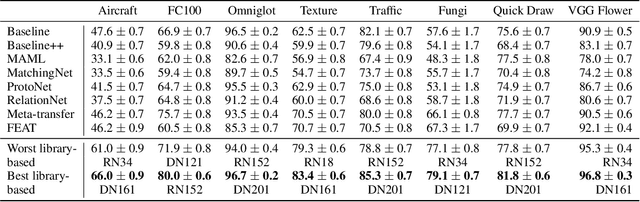

Recent papers have suggested that transfer learning can outperform sophisticated meta-learning methods for few-shot image classification. We take this hypothesis to its logical conclusion, and suggest the use of an ensemble of high-quality, pre-trained feature extractors for few-shot image classification. We show experimentally that a library of pre-trained feature extractors combined with a simple feed-forward network learned with an L2-regularizer can be an excellent option for solving cross-domain few-shot image classification. Our experimental results suggest that this simpler sample-efficient approach far outperforms several well-established meta-learning algorithms on a variety of few-shot tasks.