 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Facts (Pix2Fact): Benchmarking Multi-Hop Reasoning for Fine-Grained Visual Fact Checking
Jan 31, 2026Despite progress on general tasks, VLMs struggle with challenges demanding both detailed visual grounding and deliberate knowledge-based reasoning, a synergy not captured by existing benchmarks that evaluate these skills separately. To close this gap, we introduce Pix2Fact, a new visual question-answering benchmark designed to evaluate expert-level perception and knowledge-intensive multi-hop reasoning. Pix2Fact contains 1,000 high-resolution (4K+) images spanning 8 daily-life scenarios and situations, with questions and answers meticulously crafted by annotators holding PhDs from top global universities working in partnership with a professional data annotation firm. Each question requires detailed visual grounding, multi-hop reasoning, and the integration of external knowledge to answer. Our evaluation of 9 state-of-the-art VLMs, including proprietary models like Gemini-3-Pro and GPT-5, reveals the substantial challenge posed by Pix2Fact: the most advanced model achieves only 24.0% average accuracy, in stark contrast to human performance of 56%. This significant gap underscores the limitations of current models in replicating human-level visual comprehension. We believe Pix2Fact will serve as a critical benchmark to drive the development of next-generation multimodal agents that combine fine-grained perception with robust, knowledge-based reasoning.
LFS: Learnable Frame Selector for Event-Aware and Temporally Diverse Video Captioning
Jan 21, 2026Video captioning models convert frames into visual tokens and generate descriptions with large language models (LLMs). Since encoding all frames is prohibitively expensive, uniform sampling is the default choice, but it enforces equal temporal coverage while ignoring the uneven events distribution. This motivates a Learnable Frame Selector (LFS) that selects temporally diverse and event-relevant frames. LFS explicitly models temporal importance to balance temporal diversity and event relevance, and employs a stratified strategy to ensure temporal coverage while avoiding clustering. Crucially, LFS leverages caption feedback from frozen video-LLMs to learn frame selection that directly optimizes downstream caption quality. Additionally, we identify the gap between existing benchmark and human's cognition. Thus, we introduce ICH-CC built from carefully designed questions by annotators that reflect human-consistent understanding of video. Experiments indicate that LFS consistently improves detailed video captioning across two representative community benchmarks and ICH-CC, achieving up to 2.0% gains on VDC and over 4% gains on ICH-CC. Moreover, we observe that enhanced captions with LFS leads to improved performance on video question answering. Overall, LFS provides an effective and easy-to-integrate solution for detailed video captioning.
FUSE-RSVLM: Feature Fusion Vision-Language Model for Remote Sensing
Dec 30, 2025Large vision-language models (VLMs) exhibit strong performance across various tasks. However, these VLMs encounter significant challenges when applied to the remote sensing domain due to the inherent differences between remote sensing images and natural images. Existing remote sensing VLMs often fail to extract fine-grained visual features and suffer from visual forgetting during deep language processing. To address this, we introduce MF-RSVLM, a Multi-Feature Fusion Remote Sensing Vision--Language Model that effectively extracts and fuses visual features for RS understanding. MF-RSVLM learns multi-scale visual representations and combines global context with local details, improving the capture of small and complex structures in RS scenes. A recurrent visual feature injection scheme ensures the language model remains grounded in visual evidence and reduces visual forgetting during generation. Extensive experiments on diverse RS benchmarks show that MF-RSVLM achieves state-of-the-art or highly competitive performance across remote sensing classification, image captioning, and VQA tasks. Our code is publicly available at https://github.com/Yunkaidang/RSVLM.
Intelligent Reflecting Surfaces for Integrated Sensing and Communications: A Survey
Nov 14, 2025
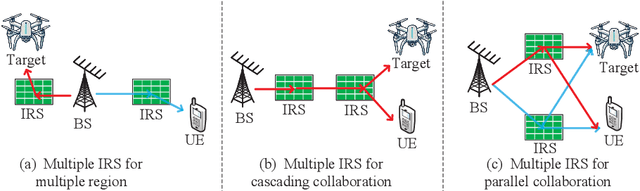
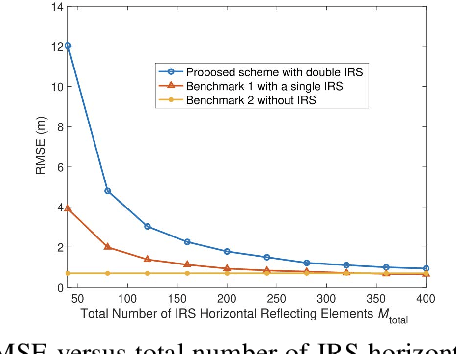
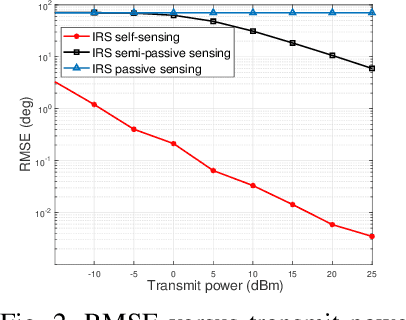
The rapid development of sixth-generation (6G) wireless networks requires seamless integration of communication and sensing to support ubiquitous intelligence and real-time, high-reliability applications. Integrated sensing and communication (ISAC) has emerged as a key solution for achieving this convergence, offering joint utilization of spectral, hardware, and computing resources. However, realizing high-performance ISAC remains challenging due to environmental line-of-sight (LoS) blockage, limited spatial resolution, and the inherent coverage asymmetry and resource coupling between sensing and communication. Intelligent reflecting surfaces (IRSs), featuring low-cost, energy-efficient, and programmable electromagnetic reconfiguration, provide a promising solution to overcome these limitations. This article presents a comprehensive overview of IRS-aided wireless sensing and ISAC technologies, including IRS architectures, target detection and estimation techniques, beamforming designs, and performance metrics. It further explores IRS-enabled new opportunities for more efficient performance balancing, coexistence, and networking in ISAC systems, focuses on current design bottlenecks, and outlines future research directions. This article aims to offer a unified design framework that guides the development of practical and scalable IRS-aided ISAC systems for the next-generation wireless network.
VIDEOP2R: Video Understanding from Perception to Reasoning
Nov 14, 2025Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VideoP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VideoP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VideoP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO and demonstrate that model's perception output is information-sufficient for downstream reasoning.
Reconfigurable Airspace: Synergizing Movable Antenna and Intelligent Surface for Low-Altitude ISAC Networks
Nov 13, 2025Low-altitude unmanned aerial vehicle (UAV) networks are integral to future 6G integrated sensing and communication (ISAC) systems. However, their deployment is hindered by challenges stemming from high mobility of UAVs, complex propagation environments, and the inherent trade-offs between coexisting sensing and communication functions. This article proposes a novel framework that leverages movable antennas (MAs) and intelligent reflecting surfaces (IRSs) as dual enablers to overcome these limitations. MAs, through active transceiver reconfiguration, and IRSs, via passive channel reconstruction, can work in synergy to significantly enhance system performance. Our analysis first elaborates on the fundamental gains offered by MAs and IRSs, and provides simulation results that validate the immense potential of the MA-IRS-enabled ISAC architecture. Two core UAV deployment scenarios are then investigated: (i) UAVs as ISAC users, where we focus on achieving high-precision tracking and aerial safety, and (ii) UAVs as aerial network nodes, where we address robust design and complex coupled resource optimization. Finally, key technical challenges and research opportunities are identified and analyzed for each scenario, charting a clear course for the future design of advanced low-altitude ISAC networks.
Low-Altitude UAV Tracking via Sensing-Assisted Predictive Beamforming
Sep 16, 2025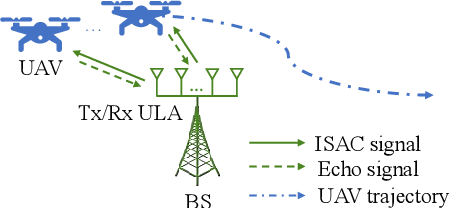
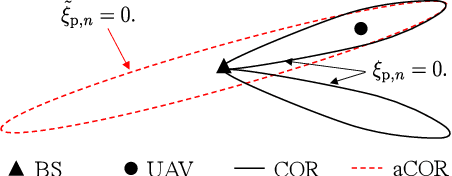
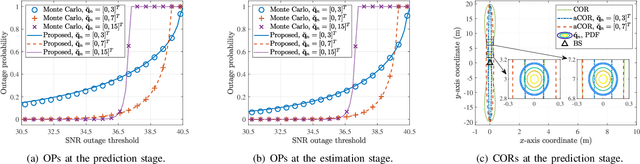
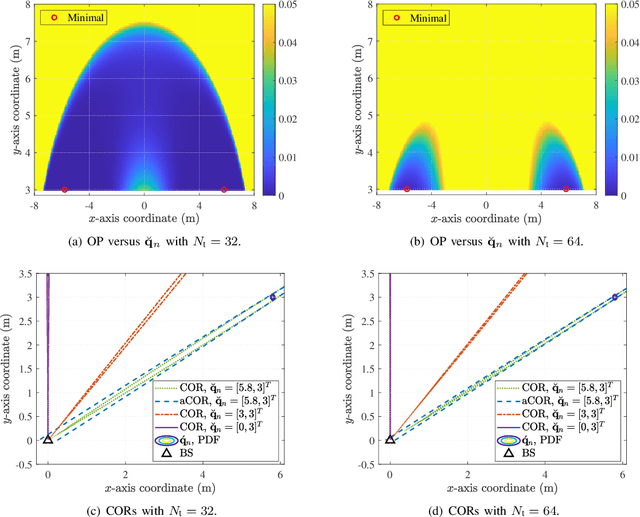
Sensing-assisted predictive beamforming, as one of the enabling technologies for emerging integrated sensing and communication (ISAC) paradigm, shows significant promise for enhancing various future unmanned aerial vehicle (UAV) applications. However, current works predominately emphasized on spectral efficiency enhancement, while the impact of such beamforming techniques on the communication reliability was largely unexplored and challenging to characterize. To fill this research gap and tackle this issue, this paper investigates outage capacity maximization for UAV tracking under the sensing-assisted predictive beamforming scheme. Specifically, a cellular-connected UAV tracking scheme is proposed leveraging extended Kalman filtering (EKF), where the predicted UAV trajectory, sensing duration ratio, and target constant received signal-to-noise ratio (SNR) are jointly optimized to maximize the outage capacity at each time slot. To address the implicit nature of the objective function, closed-form approximations of the outage probabilities (OPs) at both prediction and measurement stages of each time slot are proposed based on second-order Taylor expansions, providing an efficient and full characterization of outage capacity. Subsequently, an efficient algorithm is proposed based on a combination of bisection search and successive convex approximation (SCA) to address the non-convex optimization problem with guaranteed convergence. To further reduce computational complexity, a second efficient algorithm is developed based on alternating optimization (AO). Simulation results validate the accuracy of the derived OP approximations, the effectiveness of the proposed algorithms, and the significant outage capacity enhancement over various benchmarks, while also indicating a trade-off between decreasing path loss and enjoying wide beam coverage for outage capacity maximization.
ZS-Puffin: Design, Modeling and Implementation of an Unmanned Aerial-Aquatic Vehicle with Amphibious Wings
Aug 12, 2025Unmanned aerial-aquatic vehicles (UAAVs) can operate both in the air and underwater, giving them broad application prospects. Inspired by the dual-function wings of puffins, we propose a UAAV with amphibious wings to address the challenge posed by medium differences on the vehicle's propulsion system. The amphibious wing, redesigned based on a fixed-wing structure, features a single degree of freedom in pitch and requires no additional components. It can generate lift in the air and function as a flapping wing for propulsion underwater, reducing disturbance to marine life and making it environmentally friendly. Additionally, an artificial central pattern generator (CPG) is introduced to enhance the smoothness of the flapping motion. This paper presents the prototype, design details, and practical implementation of this concept.
Graph-Guided Dual-Level Augmentation for 3D Scene Segmentation
Jul 30, 20253D point cloud segmentation aims to assign semantic labels to individual points in a scene for fine-grained spatial understanding. Existing methods typically adopt data augmentation to alleviate the burden of large-scale annotation. However, most augmentation strategies only focus on local transformations or semantic recomposition, lacking the consideration of global structural dependencies within scenes. To address this limitation, we propose a graph-guided data augmentation framework with dual-level constraints for realistic 3D scene synthesis. Our method learns object relationship statistics from real-world data to construct guiding graphs for scene generation. Local-level constraints enforce geometric plausibility and semantic consistency between objects, while global-level constraints maintain the topological structure of the scene by aligning the generated layout with the guiding graph. Extensive experiments on indoor and outdoor datasets demonstrate that our framework generates diverse and high-quality augmented scenes, leading to consistent improvements in point cloud segmentation performance across various models.
DiMeR: Disentangled Mesh Reconstruction Model
Apr 24, 2025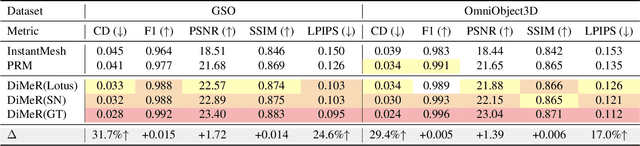

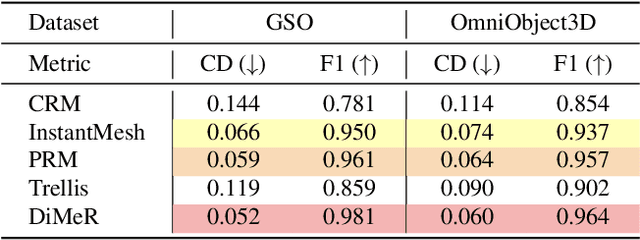
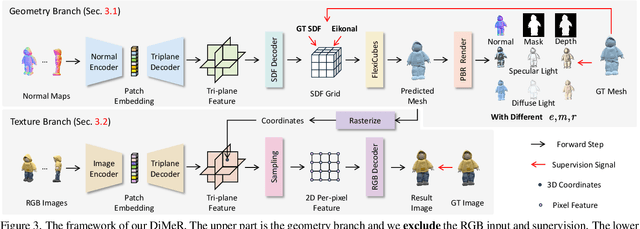
With the advent of large-scale 3D datasets, feed-forward 3D generative models, such as the Large Reconstruction Model (LRM), have gained significant attention and achieved remarkable success. However, we observe that RGB images often lead to conflicting training objectives and lack the necessary clarity for geometry reconstruction. In this paper, we revisit the inductive biases associated with mesh reconstruction and introduce DiMeR, a novel disentangled dual-stream feed-forward model for sparse-view mesh reconstruction. The key idea is to disentangle both the input and framework into geometry and texture parts, thereby reducing the training difficulty for each part according to the Principle of Occam's Razor. Given that normal maps are strictly consistent with geometry and accurately capture surface variations, we utilize normal maps as exclusive input for the geometry branch to reduce the complexity between the network's input and output. Moreover, we improve the mesh extraction algorithm to introduce 3D ground truth supervision. As for texture branch, we use RGB images as input to obtain the textured mesh. Overall, DiMeR demonstrates robust capabilities across various tasks, including sparse-view reconstruction, single-image-to-3D, and text-to-3D. Numerous experiments show that DiMeR significantly outperforms previous methods, achieving over 30% improvement in Chamfer Distance on the GSO and OmniObject3D dataset.