 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decade-Scale Benchmark Evaluating LLMs' Clinical Practice Guidelines Detection and Adherence in Multi-turn Conversations
Mar 26, 2026Clinical practice guidelines (CPGs) play a pivotal role in ensuring evidence-based decision-making and improving patient outcomes. While Large Language Models (LLMs) are increasingly deployed in healthcare scenarios, it is unclear to which extend LLMs could identify and adhere to CPGs during conversations. To address this gap, we introduce CPGBench, an automated framework benchmarking the clinical guideline detection and adherence capabilities of LLMs in multi-turn conversations. We collect 3,418 CPG documents from 9 countries/regions and 2 international organizations published in the last decade spanning across 24 specialties. From these documents, we extract 32,155 clinical recommendations with corresponding publication institute, date, country, specialty, recommendation strength, evidence level, etc. One multi-turn conversation is generated for each recommendation accordingly to evaluate the detection and adherence capabilities of 8 leading LLMs. We find that the 71.1%-89.6% recommendations can be correctly detected, while only 3.6%-29.7% corresponding titles can be correctly referenced, revealing the gap between knowing the guideline contents and where they come from. The adherence rates range from 21.8% to 63.2% in different models, indicating a large gap between knowing the guidelines and being able to apply them. To confirm the validity of our automatic analysis, we further conduct a comprehensive human evaluation involving 56 clinicians from different specialties. To our knowledge, CPGBench is the first benchmark systematically revealing which clinical recommendations LLMs fail to detect or adhere to during conversations. Given that each clinical recommendation may affect a large population and that clinical applications are inherently safety critical, addressing these gaps is crucial for the safe and responsible deployment of LLMs in real world clinical practice.
DualCoT-VLA: Visual-Linguistic Chain of Thought via Parallel Reasoning for Vision-Language-Action Models
Mar 23, 2026Vision-Language-Action (VLA) models map visual observations and language instructions directly to robotic actions. While effective for simple tasks, standard VLA models often struggle with complex, multi-step tasks requiring logical planning, as well as precise manipulations demanding fine-grained spatial perception. Recent efforts have incorporated Chain-of-Thought (CoT) reasoning to endow VLA models with a ``thinking before acting'' capability. However, current CoT-based VLA models face two critical limitations: 1) an inability to simultaneously capture low-level visual details and high-level logical planning due to their reliance on isolated, single-modal CoT; 2) high inference latency with compounding errors caused by step-by-step autoregressive decoding. To address these limitations, we propose DualCoT-VLA, a visual-linguistic CoT method for VLA models with a parallel reasoning mechanism. To achieve comprehensive multi-modal reasoning, our method integrates a visual CoT for low-level spatial understanding and a linguistic CoT for high-level task planning. Furthermore, to overcome the latency bottleneck, we introduce a parallel CoT mechanism that incorporates two sets of learnable query tokens, shifting autoregressive reasoning to single-step forward reasoning. Extensive experiments demonstrate that our DualCoT-VLA achieves state-of-the-art performance on the LIBERO and RoboCasa GR1 benchmarks, as well as in real-world platforms.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
LongLive: Real-time Interactive Long Video Generation
Sep 26, 2025We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
Advancing high-fidelity 3D and Texture Generation with 2.5D latents
May 28, 2025
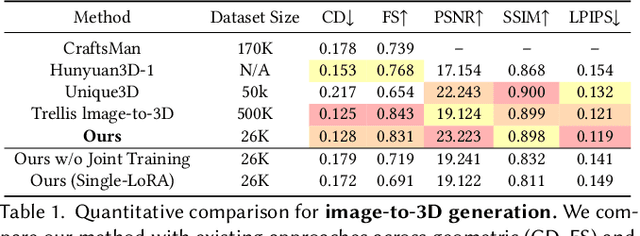
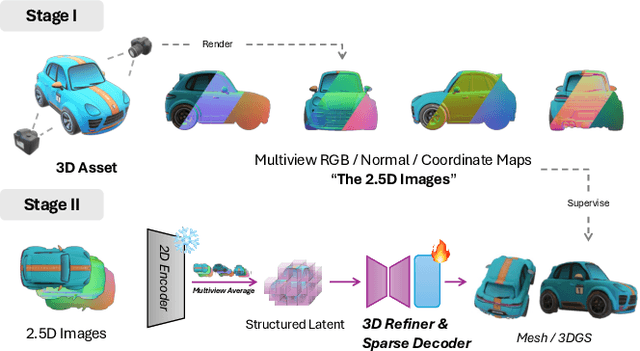
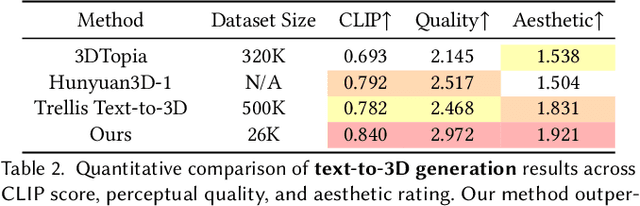
Despite the availability of large-scale 3D datasets and advancements in 3D generative models, the complexity and uneven quality of 3D geometry and texture data continue to hinder the performance of 3D generation techniques. In most existing approaches, 3D geometry and texture are generated in separate stages using different models and non-unified representations, frequently leading to unsatisfactory coherence between geometry and texture. To address these challenges, we propose a novel framework for joint generation of 3D geometry and texture. Specifically, we focus in generate a versatile 2.5D representations that can be seamlessly transformed between 2D and 3D. Our approach begins by integrating multiview RGB, normal, and coordinate images into a unified representation, termed as 2.5D latents. Next, we adapt pre-trained 2D foundation models for high-fidelity 2.5D generation, utilizing both text and image conditions. Finally, we introduce a lightweight 2.5D-to-3D refiner-decoder framework that efficiently generates detailed 3D representations from 2.5D images. Extensive experiments demonstrate that our model not only excels in generating high-quality 3D objects with coherent structure and color from text and image inputs but also significantly outperforms existing methods in geometry-conditioned texture generation.
DiMeR: Disentangled Mesh Reconstruction Model
Apr 24, 2025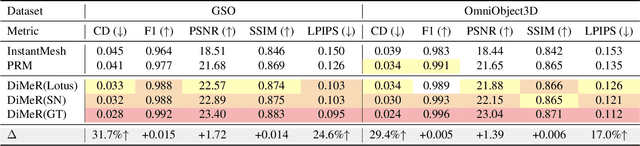

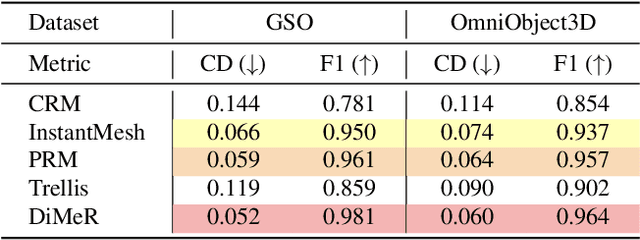
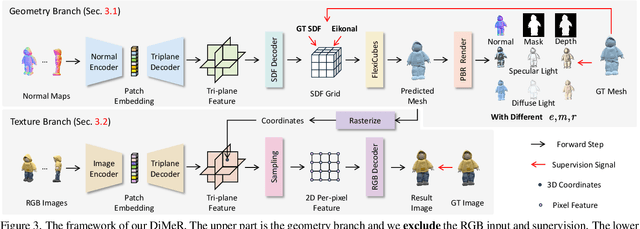
With the advent of large-scale 3D datasets, feed-forward 3D generative models, such as the Large Reconstruction Model (LRM), have gained significant attention and achieved remarkable success. However, we observe that RGB images often lead to conflicting training objectives and lack the necessary clarity for geometry reconstruction. In this paper, we revisit the inductive biases associated with mesh reconstruction and introduce DiMeR, a novel disentangled dual-stream feed-forward model for sparse-view mesh reconstruction. The key idea is to disentangle both the input and framework into geometry and texture parts, thereby reducing the training difficulty for each part according to the Principle of Occam's Razor. Given that normal maps are strictly consistent with geometry and accurately capture surface variations, we utilize normal maps as exclusive input for the geometry branch to reduce the complexity between the network's input and output. Moreover, we improve the mesh extraction algorithm to introduce 3D ground truth supervision. As for texture branch, we use RGB images as input to obtain the textured mesh. Overall, DiMeR demonstrates robust capabilities across various tasks, including sparse-view reconstruction, single-image-to-3D, and text-to-3D. Numerous experiments show that DiMeR significantly outperforms previous methods, achieving over 30% improvement in Chamfer Distance on the GSO and OmniObject3D dataset.
Long-Video Audio Synthesis with Multi-Agent Collaboration
Mar 17, 2025Video-to-audio synthesis, which generates synchronized audio for visual content, critically enhances viewer immersion and narrative coherence in film and interactive media. However, video-to-audio dubbing for long-form content remains an unsolved challenge due to dynamic semantic shifts, temporal misalignment, and the absence of dedicated datasets. While existing methods excel in short videos, they falter in long scenarios (e.g., movies) due to fragmented synthesis and inadequate cross-scene consistency. We propose LVAS-Agent, a novel multi-agent framework that emulates professional dubbing workflows through collaborative role specialization. Our approach decomposes long-video synthesis into four steps including scene segmentation, script generation, sound design and audio synthesis. Central innovations include a discussion-correction mechanism for scene/script refinement and a generation-retrieval loop for temporal-semantic alignment. To enable systematic evaluation, we introduce LVAS-Bench, the first benchmark with 207 professionally curated long videos spanning diverse scenarios. Experiments demonstrate superior audio-visual alignment over baseline methods. Project page: https://lvas-agent.github.io
Occ-LLM: Enhancing Autonomous Driving with Occupancy-Based Large Language Models
Feb 10, 2025Large Language Models (LLMs) have made substantial advancements in the field of robotic and autonomous driving. This study presents the first Occupancy-based Large Language Model (Occ-LLM), which represents a pioneering effort to integrate LLMs with an important representation. To effectively encode occupancy as input for the LLM and address the category imbalances associated with occupancy, we propose Motion Separation Variational Autoencoder (MS-VAE). This innovative approach utilizes prior knowledge to distinguish dynamic objects from static scenes before inputting them into a tailored Variational Autoencoder (VAE). This separation enhances the model's capacity to concentrate on dynamic trajectories while effectively reconstructing static scenes. The efficacy of Occ-LLM has been validated across key tasks, including 4D occupancy forecasting, self-ego planning, and occupancy-based scene question answering. Comprehensive evaluations demonstrate that Occ-LLM significantly surpasses existing state-of-the-art methodologies, achieving gains of about 6\% in Intersection over Union (IoU) and 4\% in mean Intersection over Union (mIoU) for the task of 4D occupancy forecasting. These findings highlight the transformative potential of Occ-LLM in reshaping current paradigms within robotic and autonomous driving.
TransPixar: Advancing Text-to-Video Generation with Transparency
Jan 06, 2025



Text-to-video generative models have made significant strides, enabling diverse applications in entertainment, advertising, and education. However, generating RGBA video, which includes alpha channels for transparency, remains a challenge due to limited datasets and the difficulty of adapting existing models. Alpha channels are crucial for visual effects (VFX), allowing transparent elements like smoke and reflections to blend seamlessly into scenes. We introduce TransPixar, a method to extend pretrained video models for RGBA generation while retaining the original RGB capabilities. TransPixar leverages a diffusion transformer (DiT) architecture, incorporating alpha-specific tokens and using LoRA-based fine-tuning to jointly generate RGB and alpha channels with high consistency. By optimizing attention mechanisms, TransPixar preserves the strengths of the original RGB model and achieves strong alignment between RGB and alpha channels despite limited training data. Our approach effectively generates diverse and consistent RGBA videos, advancing the possibilities for VFX and interactive content creation.
Uni-Renderer: Unifying Rendering and Inverse Rendering Via Dual Stream Diffusion
Dec 19, 2024



Rendering and inverse rendering are pivotal tasks in both computer vision and graphics. The rendering equation is the core of the two tasks, as an ideal conditional distribution transfer function from intrinsic properties to RGB images. Despite achieving promising results of existing rendering methods, they merely approximate the ideal estimation for a specific scene and come with a high computational cost. Additionally, the inverse conditional distribution transfer is intractable due to the inherent ambiguity. To address these challenges, we propose a data-driven method that jointly models rendering and inverse rendering as two conditional generation tasks within a single diffusion framework. Inspired by UniDiffuser, we utilize two distinct time schedules to model both tasks, and with a tailored dual streaming module, we achieve cross-conditioning of two pre-trained diffusion models. This unified approach, named Uni-Renderer, allows the two processes to facilitate each other through a cycle-consistent constrain, mitigating ambiguity by enforcing consistency between intrinsic properties and rendered images. Combined with a meticulously prepared dataset, our method effectively decomposition of intrinsic properties and demonstrates a strong capability to recognize changes during rendering. We will open-source our training and inference code to the public, fostering further research and development in this area.