 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mechanistic View on Video Generation as World Models: State and Dynamics
Jan 22, 2026Large-scale video generation models have demonstrated emergent physical coherence, positioning them as potential world models. However, a gap remains between contemporary "stateless" video architectures and classic state-centric world model theories. This work bridges this gap by proposing a novel taxonomy centered on two pillars: State Construction and Dynamics Modeling. We categorize state construction into implicit paradigms (context management) and explicit paradigms (latent compression), while dynamics modeling is analyzed through knowledge integration and architectural reformulation. Furthermore, we advocate for a transition in evaluation from visual fidelity to functional benchmarks, testing physical persistence and causal reasoning. We conclude by identifying two critical frontiers: enhancing persistence via data-driven memory and compressed fidelity, and advancing causality through latent factor decoupling and reasoning-prior integration. By addressing these challenges, the field can evolve from generating visually plausible videos to building robust, general-purpose world simulators.
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
Kiss3DGen: Repurposing Image Diffusion Models for 3D Asset Generation
Mar 03, 2025



Diffusion models have achieved great success in generating 2D images. However, the quality and generalizability of 3D content generation remain limited. State-of-the-art methods often require large-scale 3D assets for training, which are challenging to collect. In this work, we introduce Kiss3DGen (Keep It Simple and Straightforward in 3D Generation), an efficient framework for generating, editing, and enhancing 3D objects by repurposing a well-trained 2D image diffusion model for 3D generation. Specifically, we fine-tune a diffusion model to generate ''3D Bundle Image'', a tiled representation composed of multi-view images and their corresponding normal maps. The normal maps are then used to reconstruct a 3D mesh, and the multi-view images provide texture mapping, resulting in a complete 3D model. This simple method effectively transforms the 3D generation problem into a 2D image generation task, maximizing the utilization of knowledge in pretrained diffusion models. Furthermore, we demonstrate that our Kiss3DGen model is compatible with various diffusion model techniques, enabling advanced features such as 3D editing, mesh and texture enhancement, etc. Through extensive experiments, we demonstrate the effectiveness of our approach, showcasing its ability to produce high-quality 3D models efficiently.
Uni-Renderer: Unifying Rendering and Inverse Rendering Via Dual Stream Diffusion
Dec 19, 2024



Rendering and inverse rendering are pivotal tasks in both computer vision and graphics. The rendering equation is the core of the two tasks, as an ideal conditional distribution transfer function from intrinsic properties to RGB images. Despite achieving promising results of existing rendering methods, they merely approximate the ideal estimation for a specific scene and come with a high computational cost. Additionally, the inverse conditional distribution transfer is intractable due to the inherent ambiguity. To address these challenges, we propose a data-driven method that jointly models rendering and inverse rendering as two conditional generation tasks within a single diffusion framework. Inspired by UniDiffuser, we utilize two distinct time schedules to model both tasks, and with a tailored dual streaming module, we achieve cross-conditioning of two pre-trained diffusion models. This unified approach, named Uni-Renderer, allows the two processes to facilitate each other through a cycle-consistent constrain, mitigating ambiguity by enforcing consistency between intrinsic properties and rendered images. Combined with a meticulously prepared dataset, our method effectively decomposition of intrinsic properties and demonstrates a strong capability to recognize changes during rendering. We will open-source our training and inference code to the public, fostering further research and development in this area.
GaussianProperty: Integrating Physical Properties to 3D Gaussians with LMMs
Dec 15, 2024Estimating physical properties for visual data is a crucial task in computer vision, graphics, and robotics, underpinning applications such as augmented reality, physical simulation, and robotic grasping. However, this area remains under-explored due to the inherent ambiguities in physical property estimation. To address these challenges, we introduce GaussianProperty, a training-free framework that assigns physical properties of materials to 3D Gaussians. Specifically, we integrate the segmentation capability of SAM with the recognition capability of GPT-4V(ision) to formulate a global-local physical property reasoning module for 2D images. Then we project the physical properties from multi-view 2D images to 3D Gaussians using a voting strategy. We demonstrate that 3D Gaussians with physical property annotations enable applications in physics-based dynamic simulation and robotic grasping. For physics-based dynamic simulation, we leverage the Material Point Method (MPM) for realistic dynamic simulation. For robot grasping, we develop a grasping force prediction strategy that estimates a safe force range required for object grasping based on the estimated physical properties. Extensive experiments on material segmentation, physics-based dynamic simulation, and robotic grasping validate the effectiveness of our proposed method, highlighting its crucial role in understanding physical properties from visual data. Online demo, code, more cases and annotated datasets are available on \href{https://Gaussian-Property.github.io}{this https URL}.
MSI-NeRF: Linking Omni-Depth with View Synthesis through Multi-Sphere Image aided Generalizable Neural Radiance Field
Mar 16, 2024



Panoramic observation using fisheye cameras is significant in robot perception, reconstruction, and remote operation. However, panoramic images synthesized by traditional methods lack depth information and can only provide three degrees-of-freedom (3DoF) rotation rendering in virtual reality applications. To fully preserve and exploit the parallax information within the original fisheye cameras, we introduce MSI-NeRF, which combines deep learning omnidirectional depth estimation and novel view rendering. We first construct a multi-sphere image as a cost volume through feature extraction and warping of the input images. It is then processed by geometry and appearance decoders, respectively. Unlike methods that regress depth maps directly, we further build an implicit radiance field using spatial points and interpolated 3D feature vectors as input. In this way, we can simultaneously realize omnidirectional depth estimation and 6DoF view synthesis. Our method is trained in a semi-self-supervised manner. It does not require target view images and only uses depth data for supervision. Our network has the generalization ability to reconstruct unknown scenes efficiently using only four images. Experimental results show that our method outperforms existing methods in depth estimation and novel view synthesis tasks.
Active Implicit Object Reconstruction using Uncertainty-guided Next-Best-View Optimziation
Mar 29, 2023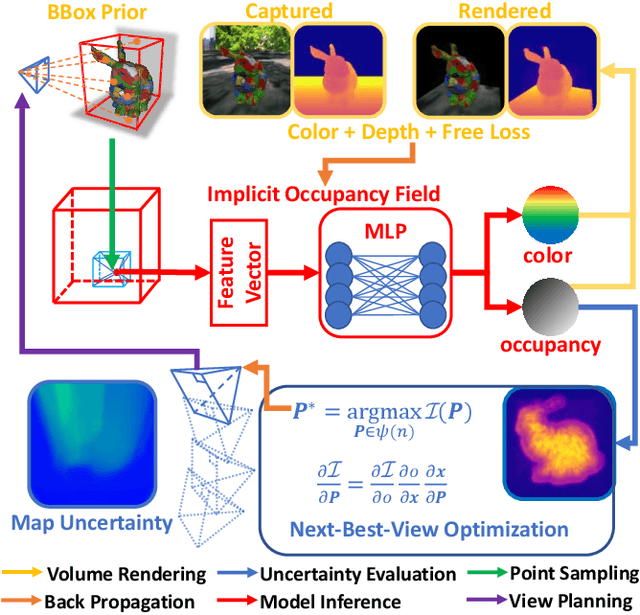


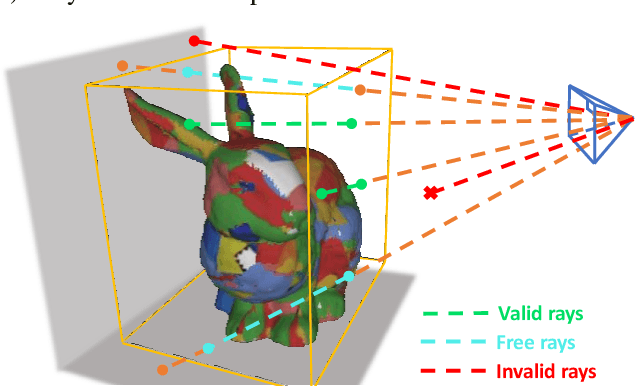
Actively planning sensor views during object reconstruction is essential to autonomous mobile robots. This task is usually performed by evaluating information gain from an explicit uncertainty map. Existing algorithms compare options among a set of preset candidate views and select the next-best-view from them. In contrast to these, we take the emerging implicit representation as the object model and seamlessly combine it with the active reconstruction task. To fully integrate observation information into the model, we propose a supervision method specifically for object-level reconstruction that considers both valid and free space. Additionally, to directly evaluate view information from the implicit object model, we introduce a sample-based uncertainty evaluation method. It samples points on rays directly from the object model and uses variations of implicit function inferences as the uncertainty metrics, with no need for voxel traversal or an additional information map. Leveraging the differentiability of our metrics, it is possible to optimize the next-best-view by maximizing the uncertainty continuously. This does away with the traditionally-used candidate views setting, which may provide sub-optimal results. Experiments in simulations and real-world scenes show that our method effectively improves the reconstruction accuracy and the view-planning efficiency of active reconstruction tasks. The proposed system is going to open source at https://github.com/HITSZ-NRSL/ActiveImplicitRecon.git.
Learning a Room with the Occ-SDF Hybrid: Signed Distance Function Mingled with Occupancy Aids Scene Representation
Mar 16, 2023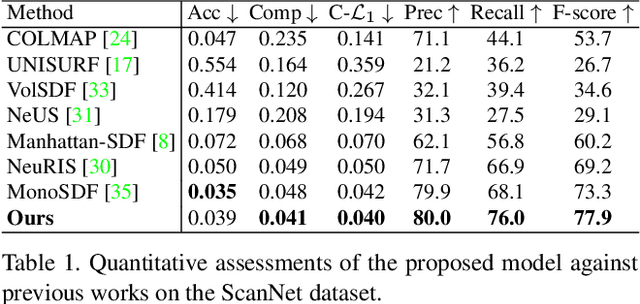
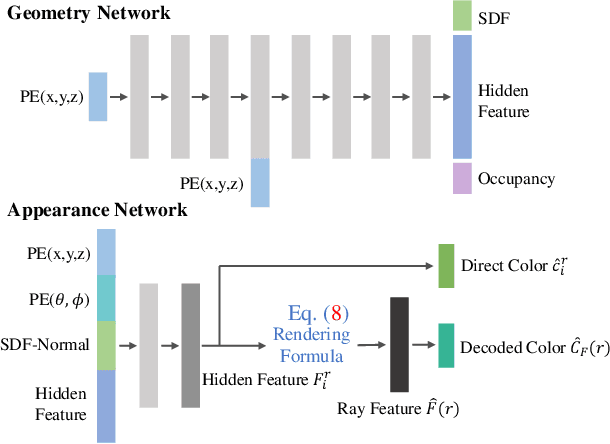
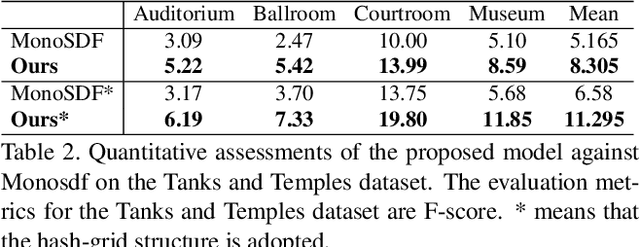

Implicit neural rendering, which uses signed distance function (SDF) representation with geometric priors (such as depth or surface normal), has led to impressive progress in the surface reconstruction of large-scale scenes. However, applying this method to reconstruct a room-level scene from images may miss structures in low-intensity areas or small and thin objects. We conducted experiments on three datasets to identify limitations of the original color rendering loss and priors-embedded SDF scene representation. We found that the color rendering loss results in optimization bias against low-intensity areas, causing gradient vanishing and leaving these areas unoptimized. To address this issue, we propose a feature-based color rendering loss that utilizes non-zero feature values to bring back optimization signals. Additionally, the SDF representation can be influenced by objects along a ray path, disrupting the monotonic change of SDF values when a single object is present. To counteract this, we explore using the occupancy representation, which encodes each point separately and is unaffected by objects along a querying ray. Our experimental results demonstrate that the joint forces of the feature-based rendering loss and Occ-SDF hybrid representation scheme can provide high-quality reconstruction results, especially in challenging room-level scenarios. The code would be released.
Efficient Implicit Neural Reconstruction Using LiDAR
Feb 28, 2023



Modeling scene geometry using implicit neural representation has revealed its advantages in accuracy, flexibility, and low memory usage. Previous approaches have demonstrated impressive results using color or depth images but still have difficulty handling poor light conditions and large-scale scenes. Methods taking global point cloud as input require accurate registration and ground truth coordinate labels, which limits their application scenarios. In this paper, we propose a new method that uses sparse LiDAR point clouds and rough odometry to reconstruct fine-grained implicit occupancy field efficiently within a few minutes. We introduce a new loss function that supervises directly in 3D space without 2D rendering, avoiding information loss. We also manage to refine poses of input frames in an end-to-end manner, creating consistent geometry without global point cloud registration. As far as we know, our method is the first to reconstruct implicit scene representation from LiDAR-only input. Experiments on synthetic and real-world datasets, including indoor and outdoor scenes, prove that our method is effective, efficient, and accurate, obtaining comparable results with existing methods using dense input.