 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKiss3DGen: Repurposing Image Diffusion Models for 3D Asset Generation
Mar 03, 2025



Diffusion models have achieved great success in generating 2D images. However, the quality and generalizability of 3D content generation remain limited. State-of-the-art methods often require large-scale 3D assets for training, which are challenging to collect. In this work, we introduce Kiss3DGen (Keep It Simple and Straightforward in 3D Generation), an efficient framework for generating, editing, and enhancing 3D objects by repurposing a well-trained 2D image diffusion model for 3D generation. Specifically, we fine-tune a diffusion model to generate ''3D Bundle Image'', a tiled representation composed of multi-view images and their corresponding normal maps. The normal maps are then used to reconstruct a 3D mesh, and the multi-view images provide texture mapping, resulting in a complete 3D model. This simple method effectively transforms the 3D generation problem into a 2D image generation task, maximizing the utilization of knowledge in pretrained diffusion models. Furthermore, we demonstrate that our Kiss3DGen model is compatible with various diffusion model techniques, enabling advanced features such as 3D editing, mesh and texture enhancement, etc. Through extensive experiments, we demonstrate the effectiveness of our approach, showcasing its ability to produce high-quality 3D models efficiently.
Watertox: The Art of Simplicity in Universal Attacks A Cross-Model Framework for Robust Adversarial Generation
Dec 20, 2024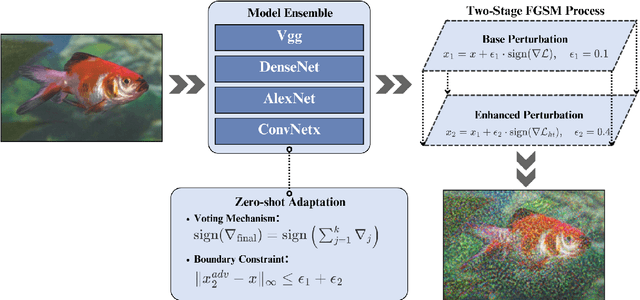
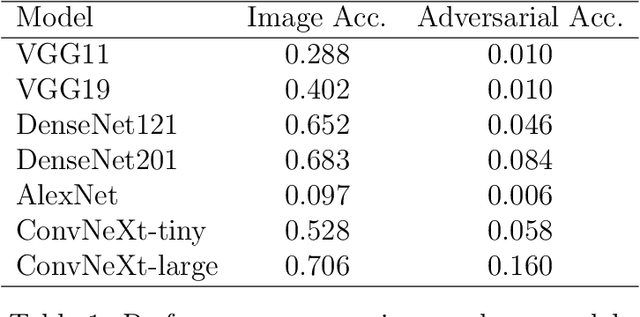
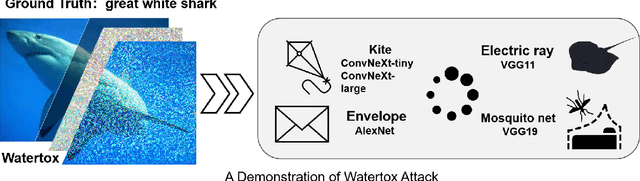
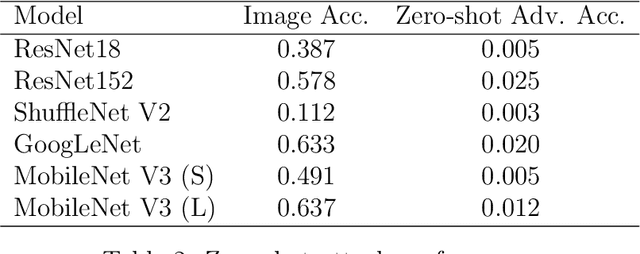
Contemporary adversarial attack methods face significant limitations in cross-model transferability and practical applicability. We present Watertox, an elegant adversarial attack framework achieving remarkable effectiveness through architectural diversity and precision-controlled perturbations. Our two-stage Fast Gradient Sign Method combines uniform baseline perturbations ($\epsilon_1 = 0.1$) with targeted enhancements ($\epsilon_2 = 0.4$). The framework leverages an ensemble of complementary architectures, from VGG to ConvNeXt, synthesizing diverse perspectives through an innovative voting mechanism. Against state-of-the-art architectures, Watertox reduces model accuracy from 70.6% to 16.0%, with zero-shot attacks achieving up to 98.8% accuracy reduction against unseen architectures. These results establish Watertox as a significant advancement in adversarial methodologies, with promising applications in visual security systems and CAPTCHA generation.
Improving Few-Shot Performance of Language Models via Nearest Neighbor Calibration
Dec 05, 2022



Pre-trained language models (PLMs) have exhibited remarkable few-shot learning capabilities when provided a few examples in a natural language prompt as demonstrations of test instances, i.e., in-context learning. However, the performance of in-context learning is susceptible to the choice of prompt format, training examples and the ordering of the training examples. In this paper, we propose a novel nearest-neighbor calibration framework for in-context learning to ease this issue. It is inspired by a phenomenon that the in-context learning paradigm produces incorrect labels when inferring training instances, which provides a useful supervised signal to calibrate predictions. Thus, our method directly augments the predictions with a $k$-nearest-neighbor ($k$NN) classifier over a datastore of cached few-shot instance representations obtained by PLMs and their corresponding labels. Then adaptive neighbor selection and feature regularization modules are introduced to make full use of a few support instances to reduce the $k$NN retrieval noise. Experiments on various few-shot text classification tasks demonstrate that our method significantly improves in-context learning, while even achieving comparable performance with state-of-the-art tuning-based approaches in some sentiment analysis tasks.