 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Few-Shot Performance of Language Models via Nearest Neighbor Calibration
Dec 05, 2022



Pre-trained language models (PLMs) have exhibited remarkable few-shot learning capabilities when provided a few examples in a natural language prompt as demonstrations of test instances, i.e., in-context learning. However, the performance of in-context learning is susceptible to the choice of prompt format, training examples and the ordering of the training examples. In this paper, we propose a novel nearest-neighbor calibration framework for in-context learning to ease this issue. It is inspired by a phenomenon that the in-context learning paradigm produces incorrect labels when inferring training instances, which provides a useful supervised signal to calibrate predictions. Thus, our method directly augments the predictions with a $k$-nearest-neighbor ($k$NN) classifier over a datastore of cached few-shot instance representations obtained by PLMs and their corresponding labels. Then adaptive neighbor selection and feature regularization modules are introduced to make full use of a few support instances to reduce the $k$NN retrieval noise. Experiments on various few-shot text classification tasks demonstrate that our method significantly improves in-context learning, while even achieving comparable performance with state-of-the-art tuning-based approaches in some sentiment analysis tasks.
Program Enhanced Fact Verification with Verbalization and Graph Attention Network
Oct 14, 2020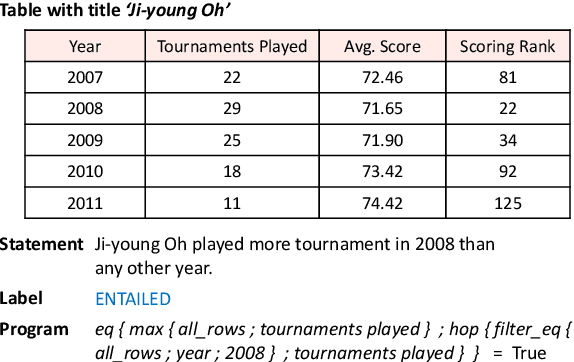

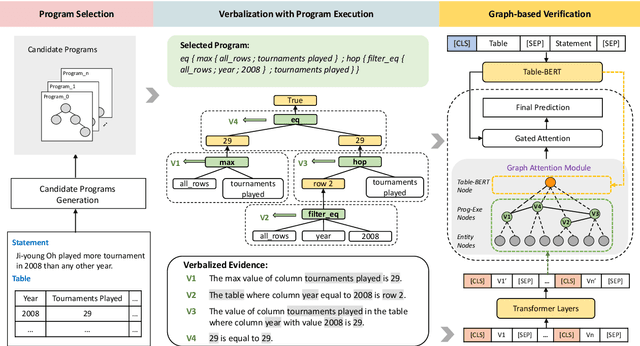

Performing fact verification based on structured data is important for many real-life applications and is a challenging research problem, particularly when it involves both symbolic operations and informal inference based on language understanding. In this paper, we present a Program-enhanced Verbalization and Graph Attention Network (ProgVGAT) to integrate programs and execution into textual inference models. Specifically, a verbalization with program execution model is proposed to accumulate evidences that are embedded in operations over the tables. Built on that, we construct the graph attention verification networks, which are designed to fuse different sources of evidences from verbalized program execution, program structures, and the original statements and tables, to make the final verification decision. To support the above framework, we propose a program selection module optimized with a new training strategy based on margin loss, to produce more accurate programs, which is shown to be effective in enhancing the final verification results. Experimental results show that the proposed framework achieves the new state-of-the-art performance, a 74.4% accuracy, on the benchmark dataset TABFACT.
Operations Guided Neural Networks for High Fidelity Data-To-Text Generation
Sep 08, 2018
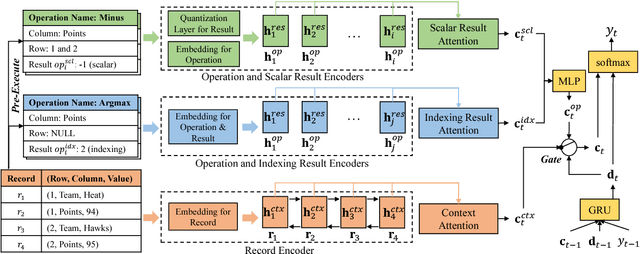

Recent neural models for data-to-text generation are mostly based on data-driven end-to-end training over encoder-decoder networks. Even though the generated texts are mostly fluent and informative, they often generate descriptions that are not consistent with the input structured data. This is a critical issue especially in domains that require inference or calculations over raw data. In this paper, we attempt to improve the fidelity of neural data-to-text generation by utilizing pre-executed symbolic operations. We propose a framework called Operation-guided Attention-based sequence-to-sequence network (OpAtt), with a specifically designed gating mechanism as well as a quantization module for operation results to utilize information from pre-executed operations. Experiments on two sports datasets show our proposed method clearly improves the fidelity of the generated texts to the input structured data.
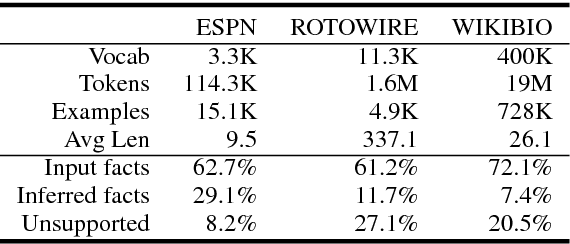
Incorporating Consistency Verification into Neural Data-to-Document Generation
Aug 18, 2018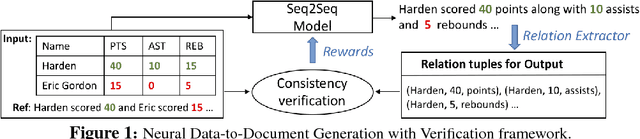
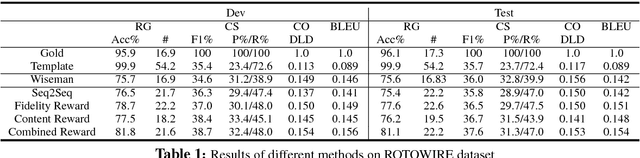
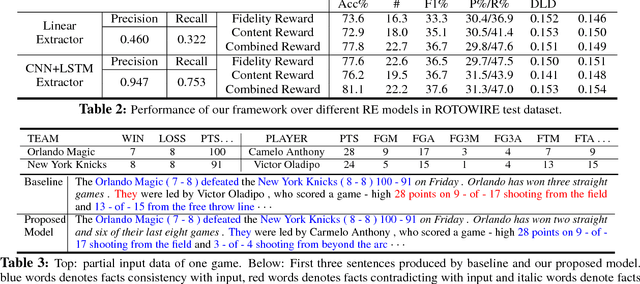
Recent neural models for data-to-document generation have achieved remarkable progress in producing fluent and informative texts. However, large proportions of generated texts do not actually conform to the input data. To address this issue, we propose a new training framework which attempts to verify the consistency between the generated texts and the input data to guide the training process. To measure the consistency, a relation extraction model is applied to check information overlaps between the input data and the generated texts. The non-differentiable consistency signal is optimized via reinforcement learning. Experimental results on a recently released challenging dataset ROTOWIRE show improvements from our framework in various metrics.