 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructTest: Benchmarking LLMs' Reasoning through Compositional Structured Outputs
Dec 23, 2024



The rapid development of large language models (LLMs) necessitates robust, unbiased, and scalable methods for evaluating their capabilities. However, human annotations are expensive to scale, model-based evaluations are prone to biases in answer style, while target-answer-based benchmarks are vulnerable to data contamination and cheating. To address these limitations, we propose StructTest, a novel benchmark that evaluates LLMs on their ability to produce compositionally specified structured outputs as an unbiased, cheap-to-run and difficult-to-cheat measure. The evaluation is done deterministically by a rule-based evaluator, which can be easily extended to new tasks. By testing structured outputs across diverse task domains -- including Summarization, Code, HTML and Math -- we demonstrate that StructTest serves as a good proxy for general reasoning abilities, as producing structured outputs often requires internal logical reasoning. We believe that StructTest offers a critical, complementary approach to objective and robust model evaluation.
SFR-RAG: Towards Contextually Faithful LLMs
Sep 16, 2024Retrieval Augmented Generation (RAG), a paradigm that integrates external contextual information with large language models (LLMs) to enhance factual accuracy and relevance, has emerged as a pivotal area in generative AI. The LLMs used in RAG applications are required to faithfully and completely comprehend the provided context and users' questions, avoid hallucination, handle unanswerable, counterfactual or otherwise low-quality and irrelevant contexts, perform complex multi-hop reasoning and produce reliable citations. In this paper, we introduce SFR-RAG, a small LLM that is instruction-tuned with an emphasis on context-grounded generation and hallucination minimization. We also present ContextualBench, a new evaluation framework compiling multiple popular and diverse RAG benchmarks, such as HotpotQA and TriviaQA, with consistent RAG settings to ensure reproducibility and consistency in model assessments. Experimental results demonstrate that our SFR-RAG-9B model outperforms leading baselines such as Command-R+ (104B) and GPT-4o, achieving state-of-the-art results in 3 out of 7 benchmarks in ContextualBench with significantly fewer parameters. The model is also shown to be resilient to alteration in the contextual information and behave appropriately when relevant context is removed. Additionally, the SFR-RAG model maintains competitive performance in general instruction-following tasks and function-calling capabilities.
How Much are LLMs Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mar 31, 2024With the rise of Large Language Models (LLMs) in recent years, new opportunities are emerging, but also new challenges, and contamination is quickly becoming critical. Business applications and fundraising in AI have reached a scale at which a few percentage points gained on popular question-answering benchmarks could translate into dozens of millions of dollars, placing high pressure on model integrity. At the same time, it is becoming harder and harder to keep track of the data that LLMs have seen; if not impossible with closed-source models like GPT-4 and Claude-3 not divulging any information on the training set. As a result, contamination becomes a critical issue: LLMs' performance may not be reliable anymore, as the high performance may be at least partly due to their previous exposure to the data. This limitation jeopardizes the entire progress in the field of NLP, yet, there remains a lack of methods on how to efficiently address contamination, or a clear consensus on prevention, mitigation and classification of contamination. In this paper, we survey all recent work on contamination with LLMs, and help the community track contamination levels of LLMs by releasing an open-source Python library named LLMSanitize implementing major contamination detection algorithms, which link is: https://github.com/ntunlp/LLMSanitize.
ChatGPT's One-year Anniversary: Are Open-Source Large Language Models Catching up?
Dec 05, 2023



Upon its release in late 2022, ChatGPT has brought a seismic shift in the entire landscape of AI, both in research and commerce. Through instruction-tuning a large language model (LLM) with supervised fine-tuning and reinforcement learning from human feedback, it showed that a model could answer human questions and follow instructions on a broad panel of tasks. Following this success, interests in LLMs have intensified, with new LLMs flourishing at frequent interval across academia and industry, including many start-ups focused on LLMs. While closed-source LLMs (e.g., OpenAI's GPT, Anthropic's Claude) generally outperform their open-source counterparts, the progress on the latter has been rapid with claims of achieving parity or even better on certain tasks. This has crucial implications not only on research but also on business. In this work, on the first anniversary of ChatGPT, we provide an exhaustive overview of this success, surveying all tasks where an open-source LLM has claimed to be on par or better than ChatGPT.
Personalised Distillation: Empowering Open-Sourced LLMs with Adaptive Learning for Code Generation
Oct 28, 2023



With the rise of powerful closed-sourced LLMs (ChatGPT, GPT-4), there are increasing interests in distilling the capabilies of close-sourced LLMs to smaller open-sourced LLMs. Previous distillation methods usually prompt ChatGPT to generate a set of instructions and answers, for the student model to learn. However, such standard distillation approach neglects the merits and conditions of the student model. Inspired by modern teaching principles, we design a personalised distillation process, in which the student attempts to solve a task first, then the teacher provides an adaptive refinement for the student to improve. Instead of feeding the student with teacher's prior, personalised distillation enables personalised learning for the student model, as it only learns on examples it makes mistakes upon and learns to improve its own solution. On code generation, personalised distillation consistently outperforms standard distillation with only one third of the data. With only 2.5-3K personalised examples that incur a data-collection cost of 4-6$, we boost CodeGen-mono-16B by 7% to achieve 36.4% pass@1 and StarCoder by 12.2% to achieve 45.8% pass@1 on HumanEval.
CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules
Oct 13, 2023Large Language Models (LLMs) have already become quite proficient at solving simpler programming tasks like those in HumanEval or MBPP benchmarks. However, solving more complex and competitive programming tasks is still quite challenging for these models - possibly due to their tendency to generate solutions as monolithic code blocks instead of decomposing them into logical sub-tasks and sub-modules. On the other hand, experienced programmers instinctively write modularized code with abstraction for solving complex tasks, often reusing previously developed modules. To address this gap, we propose CodeChain, a novel framework for inference that elicits modularized code generation through a chain of self-revisions, each being guided by some representative sub-modules generated in previous iterations. Concretely, CodeChain first instructs the LLM to generate modularized codes through chain-of-thought prompting. Then it applies a chain of self-revisions by iterating the two steps: 1) extracting and clustering the generated sub-modules and selecting the cluster representatives as the more generic and re-usable implementations, and 2) augmenting the original chain-of-thought prompt with these selected module-implementations and instructing the LLM to re-generate new modularized solutions. We find that by naturally encouraging the LLM to reuse the previously developed and verified sub-modules, CodeChain can significantly boost both modularity as well as correctness of the generated solutions, achieving relative pass@1 improvements of 35% on APPS and 76% on CodeContests. It is shown to be effective on both OpenAI LLMs as well as open-sourced LLMs like WizardCoder. We also conduct comprehensive ablation studies with different methods of prompting, number of clusters, model sizes, program qualities, etc., to provide useful insights that underpin CodeChain's success.
PromptSum: Parameter-Efficient Controllable Abstractive Summarization
Aug 06, 2023



Prompt tuning (PT), a parameter-efficient technique that only tunes the additional prompt embeddings while keeping the backbone pre-trained language model (PLM) frozen, has shown promising results in language understanding tasks, especially in low-resource scenarios. However, effective prompt design methods suitable for generation tasks such as summarization are still lacking. At the same time, summarization guided through instructions (discrete prompts) can achieve a desirable double objective of high quality and controllability in summary generation. Towards a goal of strong summarization performance under the triple conditions of parameter-efficiency, data-efficiency, and controllability, we introduce PromptSum, a method combining PT with a multi-task objective and discrete entity prompts for abstractive summarization. Our model achieves competitive ROUGE results on popular abstractive summarization benchmarks coupled with a strong level of controllability through entities, all while only tuning several orders of magnitude less parameters.
Retrieving Multimodal Information for Augmented Generation: A Survey
Mar 20, 2023

In this survey, we review methods that retrieve multimodal knowledge to assist and augment generative models. This group of works focuses on retrieving grounding contexts from external sources, including images, codes, tables, graphs, and audio. As multimodal learning and generative AI have become more and more impactful, such retrieval augmentation offers a promising solution to important concerns such as factuality, reasoning, interpretability, and robustness. We provide an in-depth review of retrieval-augmented generation in different modalities and discuss potential future directions. As this is an emerging field, we continue to add new papers and methods.
Learning Label Modular Prompts for Text Classification in the Wild
Dec 05, 2022Machine learning models usually assume i.i.d data during training and testing, but data and tasks in real world often change over time. To emulate the transient nature of real world, we propose a challenging but practical task: text classification in-the-wild, which introduces different non-stationary training/testing stages. Decomposing a complex task into modular components can enable robust generalisation under such non-stationary environment. However, current modular approaches in NLP do not take advantage of recent advances in parameter efficient tuning of pretrained language models. To close this gap, we propose MODULARPROMPT, a label-modular prompt tuning framework for text classification tasks. In MODULARPROMPT, the input prompt consists of a sequence of soft label prompts, each encoding modular knowledge related to the corresponding class label. In two of most formidable settings, MODULARPROMPT outperforms relevant baselines by a large margin demonstrating strong generalisation ability. We also conduct comprehensive analysis to validate whether the learned prompts satisfy properties of a modular representation.
Incorporating Consistency Verification into Neural Data-to-Document Generation
Aug 18, 2018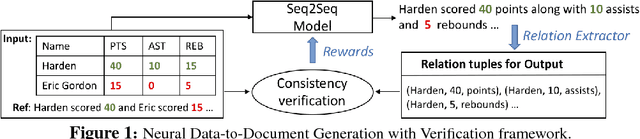
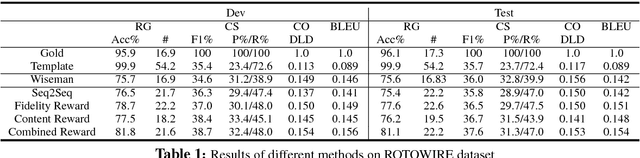
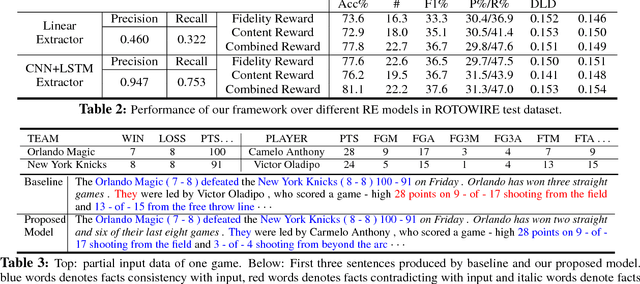
Recent neural models for data-to-document generation have achieved remarkable progress in producing fluent and informative texts. However, large proportions of generated texts do not actually conform to the input data. To address this issue, we propose a new training framework which attempts to verify the consistency between the generated texts and the input data to guide the training process. To measure the consistency, a relation extraction model is applied to check information overlaps between the input data and the generated texts. The non-differentiable consistency signal is optimized via reinforcement learning. Experimental results on a recently released challenging dataset ROTOWIRE show improvements from our framework in various metrics.