 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Predefined Schemas: TRACE-KG for Context-Enriched Knowledge Graphs from Complex Documents
Apr 03, 2026Knowledge graph construction typically relies either on predefined ontologies or on schema-free extraction. Ontology-driven pipelines enforce consistent typing but require costly schema design and maintenance, whereas schema-free methods often produce fragmented graphs with weak global organization, especially in long technical documents with dense, context-dependent information. We propose TRACE-KG (Text-dRiven schemA for Context-Enriched Knowledge Graphs), a multimodal framework that jointly constructs a context-enriched knowledge graph and an induced schema without assuming a predefined ontology. TRACE-KG captures conditional relations through structured qualifiers and organizes entities and relations using a data-driven schema that serves as a reusable semantic scaffold while preserving full traceability to the source evidence. Experiments show that TRACE-KG produces structurally coherent, traceable knowledge graphs and offers a practical alternative to both ontology-driven and schema-free construction pipelines.
Aligning Multimodal Sequential Recommendations via Robust Direct Preference Optimization with Sparse MoE
Mar 31, 2026Preference-based alignment objectives have been widely adopted, from RLHF-style pairwise learning in large language models to emerging applications in recommender systems. Yet, existing work rarely examines how Direct Preference Optimization (DPO) behaves under implicit feedback, where unobserved items are not reliable negatives. We conduct systematic experiments on multimodal sequential recommendation to compare common negative-selection strategies and their interaction with DPO training. Our central finding is that a simple modification, replacing deterministic hard negatives with stochastic sampling from a dynamic top-K candidate pool, consistently improves ranking performance. We attribute its effectiveness to two factors: (1) reducing erroneous suppressive gradients caused by false negatives, and (2) retaining informative hard signals while smoothing optimization via controlled stochasticity. With an optional sparse Mixture-of-Experts encoder for efficient capacity scaling, RoDPO achieves up to 5.25% NDCG@5 on three Amazon benchmarks, with nearly unchanged inference cost.
FedFG: Privacy-Preserving and Robust Federated Learning via Flow-Matching Generation
Mar 30, 2026Federated learning (FL) enables distributed clients to collaboratively train a global model using local private data. Nevertheless, recent studies show that conventional FL algorithms still exhibit deficiencies in privacy protection, and the server lacks a reliable and stable aggregation rule for updating the global model. This situation creates opportunities for adversaries: on the one hand, they may eavesdrop on uploaded gradients or model parameters, potentially leaking benign clients' private data; on the other hand, they may compromise clients to launch poisoning attacks that corrupt the global model. To balance accuracy and security, we propose FedFG, a robust FL framework based on flow-matching generation that simultaneously preserves client privacy and resists sophisticated poisoning attacks. On the client side, each local network is decoupled into a private feature extractor and a public classifier. Each client is further equipped with a flow-matching generator that replaces the extractor when interacting with the server, thereby protecting private features while learning an approximation of the underlying data distribution. Complementing the client-side design, the server employs a client-update verification scheme and a novel robust aggregation mechanism driven by synthetic samples produced by the flow-matching generator. Experiments on MNIST, FMNIST, and CIFAR-10 demonstrate that, compared with prior work, our approach adapts to multiple attack strategies and achieves higher accuracy while maintaining strong privacy protection.
MemArchitect: A Policy Driven Memory Governance Layer
Mar 18, 2026Persistent Large Language Model (LLM) agents expose a critical governance gap in memory management. Standard Retrieval-Augmented Generation (RAG) frameworks treat memory as passive storage, lacking mechanisms to resolve contradictions, enforce privacy, or prevent outdated information ("zombie memories") from contaminating the context window. We introduce MemArchitect, a governance layer that decouples memory lifecycle management from model weights. MemArchitect enforces explicit, rule-based policies, including memory decay, conflict resolution, and privacy controls. We demonstrate that governed memory consistently outperforms unmanaged memory in agentic settings, highlighting the necessity of structured memory governance for reliable and safe autonomous systems.
Fusian: Multi-LoRA Fusion for Fine-Grained Continuous MBTI Personality Control in Large Language Models
Mar 16, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in simulating diverse human behaviors and personalities. However, existing methods for personality control, which include prompt engineering and standard Supervised Fine-Tuning (SFT), typically treat personality traits as discrete categories (e.g., "Extroverted" vs. "Introverted"), lacking the ability to precisely control the intensity of a trait on a continuous spectrum. In this paper, we introduce Fusian, a novel framework for fine-grained, continuous personality control in LLMs. Fusian operates in two stages: (1) Trajectory Collection, where we capture the dynamic evolution of personality adoption during SFT by saving a sequence of LoRA adapters, effectively mapping the continuous manifold of a trait; and (2) RL-based Dynamic Fusion, where we train a policy network using Reinforcement Learning to dynamically compute mixing weights for these frozen adapters. By sampling from a Dirichlet distribution parameterized by the policy network, Fusian fuses multiple adapters to align the model's output with a specific numerical target intensity. Experiments on the Qwen3-14B model demonstrate that Fusian achieves high precision in personality control, significantly outperforming baseline methods in aligning with user-specified trait intensities.
Measuring Dataset Diversity from a Geometric Perspective
Feb 10, 2026Diversity can be broadly defined as the presence of meaningful variation across elements, which can be viewed from multiple perspectives, including statistical variation and geometric structural richness in the dataset. Existing diversity metrics, such as feature-space dispersion and metric-space magnitude, primarily capture distributional variation or entropy, while largely neglecting the geometric structure of datasets. To address this gap, we introduce a framework based on topological data analysis (TDA) and persistence landscapes (PLs) to extract and quantify geometric features from data. This approach provides a theoretically grounded means of measuring diversity beyond entropy, capturing the rich geometric and structural properties of datasets. Through extensive experiments across diverse modalities, we demonstrate that our proposed PLs-based diversity metric (PLDiv) is powerful, reliable, and interpretable, directly linking data diversity to its underlying geometry and offering a foundational tool for dataset construction, augmentation, and evaluation.
Active Learning for Multiple Change Point Detection in Non-stationary Time Series with Deep Gaussian Processes
May 26, 2025Multiple change point (MCP) detection in non-stationary time series is challenging due to the variety of underlying patterns. To address these challenges, we propose a novel algorithm that integrates Active Learning (AL) with Deep Gaussian Processes (DGPs) for robust MCP detection. Our method leverages spectral analysis to identify potential changes and employs AL to strategically select new sampling points for improved efficiency. By incorporating the modeling flexibility of DGPs with the change-identification capabilities of spectral methods, our approach adapts to diverse spectral change behaviors and effectively localizes multiple change points. Experiments on both simulated and real-world data demonstrate that our method outperforms existing techniques in terms of detection accuracy and sampling efficiency for non-stationary time series.
From Observation to Orientation: an Adaptive Integer Programming Approach to Intervention Design
Apr 10, 2025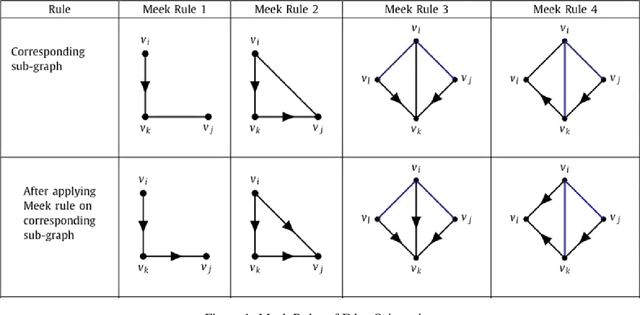

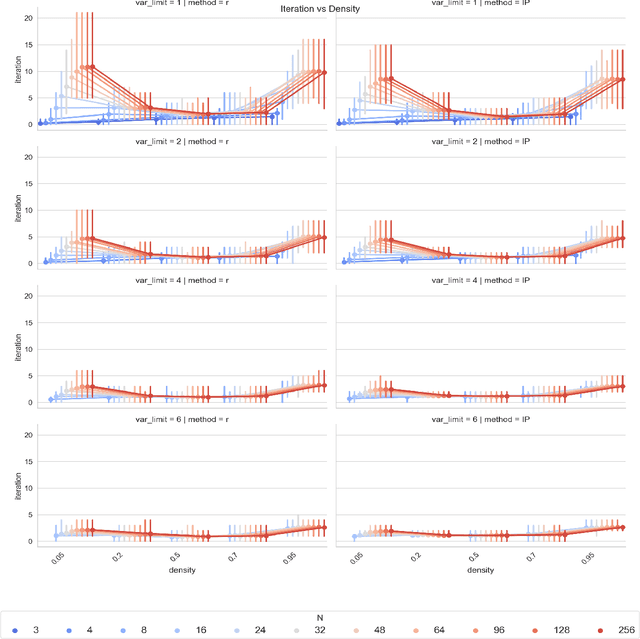

Using both observational and experimental data, a causal discovery process can identify the causal relationships between variables. A unique adaptive intervention design paradigm is presented in this work, where causal directed acyclic graphs (DAGs) are for effectively recovered with practical budgetary considerations. In order to choose treatments that optimize information gain under these considerations, an iterative integer programming (IP) approach is proposed, which drastically reduces the number of experiments required. Simulations over a broad range of graph sizes and edge densities are used to assess the effectiveness of the suggested approach. Results show that the proposed adaptive IP approach achieves full causal graph recovery with fewer intervention iterations and variable manipulations than random intervention baselines, and it is also flexible enough to accommodate a variety of practical constraints.
SVGBuilder: Component-Based Colored SVG Generation with Text-Guided Autoregressive Transformers
Dec 17, 2024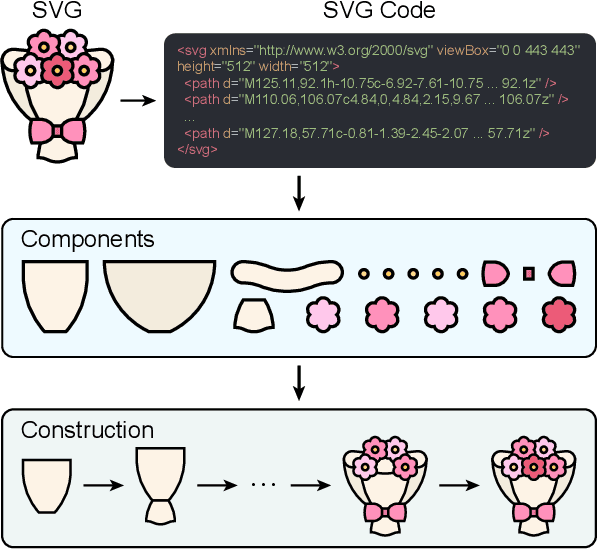
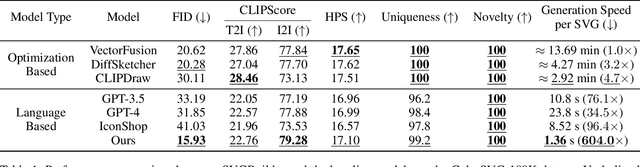
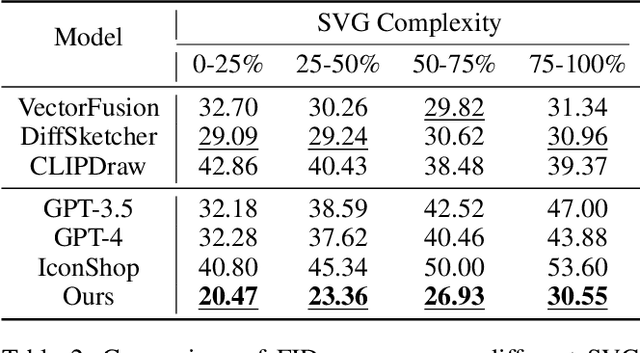
Scalable Vector Graphics (SVG) are essential XML-based formats for versatile graphics, offering resolution independence and scalability. Unlike raster images, SVGs use geometric shapes and support interactivity, animation, and manipulation via CSS and JavaScript. Current SVG generation methods face challenges related to high computational costs and complexity. In contrast, human designers use component-based tools for efficient SVG creation. Inspired by this, SVGBuilder introduces a component-based, autoregressive model for generating high-quality colored SVGs from textual input. It significantly reduces computational overhead and improves efficiency compared to traditional methods. Our model generates SVGs up to 604 times faster than optimization-based approaches. To address the limitations of existing SVG datasets and support our research, we introduce ColorSVG-100K, the first large-scale dataset of colored SVGs, comprising 100,000 graphics. This dataset fills the gap in color information for SVG generation models and enhances diversity in model training. Evaluation against state-of-the-art models demonstrates SVGBuilder's superior performance in practical applications, highlighting its efficiency and quality in generating complex SVG graphics.
Leveraging LLM for Automated Ontology Extraction and Knowledge Graph Generation
Dec 03, 2024



Extracting relevant and structured knowledge from large, complex technical documents within the Reliability and Maintainability (RAM) domain is labor-intensive and prone to errors. Our work addresses this challenge by presenting OntoKGen, a genuine pipeline for ontology extraction and Knowledge Graph (KG) generation. OntoKGen leverages Large Language Models (LLMs) through an interactive user interface guided by our adaptive iterative Chain of Thought (CoT) algorithm to ensure that the ontology extraction process and, thus, KG generation align with user-specific requirements. Although KG generation follows a clear, structured path based on the confirmed ontology, there is no universally correct ontology as it is inherently based on the user's preferences. OntoKGen recommends an ontology grounded in best practices, minimizing user effort and providing valuable insights that may have been overlooked, all while giving the user complete control over the final ontology. Having generated the KG based on the confirmed ontology, OntoKGen enables seamless integration into schemeless, non-relational databases like Neo4j. This integration allows for flexible storage and retrieval of knowledge from diverse, unstructured sources, facilitating advanced querying, analysis, and decision-making. Moreover, the generated KG serves as a robust foundation for future integration into Retrieval Augmented Generation (RAG) systems, offering enhanced capabilities for developing domain-specific intelligent applications.