 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast-Loaded Expert Parallelism: Load Balancing An Imbalanced Mixture-of-Experts
Jan 23, 2026Mixture-of-Experts (MoE) models are typically pre-trained with explicit load-balancing constraints to ensure statistically balanced expert routing. Despite this, we observe that even well-trained MoE models exhibit significantly imbalanced routing. This behavior is arguably natural-and even desirable - as imbalanced routing allows models to concentrate domain-specific knowledge within a subset of experts. Expert parallelism (EP) is designed to scale MoE models by distributing experts across multiple devices, but with a less-discussed assumption of balanced routing. Under extreme imbalance, EP can funnel a disproportionate number of tokens to a small number of experts, leading to compute- and memory-bound failures on overloaded devices during post-training or inference, where explicit load balancing is often inapplicable. We propose Least-Loaded Expert Parallelism (LLEP), a novel EP algorithm that dynamically reroutes excess tokens and associated expert parameters from overloaded devices to underutilized ones. This ensures that all devices complete their workloads within the minimum collective latency while respecting memory constraints. Across different model scales, LLEP achieves up to 5x speedup and 4x reduction in peak memory usage compared to standard EP. This enables faster and higher-throughput post-training and inference, with ~1.9x faster for gpt-oss-120b. We support our method with extensive theoretical analysis and comprehensive empirical evaluations, including ablation studies. These results illuminate key trade-offs and enable a principled framework for hardware-specific hyper-parameter tuning to achieve optimal performance.
Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection
May 23, 2025



Aligning large language models (LLMs) to accurately detect hallucinations remains a significant challenge due to the sophisticated nature of hallucinated text. Recognizing that hallucinated samples typically exhibit higher deceptive quality than traditional negative samples, we use these carefully engineered hallucinations as negative examples in the DPO alignment procedure. Our method incorporates a curriculum learning strategy, gradually transitioning the training from easier samples, identified based on the greatest reduction in probability scores from independent fact checking models, to progressively harder ones. This structured difficulty scaling ensures stable and incremental learning. Experimental evaluation demonstrates that our HaluCheck models, trained with curriculum DPO approach and high quality negative samples, significantly improves model performance across various metrics, achieving improvements of upto 24% on difficult benchmarks like MedHallu and HaluEval. Additionally, HaluCheck models demonstrate robustness in zero-shot settings, significantly outperforming larger state-of-the-art models across various benchmarks.
MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models
Feb 20, 2025



Advancements in Large Language Models (LLMs) and their increasing use in medical question-answering necessitate rigorous evaluation of their reliability. A critical challenge lies in hallucination, where models generate plausible yet factually incorrect outputs. In the medical domain, this poses serious risks to patient safety and clinical decision-making. To address this, we introduce MedHallu, the first benchmark specifically designed for medical hallucination detection. MedHallu comprises 10,000 high-quality question-answer pairs derived from PubMedQA, with hallucinated answers systematically generated through a controlled pipeline. Our experiments show that state-of-the-art LLMs, including GPT-4o, Llama-3.1, and the medically fine-tuned UltraMedical, struggle with this binary hallucination detection task, with the best model achieving an F1 score as low as 0.625 for detecting "hard" category hallucinations. Using bidirectional entailment clustering, we show that harder-to-detect hallucinations are semantically closer to ground truth. Through experiments, we also show incorporating domain-specific knowledge and introducing a "not sure" category as one of the answer categories improves the precision and F1 scores by up to 38% relative to baselines.
SFR-RAG: Towards Contextually Faithful LLMs
Sep 16, 2024Retrieval Augmented Generation (RAG), a paradigm that integrates external contextual information with large language models (LLMs) to enhance factual accuracy and relevance, has emerged as a pivotal area in generative AI. The LLMs used in RAG applications are required to faithfully and completely comprehend the provided context and users' questions, avoid hallucination, handle unanswerable, counterfactual or otherwise low-quality and irrelevant contexts, perform complex multi-hop reasoning and produce reliable citations. In this paper, we introduce SFR-RAG, a small LLM that is instruction-tuned with an emphasis on context-grounded generation and hallucination minimization. We also present ContextualBench, a new evaluation framework compiling multiple popular and diverse RAG benchmarks, such as HotpotQA and TriviaQA, with consistent RAG settings to ensure reproducibility and consistency in model assessments. Experimental results demonstrate that our SFR-RAG-9B model outperforms leading baselines such as Command-R+ (104B) and GPT-4o, achieving state-of-the-art results in 3 out of 7 benchmarks in ContextualBench with significantly fewer parameters. The model is also shown to be resilient to alteration in the contextual information and behave appropriately when relevant context is removed. Additionally, the SFR-RAG model maintains competitive performance in general instruction-following tasks and function-calling capabilities.
CodeUpdateArena: Benchmarking Knowledge Editing on API Updates
Jul 08, 2024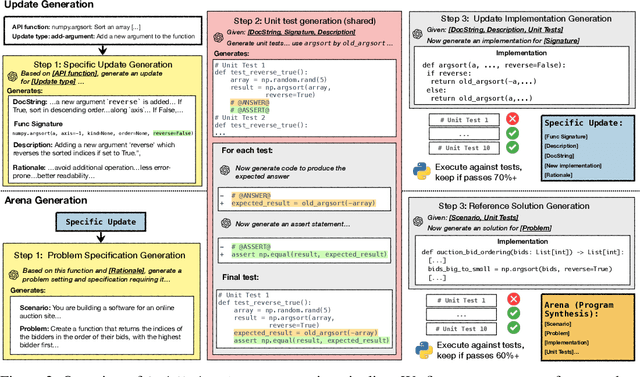



Large language models (LLMs) are increasingly being used to synthesize and reason about source code. However, the static nature of these models' knowledge does not reflect the fact that libraries and API functions they invoke are continuously evolving, with functionality being added or changing. While numerous benchmarks evaluate how LLMs can generate code, no prior work has studied how an LLMs' knowledge about code API functions can be updated. To fill this gap, we present CodeUpdateArena, a benchmark for knowledge editing in the code domain. An instance in our benchmark consists of a synthetic API function update paired with a program synthesis example that uses the updated functionality; our goal is to update an LLM to be able to solve this program synthesis example without providing documentation of the update at inference time. Compared to knowledge editing for facts encoded in text, success here is more challenging: a code LLM must correctly reason about the semantics of the modified function rather than just reproduce its syntax. Our dataset is constructed by first prompting GPT-4 to generate atomic and executable function updates. Then, for each update, we generate program synthesis examples whose code solutions are prone to use the update. Our benchmark covers updates of various types to 54 functions from seven diverse Python packages, with a total of 670 program synthesis examples. Our experiments show that prepending documentation of the update to open-source code LLMs (i.e., DeepSeek, CodeLlama) does not allow them to incorporate changes for problem solving, and existing knowledge editing techniques also have substantial room for improvement. We hope our benchmark will inspire new methods for knowledge updating in code LLMs.
An Autoencoder Based Approach to Simulate Sports Games
Jul 16, 2020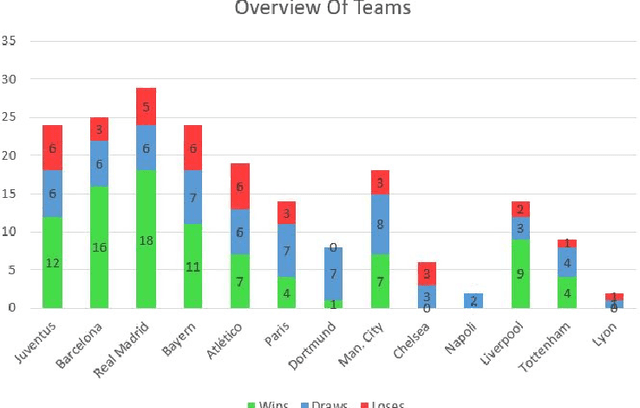

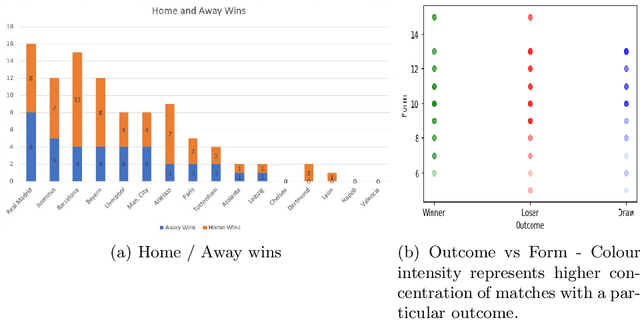
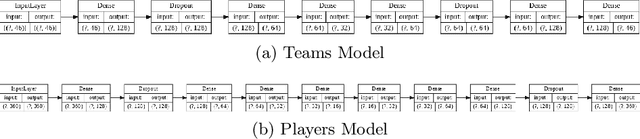
Sports data has become widely available in the recent past. With the improvement of machine learning techniques, there have been attempts to use sports data to analyze not only the outcome of individual games but also to improve insights and strategies. The outbreak of COVID-19 has interrupted sports leagues globally, giving rise to increasing questions and speculations about the outcome of this season's leagues. What if the season was not interrupted and concluded normally? Which teams would end up winning trophies? Which players would perform the best? Which team would end their season on a high and which teams would fail to keep up with the pressure? We aim to tackle this problem and develop a solution. In this paper, we proposeUCLData, which is a dataset containing detailed information of UEFA Champions League games played over the past six years. We also propose a novel autoencoder based machine learning pipeline that can come up with a story on how the rest of the season will pan out.