 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast-Loaded Expert Parallelism: Load Balancing An Imbalanced Mixture-of-Experts
Jan 23, 2026Mixture-of-Experts (MoE) models are typically pre-trained with explicit load-balancing constraints to ensure statistically balanced expert routing. Despite this, we observe that even well-trained MoE models exhibit significantly imbalanced routing. This behavior is arguably natural-and even desirable - as imbalanced routing allows models to concentrate domain-specific knowledge within a subset of experts. Expert parallelism (EP) is designed to scale MoE models by distributing experts across multiple devices, but with a less-discussed assumption of balanced routing. Under extreme imbalance, EP can funnel a disproportionate number of tokens to a small number of experts, leading to compute- and memory-bound failures on overloaded devices during post-training or inference, where explicit load balancing is often inapplicable. We propose Least-Loaded Expert Parallelism (LLEP), a novel EP algorithm that dynamically reroutes excess tokens and associated expert parameters from overloaded devices to underutilized ones. This ensures that all devices complete their workloads within the minimum collective latency while respecting memory constraints. Across different model scales, LLEP achieves up to 5x speedup and 4x reduction in peak memory usage compared to standard EP. This enables faster and higher-throughput post-training and inference, with ~1.9x faster for gpt-oss-120b. We support our method with extensive theoretical analysis and comprehensive empirical evaluations, including ablation studies. These results illuminate key trade-offs and enable a principled framework for hardware-specific hyper-parameter tuning to achieve optimal performance.
MAS-Orchestra: Understanding and Improving Multi-Agent Reasoning Through Holistic Orchestration and Controlled Benchmarks
Jan 21, 2026While multi-agent systems (MAS) promise elevated intelligence through coordination of agents, current approaches to automatic MAS design under-deliver. Such shortcomings stem from two key factors: (1) methodological complexity - agent orchestration is performed using sequential, code-level execution that limits global system-level holistic reasoning and scales poorly with agent complexity - and (2) efficacy uncertainty - MAS are deployed without understanding if there are tangible benefits compared to single-agent systems (SAS). We propose MAS-Orchestra, a training-time framework that formulates MAS orchestration as a function-calling reinforcement learning problem with holistic orchestration, generating an entire MAS at once. In MAS-Orchestra, complex, goal-oriented sub-agents are abstracted as callable functions, enabling global reasoning over system structure while hiding internal execution details. To rigorously study when and why MAS are beneficial, we introduce MASBENCH, a controlled benchmark that characterizes tasks along five axes: Depth, Horizon, Breadth, Parallel, and Robustness. Our analysis reveals that MAS gains depend critically on task structure, verification protocols, and the capabilities of both orchestrator and sub-agents, rather than holding universally. Guided by these insights, MAS-Orchestra achieves consistent improvements on public benchmarks including mathematical reasoning, multi-hop QA, and search-based QA. Together, MAS-Orchestra and MASBENCH enable better training and understanding of MAS in the pursuit of multi-agent intelligence.
MAS-ZERO: Designing Multi-Agent Systems with Zero Supervision
May 26, 2025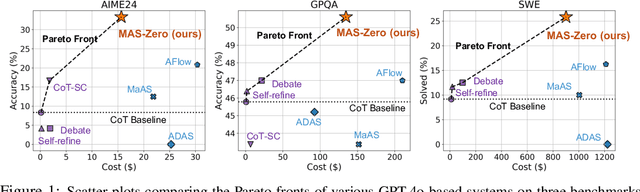

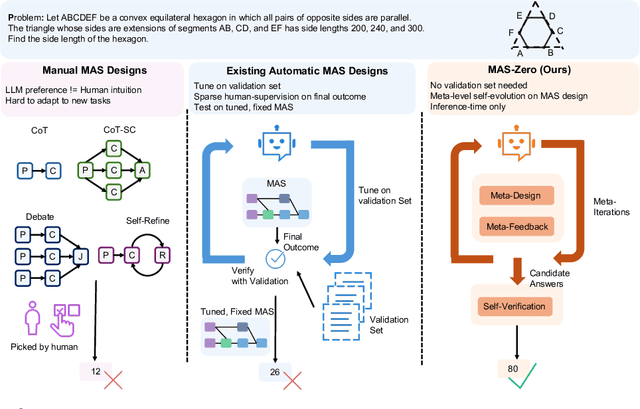

Multi-agent systems (MAS) leveraging the impressive capabilities of Large Language Models (LLMs) hold significant potential for tackling complex tasks. However, most current MAS depend on manually designed agent roles and communication protocols. These manual designs often fail to align with the underlying LLMs' strengths and struggle to adapt to novel tasks. Recent automatic MAS approaches attempt to mitigate these limitations but typically necessitate a validation set for tuning and yield static MAS designs lacking adaptability during inference. We introduce MAS-ZERO, the first self-evolved, inference-time framework for automatic MAS design. MAS-ZERO employs meta-level design to iteratively generate, evaluate, and refine MAS configurations tailored to each problem instance, without requiring a validation set. Critically, it enables dynamic agent composition and problem decomposition through meta-feedback on solvability and completeness. Experiments across math, graduate-level QA, and software engineering benchmarks, using both closed-source and open-source LLM backbones of varying sizes, demonstrate that MAS-ZERO outperforms both manual and automatic MAS baselines, achieving a 7.44% average accuracy improvement over the next strongest baseline while maintaining cost-efficiency. These findings underscore the promise of meta-level self-evolved design for creating effective and adaptive MAS.
Meta-Design Matters: A Self-Design Multi-Agent System
May 21, 2025Multi-agent systems (MAS) leveraging the impressive capabilities of Large Language Models (LLMs) hold significant potential for tackling complex tasks. However, most current MAS depend on manually designed agent roles and communication protocols. These manual designs often fail to align with the underlying LLMs' strengths and struggle to adapt to novel tasks. Recent automatic MAS approaches attempt to mitigate these limitations but typically necessitate a validation-set for tuning and yield static MAS designs lacking adaptability during inference. We introduce SELF-MAS, the first self-supervised, inference-time only framework for automatic MAS design. SELF-MAS employs meta-level design to iteratively generate, evaluate, and refine MAS configurations tailored to each problem instance, without requiring a validation set. Critically, it enables dynamic agent composition and problem decomposition through meta-feedback on solvability and completeness. Experiments across math, graduate-level QA, and software engineering benchmarks, using both closed-source and open-source LLM back-bones of varying sizes, demonstrate that SELF-MAS outperforms both manual and automatic MAS baselines, achieving a 7.44% average accuracy improvement over the next strongest baseline while maintaining cost-efficiency. These findings underscore the promise of meta-level self-supervised design for creating effective and adaptive MAS.
J4R: Learning to Judge with Equivalent Initial State Group Relative Preference Optimization
May 19, 2025To keep pace with the increasing pace of large language models (LLM) development, model output evaluation has transitioned away from time-consuming human evaluation to automatic evaluation, where LLMs themselves are tasked with assessing and critiquing other model outputs. LLM-as-judge models are a class of generative evaluators that excel in evaluating relatively simple domains, like chat quality, but struggle in reasoning intensive domains where model responses contain more substantive and challenging content. To remedy existing judge shortcomings, we explore training judges with reinforcement learning (RL). We make three key contributions: (1) We propose the Equivalent Initial State Group Relative Policy Optimization (EIS-GRPO) algorithm, which allows us to train our judge to be robust to positional biases that arise in more complex evaluation settings. (2) We introduce ReasoningJudgeBench, a benchmark that evaluates judges in diverse reasoning settings not covered by prior work. (3) We train Judge for Reasoning (J4R), a 7B judge trained with EIS-GRPO that outperforms GPT-4o and the next best small judge by 6.7% and 9%, matching or exceeding the performance of larger GRPO-trained judges on both JudgeBench and ReasoningJudgeBench.
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Apr 12, 2025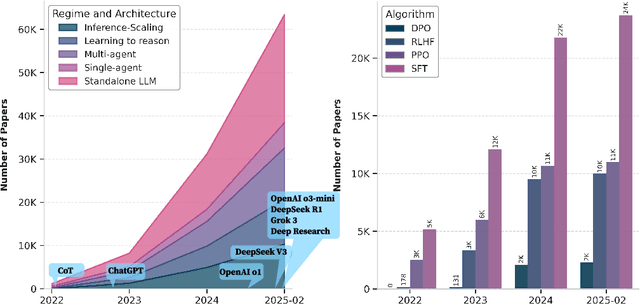

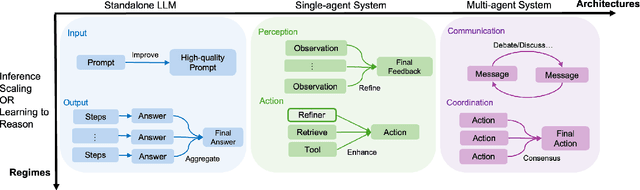

Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multi-agent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. ...
Demystifying Domain-adaptive Post-training for Financial LLMs
Jan 09, 2025



Domain-adaptive post-training of large language models (LLMs) has emerged as a promising approach for specialized domains such as medicine and finance. However, significant challenges remain in identifying optimal adaptation criteria and training strategies across varying data and model configurations. To address these challenges, we introduce FINDAP, a systematic and fine-grained investigation into domain-adaptive post-training of LLMs for the finance domain. Our approach begins by identifying the core capabilities required for the target domain and designing a comprehensive evaluation suite aligned with these needs. We then analyze the effectiveness of key post-training stages, including continual pretraining, instruction tuning, and preference alignment. Building on these insights, we propose an effective training recipe centered on a novel preference data distillation method, which leverages process signals from a generative reward model. The resulting model, Llama-Fin, achieves state-of-the-art performance across a wide range of financial tasks. Our analysis also highlights how each post-training stage contributes to distinct capabilities, uncovering specific challenges and effective solutions, providing valuable insights for domain adaptation of LLMs. Project page: https://github.com/SalesforceAIResearch/FinDap
Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction
Sep 25, 2024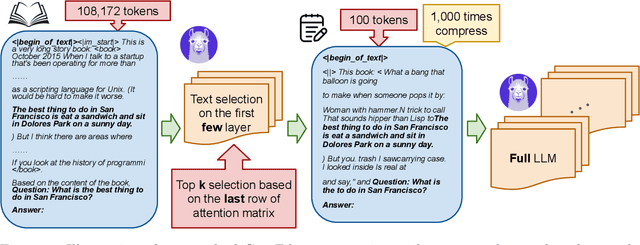
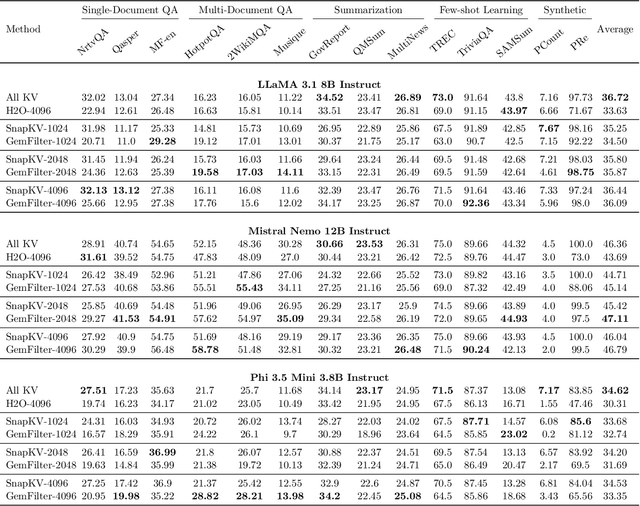
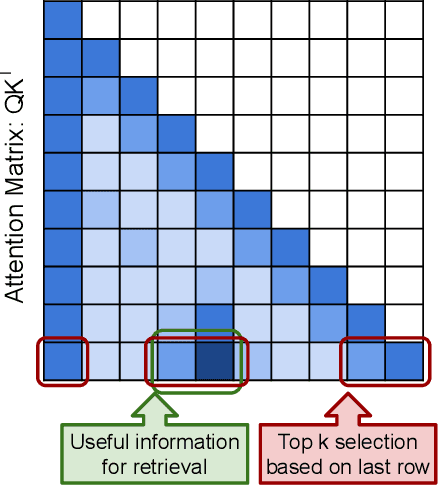
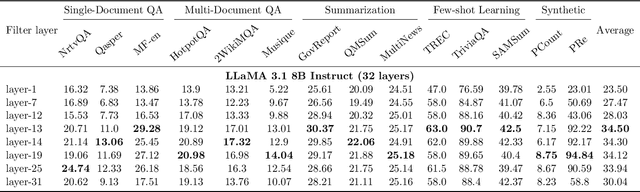
Large Language Models (LLMs) have demonstrated remarkable capabilities in handling long context inputs, but this comes at the cost of increased computational resources and latency. Our research introduces a novel approach for the long context bottleneck to accelerate LLM inference and reduce GPU memory consumption. Our research demonstrates that LLMs can identify relevant tokens in the early layers before generating answers to a query. Leveraging this insight, we propose an algorithm that uses early layers of an LLM as filters to select and compress input tokens, significantly reducing the context length for subsequent processing. Our method, GemFilter, demonstrates substantial improvements in both speed and memory efficiency compared to existing techniques, such as standard attention and SnapKV/H2O. Notably, it achieves a 2.4$\times$ speedup and 30\% reduction in GPU memory usage compared to SOTA methods. Evaluation on the Needle in a Haystack task shows that GemFilter significantly outperforms standard attention, SnapKV and demonstrates comparable performance on the LongBench challenge. GemFilter is simple, training-free, and broadly applicable across different LLMs. Crucially, it provides interpretability by allowing humans to inspect the selected input sequence. These findings not only offer practical benefits for LLM deployment, but also enhance our understanding of LLM internal mechanisms, paving the way for further optimizations in LLM design and inference. Our code is available at \url{https://github.com/SalesforceAIResearch/GemFilter}.
SFR-RAG: Towards Contextually Faithful LLMs
Sep 16, 2024Retrieval Augmented Generation (RAG), a paradigm that integrates external contextual information with large language models (LLMs) to enhance factual accuracy and relevance, has emerged as a pivotal area in generative AI. The LLMs used in RAG applications are required to faithfully and completely comprehend the provided context and users' questions, avoid hallucination, handle unanswerable, counterfactual or otherwise low-quality and irrelevant contexts, perform complex multi-hop reasoning and produce reliable citations. In this paper, we introduce SFR-RAG, a small LLM that is instruction-tuned with an emphasis on context-grounded generation and hallucination minimization. We also present ContextualBench, a new evaluation framework compiling multiple popular and diverse RAG benchmarks, such as HotpotQA and TriviaQA, with consistent RAG settings to ensure reproducibility and consistency in model assessments. Experimental results demonstrate that our SFR-RAG-9B model outperforms leading baselines such as Command-R+ (104B) and GPT-4o, achieving state-of-the-art results in 3 out of 7 benchmarks in ContextualBench with significantly fewer parameters. The model is also shown to be resilient to alteration in the contextual information and behave appropriately when relevant context is removed. Additionally, the SFR-RAG model maintains competitive performance in general instruction-following tasks and function-calling capabilities.
ParaICL: Towards Robust Parallel In-Context Learning
Mar 31, 2024Large language models (LLMs) have become the norm in natural language processing (NLP), excelling in few-shot in-context learning (ICL) with their remarkable abilities. Nonetheless, the success of ICL largely hinges on the choice of few-shot demonstration examples, making the selection process increasingly crucial. Existing methods have delved into optimizing the quantity and semantic similarity of these examples to improve ICL performances. However, our preliminary experiments indicate that the effectiveness of ICL is limited by the length of the input context. Moreover, varying combinations of few-shot demonstration examples can significantly boost accuracy across different test samples. To address this, we propose a novel method named parallel in-context learning (ParaICL) that effectively utilizes all demonstration examples without exceeding the manageable input context length. ParaICL employs parallel batching to distribute demonstration examples into different batches according to the semantic similarities of the questions in the demonstrations to the test question. It then computes normalized batch semantic scores for each batch. A weighted average semantic objective, constrained by adaptive plausibility, is applied to select the most appropriate tokens. Through extensive experiments, we validate the effectiveness of ParaICL and conduct ablation studies to underscore its design rationale. We further demonstrate that ParaICL can seamlessly integrate with existing methods.