 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferences Improve LLM Alignment in Non-Verifiable Domains
Feb 18, 2026While Reinforcement Learning with Verifiable Rewards (RLVR) has shown strong effectiveness in reasoning tasks, it cannot be directly applied to non-verifiable domains lacking ground-truth verifiers, such as LLM alignment. In this work, we investigate whether reference-guided LLM-evaluators can bridge this gap by serving as soft "verifiers". First, we design evaluation protocols that enhance LLM-based evaluators for LLM alignment using reference outputs. Through comprehensive experiments, we show that a reference-guided approach substantially improves the accuracy of less capable LLM-judges using references from frontier models; stronger LLM-judges can also be enhanced by high-quality (i.e., human-written) references. Building on these improved judges, we demonstrate the utility of high-quality references in alignment tuning, where LLMs guided with references are used as judges to self-improve. We show that reference-guided self-improvement yields clear gains over both direct SFT on reference outputs and self-improvement with reference-free judges, achieving performance comparable to training with ArmoRM, a strong finetuned reward model. Specifically, our method achieves 73.1% and 58.7% on AlpacaEval and Arena-Hard with Llama-3-8B-Instruct, and 70.0% and 74.1% with Qwen2.5-7B, corresponding to average absolute gains of +20.2 / +17.1 points over SFT distillation and +5.3 / +3.6 points over reference-free self-improvement on AlpacaEval / Arena-Hard. These results highlight the potential of using reference-guided LLM-evaluators to enable effective LLM post-training in non-verifiable domains.
Evaluating Judges as Evaluators: The JETTS Benchmark of LLM-as-Judges as Test-Time Scaling Evaluators
Apr 21, 2025Scaling test-time computation, or affording a generator large language model (LLM) extra compute during inference, typically employs the help of external non-generative evaluators (i.e., reward models). Concurrently, LLM-judges, models trained to generate evaluations and critiques (explanations) in natural language, are becoming increasingly popular in automatic evaluation. Despite judge empirical successes, their effectiveness as evaluators in test-time scaling settings is largely unknown. In this paper, we introduce the Judge Evaluation for Test-Time Scaling (JETTS) benchmark, which evaluates judge performance in three domains (math reasoning, code generation, and instruction following) under three task settings: response reranking, step-level beam search, and critique-based response refinement. We evaluate 10 different judge models (7B-70B parameters) for 8 different base generator models (6.7B-72B parameters). Our benchmark shows that while judges are competitive with outcome reward models in reranking, they are consistently worse than process reward models in beam search procedures. Furthermore, though unique to LLM-judges, their natural language critiques are currently ineffective in guiding the generator towards better responses.
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Apr 12, 2025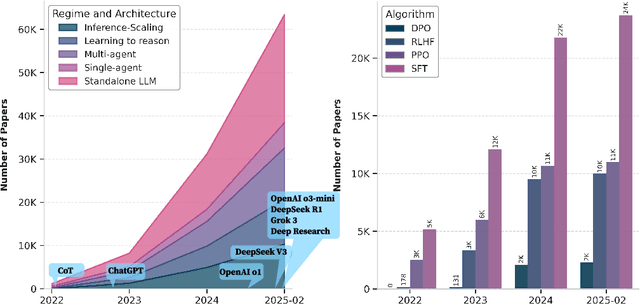

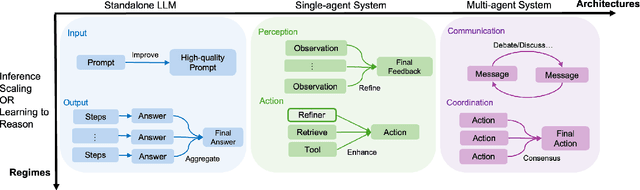

Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multi-agent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. ...
ReIFE: Re-evaluating Instruction-Following Evaluation
Oct 09, 2024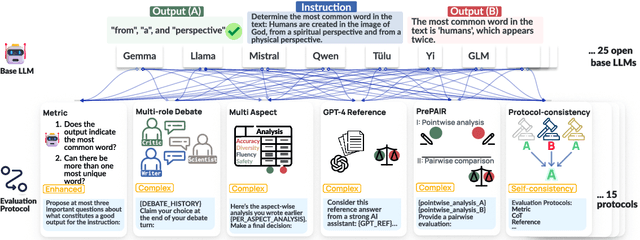
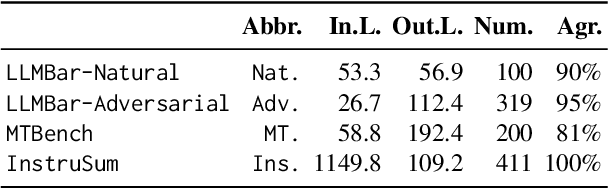
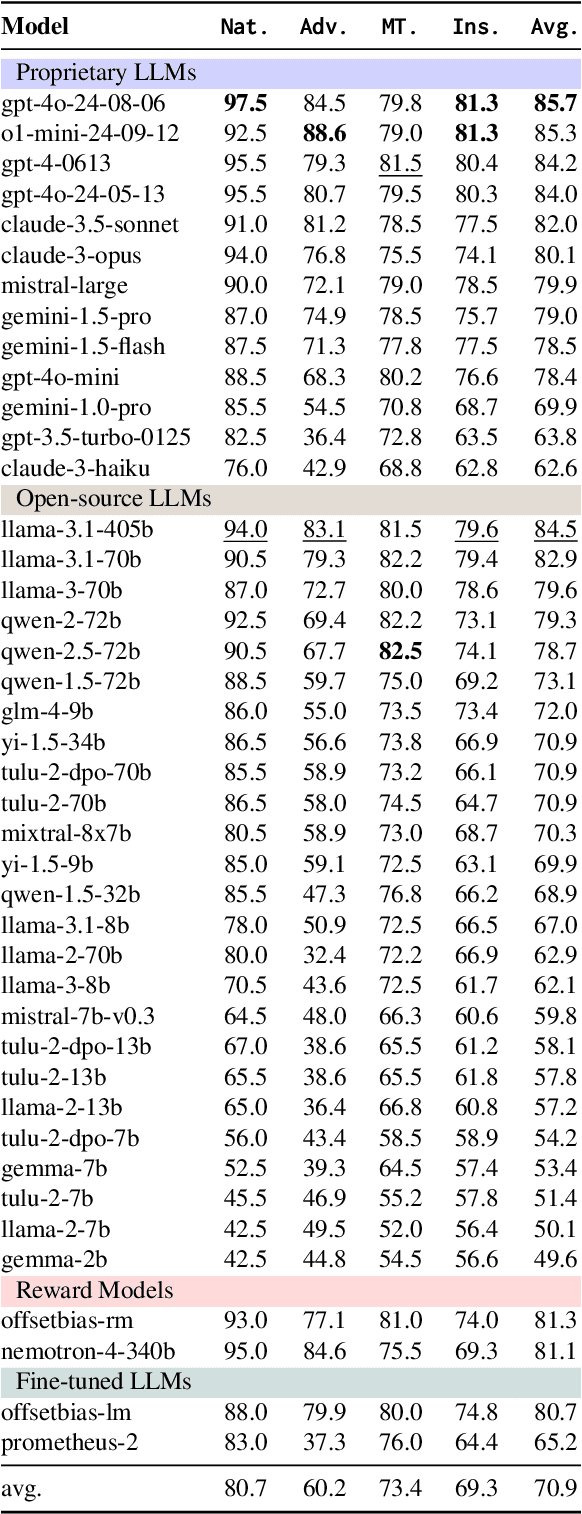
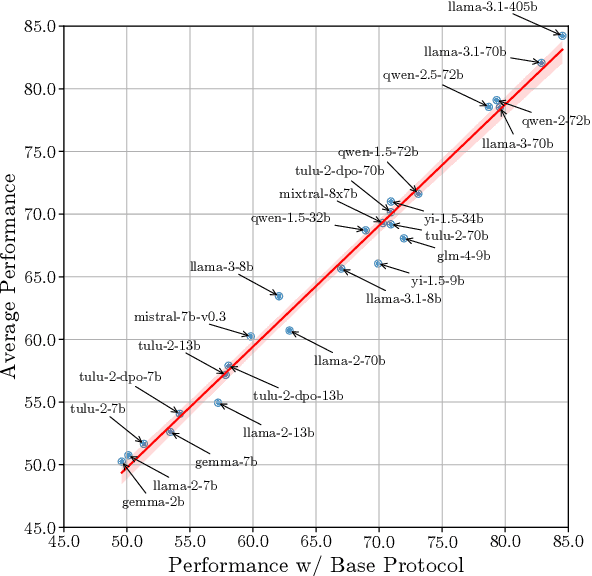
The automatic evaluation of instruction following typically involves using large language models (LLMs) to assess response quality. However, there is a lack of comprehensive evaluation of these LLM-based evaluators across two dimensions: the base LLMs and the evaluation protocols. Therefore, we present a thorough meta-evaluation of instruction following, including 25 base LLMs and 15 recently proposed evaluation protocols, on 4 human-annotated datasets, assessing the evaluation accuracy of the LLM-evaluators. Our evaluation allows us to identify the best-performing base LLMs and evaluation protocols with a high degree of robustness. Moreover, our large-scale evaluation reveals: (1) Base LLM performance ranking remains largely consistent across evaluation protocols, with less capable LLMs showing greater improvement from protocol enhancements; (2) Robust evaluation of evaluation protocols requires many base LLMs with varying capability levels, as protocol effectiveness can depend on the base LLM used; (3) Evaluation results on different datasets are not always consistent, so a rigorous evaluation requires multiple datasets with distinctive features. We release our meta-evaluation suite ReIFE, which provides the codebase and evaluation result collection for more than 500 LLM-evaluator configurations, to support future research in instruction-following evaluation.
Direct Judgement Preference Optimization
Sep 23, 2024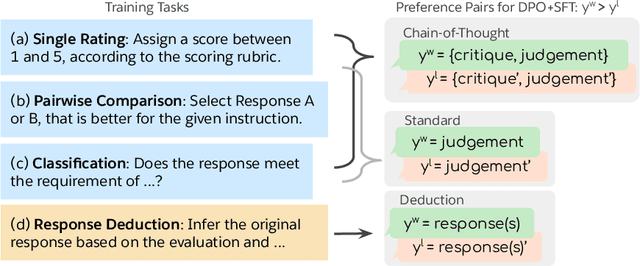

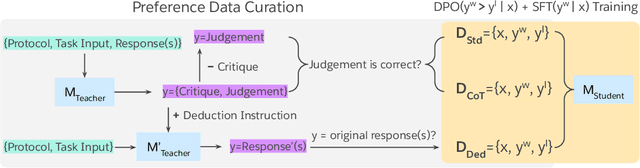

Auto-evaluation is crucial for assessing response quality and offering feedback for model development. Recent studies have explored training large language models (LLMs) as generative judges to evaluate and critique other models' outputs. In this work, we investigate the idea of learning from both positive and negative data with preference optimization to enhance the evaluation capabilities of LLM judges across an array of different use cases. We achieve this by employing three approaches to collect the preference pairs for different use cases, each aimed at improving our generative judge from a different perspective. Our comprehensive study over a wide range of benchmarks demonstrates the effectiveness of our method. In particular, our generative judge achieves the best performance on 10 out of 13 benchmarks, outperforming strong baselines like GPT-4o and specialized judge models. Further analysis show that our judge model robustly counters inherent biases such as position and length bias, flexibly adapts to any evaluation protocol specified by practitioners, and provides helpful language feedback for improving downstream generator models.
SCOTT: Self-Consistent Chain-of-Thought Distillation
May 03, 2023
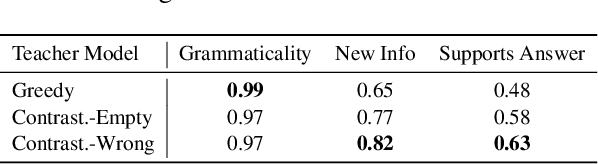
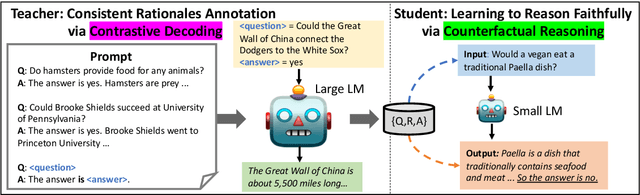

Large language models (LMs) beyond a certain scale, demonstrate the emergent capability of generating free-text rationales for their predictions via chain-of-thought (CoT) prompting. While CoT can yield dramatically improved performance, such gains are only observed for sufficiently large LMs. Even more concerning, there is little guarantee that the generated rationales are consistent with LM's predictions or faithfully justify the decisions. In this work, we propose a faithful knowledge distillation method to learn a small, self-consistent CoT model from a teacher model that is orders of magnitude larger. To form better supervision, we elicit rationales supporting the gold answers from a large LM (teacher) by contrastive decoding, which encourages the teacher to generate tokens that become more plausible only when the answer is considered. To ensure faithful distillation, we use the teacher-generated rationales to learn a student LM with a counterfactual reasoning objective, which prevents the student from ignoring the rationales to make inconsistent predictions. Experiments show that, while yielding comparable end-task performance, our method can generate CoT rationales that are more faithful than baselines do. Further analysis suggests that such a model respects the rationales more when making decisions; thus, we can improve its performance more by refining its rationales.
PINTO: Faithful Language Reasoning Using Prompt-Generated Rationales
Nov 03, 2022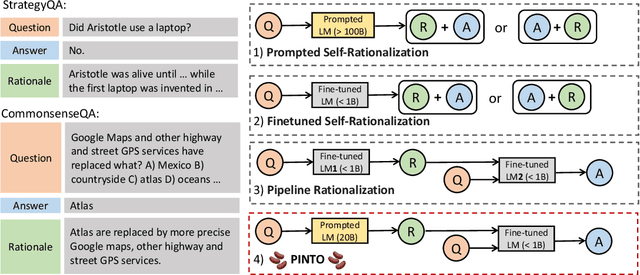

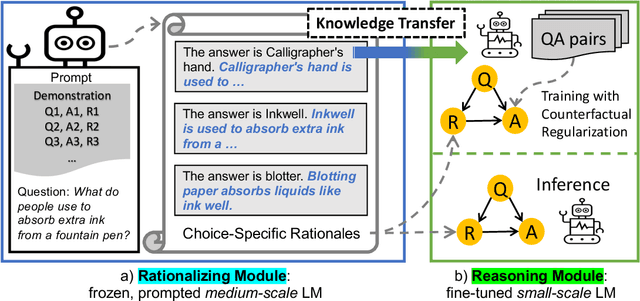
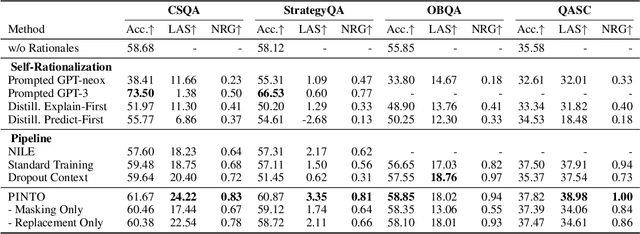
Neural language models (LMs) have achieved impressive results on various language-based reasoning tasks by utilizing latent knowledge encoded in their own pretrained parameters. To make this reasoning process more explicit, recent works retrieve a rationalizing LM's internal knowledge by training or prompting it to generate free-text rationales, which can be used to guide task predictions made by either the same LM or a separate reasoning LM. However, rationalizing LMs require expensive rationale annotation and/or computation, without any assurance that their generated rationales improve LM task performance or faithfully reflect LM decision-making. In this paper, we propose PINTO, an LM pipeline that rationalizes via prompt-based learning, and learns to faithfully reason over rationales via counterfactual regularization. First, PINTO maps out a suitable reasoning process for the task input by prompting a frozen rationalizing LM to generate a free-text rationale. Second, PINTO's reasoning LM is fine-tuned to solve the task using the generated rationale as context, while regularized to output less confident predictions when the rationale is perturbed. Across four datasets, we show that PINTO significantly improves the generalization ability of the reasoning LM, yielding higher performance on both in-distribution and out-of-distribution test sets. Also, we find that PINTO's rationales are more faithful to its task predictions than those generated by competitive baselines.
Do Language Models Perform Generalizable Commonsense Inference?
Jun 22, 2021
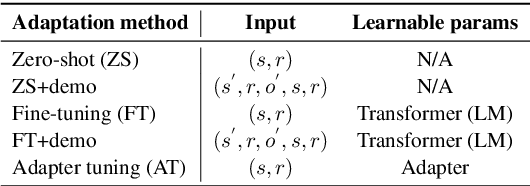
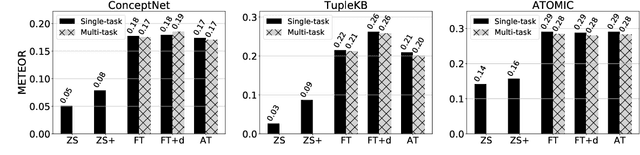
Inspired by evidence that pretrained language models (LMs) encode commonsense knowledge, recent work has applied LMs to automatically populate commonsense knowledge graphs (CKGs). However, there is a lack of understanding on their generalization to multiple CKGs, unseen relations, and novel entities. This paper analyzes the ability of LMs to perform generalizable commonsense inference, in terms of knowledge capacity, transferability, and induction. Our experiments with these three aspects show that: (1) LMs can adapt to different schemas defined by multiple CKGs but fail to reuse the knowledge to generalize to new relations. (2) Adapted LMs generalize well to unseen subjects, but less so on novel objects. Future work should investigate how to improve the transferability and induction of commonsense mining from LMs.
Learning to Deceive Knowledge Graph Augmented Models via Targeted Perturbation
Oct 24, 2020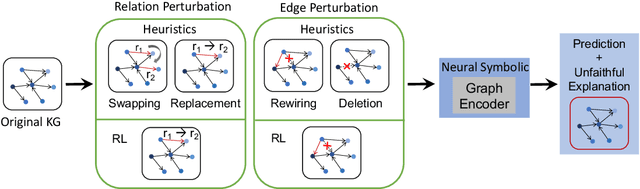
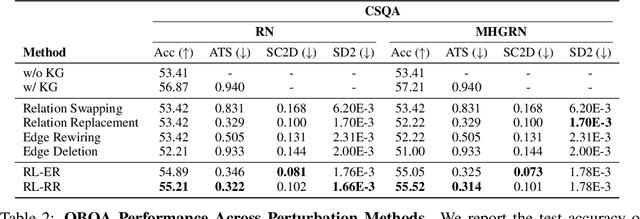
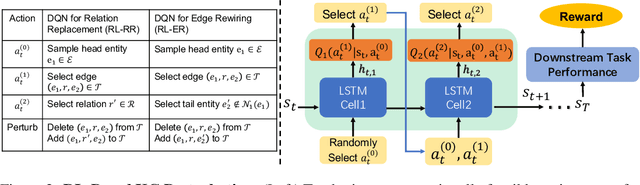
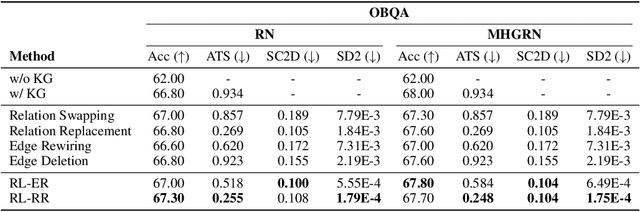
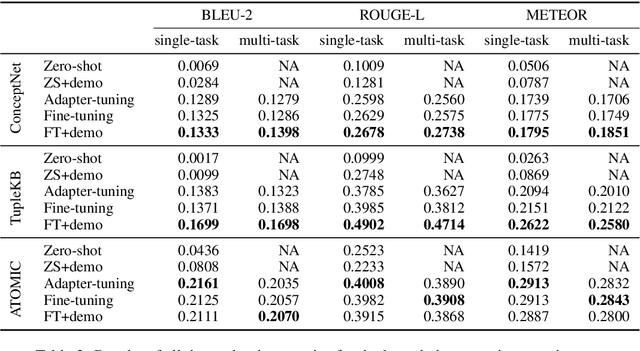
Symbolic knowledge (e.g., entities, relations, and facts in a knowledge graph) has become an increasingly popular component of neural-symbolic models applied to machine learning tasks, such as question answering and recommender systems. Besides improving downstream performance, these symbolic structures (and their associated attention weights) are often used to help explain the model's predictions and provide "insights" to practitioners. In this paper, we question the faithfulness of such symbolic explanations. We demonstrate that, through a learned strategy (or even simple heuristics), one can produce deceptively perturbed symbolic structures which maintain the downstream performance of the original structure while significantly deviating from the original semantics. In particular, we train a reinforcement learning policy to manipulate relation types or edge connections in a knowledge graph, such that the resulting downstream performance is maximally preserved. Across multiple models and tasks, our approach drastically alters knowledge graphs with little to no drop in performance. These results raise doubts about the faithfulness of explanations provided by learned symbolic structures and the reliability of current neural-symbolic models in leveraging symbolic knowledge.
When Hearst Is not Enough: Improving Hypernymy Detection from Corpus with Distributional Models
Oct 10, 2020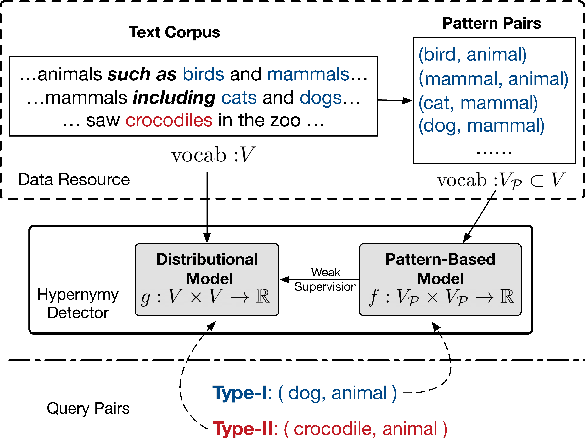
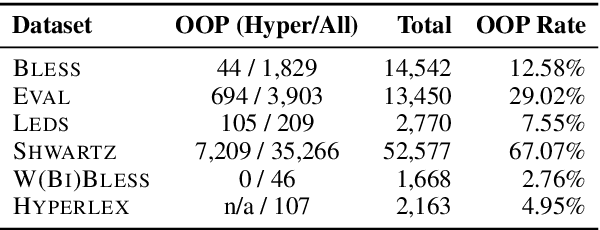
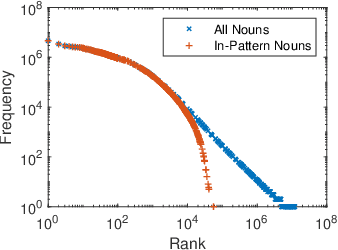
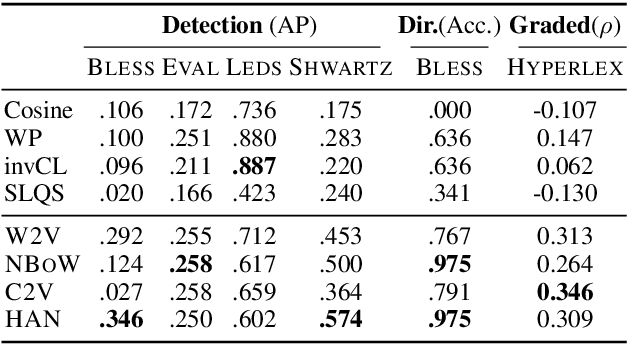
We address hypernymy detection, i.e., whether an is-a relationship exists between words (x, y), with the help of large textual corpora. Most conventional approaches to this task have been categorized to be either pattern-based or distributional. Recent studies suggest that pattern-based ones are superior, if large-scale Hearst pairs are extracted and fed, with the sparsity of unseen (x, y) pairs relieved. However, they become invalid in some specific sparsity cases, where x or y is not involved in any pattern. For the first time, this paper quantifies the non-negligible existence of those specific cases. We also demonstrate that distributional methods are ideal to make up for pattern-based ones in such cases. We devise a complementary framework, under which a pattern-based and a distributional model collaborate seamlessly in cases which they each prefer. On several benchmark datasets, our framework achieves competitive improvements and the case study shows its better interpretability.