 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Deceive Knowledge Graph Augmented Models via Targeted Perturbation
Paper and Code
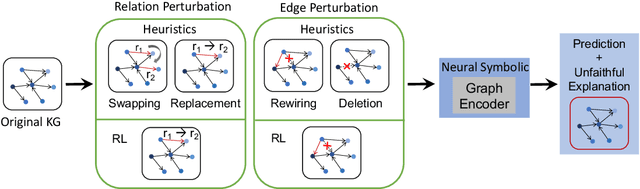
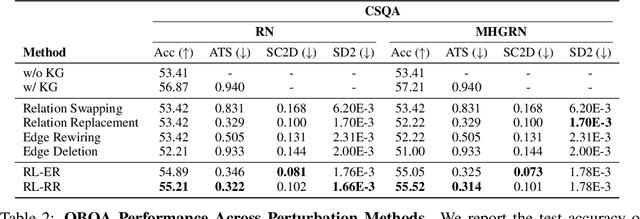
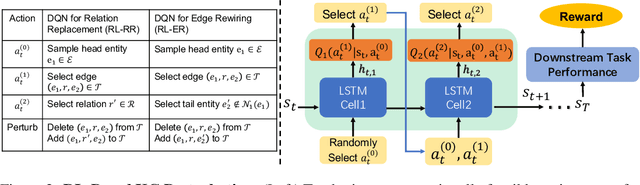
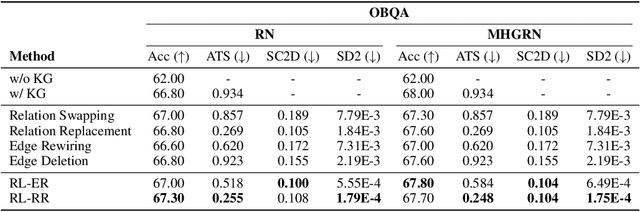
Symbolic knowledge (e.g., entities, relations, and facts in a knowledge graph) has become an increasingly popular component of neural-symbolic models applied to machine learning tasks, such as question answering and recommender systems. Besides improving downstream performance, these symbolic structures (and their associated attention weights) are often used to help explain the model's predictions and provide "insights" to practitioners. In this paper, we question the faithfulness of such symbolic explanations. We demonstrate that, through a learned strategy (or even simple heuristics), one can produce deceptively perturbed symbolic structures which maintain the downstream performance of the original structure while significantly deviating from the original semantics. In particular, we train a reinforcement learning policy to manipulate relation types or edge connections in a knowledge graph, such that the resulting downstream performance is maximally preserved. Across multiple models and tasks, our approach drastically alters knowledge graphs with little to no drop in performance. These results raise doubts about the faithfulness of explanations provided by learned symbolic structures and the reliability of current neural-symbolic models in leveraging symbolic knowledge.