 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Hoc Reversal: Are We Selecting Models Prematurely?
Apr 11, 2024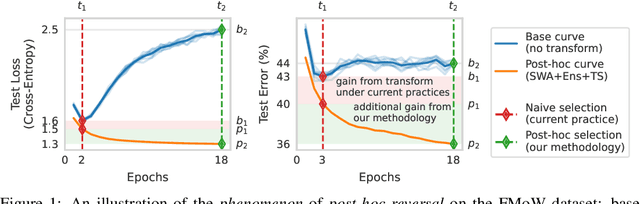
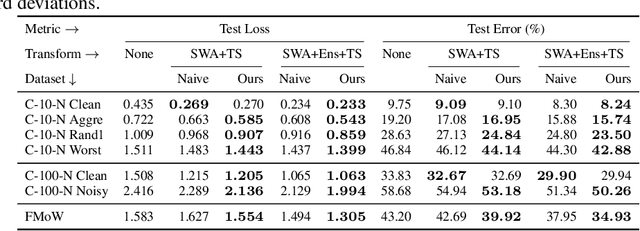
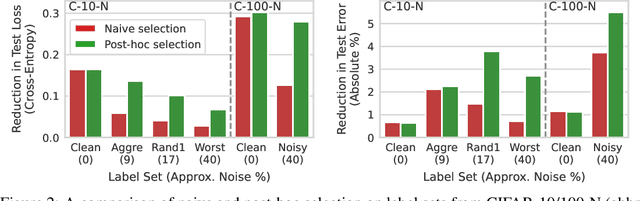

Trained models are often composed with post-hoc transforms such as temperature scaling (TS), ensembling and stochastic weight averaging (SWA) to improve performance, robustness, uncertainty estimation, etc. However, such transforms are typically applied only after the base models have already been finalized by standard means. In this paper, we challenge this practice with an extensive empirical study. In particular, we demonstrate a phenomenon that we call post-hoc reversal, where performance trends are reversed after applying these post-hoc transforms. This phenomenon is especially prominent in high-noise settings. For example, while base models overfit badly early in training, both conventional ensembling and SWA favor base models trained for more epochs. Post-hoc reversal can also suppress the appearance of double descent and mitigate mismatches between test loss and test error seen in base models. Based on our findings, we propose post-hoc selection, a simple technique whereby post-hoc metrics inform model development decisions such as early stopping, checkpointing, and broader hyperparameter choices. Our experimental analyses span real-world vision, language, tabular and graph datasets from domains like satellite imaging, language modeling, census prediction and social network analysis. On an LLM instruction tuning dataset, post-hoc selection results in > 1.5x MMLU improvement compared to naive selection. Code is available at https://github.com/rishabh-ranjan/post-hoc-reversal.
Turn Down the Noise: Leveraging Diffusion Models for Test-time Adaptation via Pseudo-label Ensembling
Nov 29, 2023



The goal of test-time adaptation is to adapt a source-pretrained model to a continuously changing target domain without relying on any source data. Typically, this is either done by updating the parameters of the model (model adaptation) using inputs from the target domain or by modifying the inputs themselves (input adaptation). However, methods that modify the model suffer from the issue of compounding noisy updates whereas methods that modify the input need to adapt to every new data point from scratch while also struggling with certain domain shifts. We introduce an approach that leverages a pre-trained diffusion model to project the target domain images closer to the source domain and iteratively updates the model via pseudo-label ensembling. Our method combines the advantages of model and input adaptations while mitigating their shortcomings. Our experiments on CIFAR-10C demonstrate the superiority of our approach, outperforming the strongest baseline by an average of 1.7% across 15 diverse corruptions and surpassing the strongest input adaptation baseline by an average of 18%.
Bridging the Gap: Exploring the Capabilities of Bridge-Architectures for Complex Visual Reasoning Tasks
Jul 31, 2023In recent times there has been a surge of multi-modal architectures based on Large Language Models, which leverage the zero shot generation capabilities of LLMs and project image embeddings into the text space and then use the auto-regressive capacity to solve tasks such as VQA, captioning, and image retrieval. We name these architectures as "bridge-architectures" as they project from the image space to the text space. These models deviate from the traditional recipe of training transformer based multi-modal models, which involve using large-scale pre-training and complex multi-modal interactions through co or cross attention. However, the capabilities of bridge architectures have not been tested on complex visual reasoning tasks which require fine grained analysis about the image. In this project, we investigate the performance of these bridge-architectures on the NLVR2 dataset, and compare it to state-of-the-art transformer based architectures. We first extend the traditional bridge architectures for the NLVR2 dataset, by adding object level features to faciliate fine-grained object reasoning. Our analysis shows that adding object level features to bridge architectures does not help, and that pre-training on multi-modal data is key for good performance on complex reasoning tasks such as NLVR2. We also demonstrate some initial results on a recently bridge-architecture, LLaVA, in the zero shot setting and analyze its performance.
Model-tuning Via Prompts Makes NLP Models Adversarially Robust
Mar 13, 2023In recent years, NLP practitioners have converged on the following practice: (i) import an off-the-shelf pretrained (masked) language model; (ii) append a multilayer perceptron atop the CLS token's hidden representation (with randomly initialized weights); and (iii) fine-tune the entire model on a downstream task (MLP). This procedure has produced massive gains on standard NLP benchmarks, but these models remain brittle, even to mild adversarial perturbations, such as word-level synonym substitutions. In this work, we demonstrate surprising gains in adversarial robustness enjoyed by Model-tuning Via Prompts (MVP), an alternative method of adapting to downstream tasks. Rather than modifying the model (by appending an MLP head), MVP instead modifies the input (by appending a prompt template). Across three classification datasets, MVP improves performance against adversarial word-level synonym substitutions by an average of 8% over standard methods and even outperforms adversarial training-based state-of-art defenses by 3.5%. By combining MVP with adversarial training, we achieve further improvements in robust accuracy while maintaining clean accuracy. Finally, we conduct ablations to investigate the mechanism underlying these gains. Notably, we find that the main causes of vulnerability of MLP can be attributed to the misalignment between pre-training and fine-tuning tasks, and the randomly initialized MLP parameters. Code is available at https://github.com/acmi-lab/mvp
Domain Generalization via Inference-time Label-Preserving Target Projections
Mar 01, 2021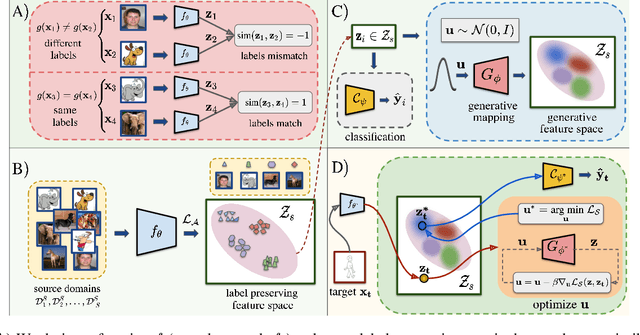
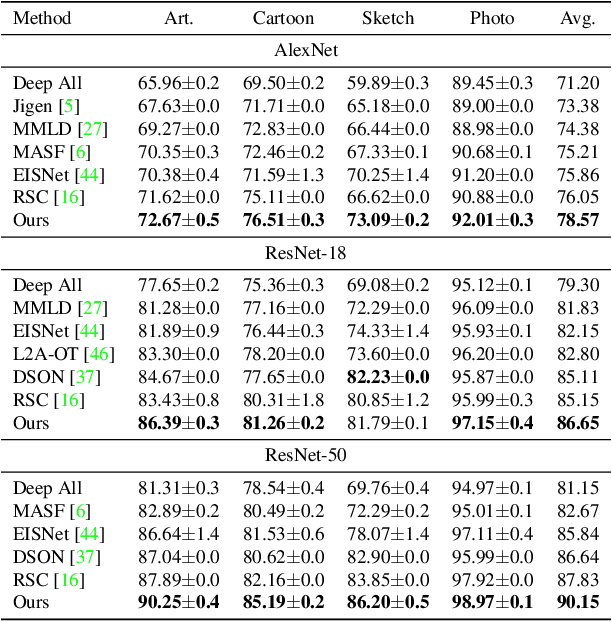
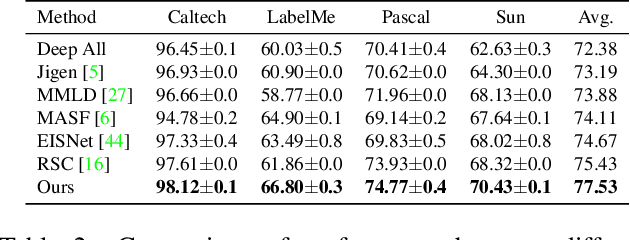
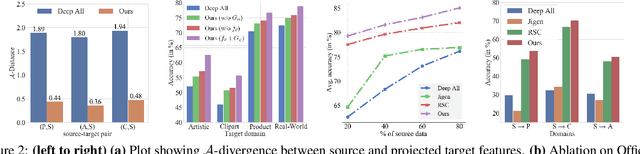
Generalization of machine learning models trained on a set of source domains on unseen target domains with different statistics, is a challenging problem. While many approaches have been proposed to solve this problem, they only utilize source data during training but do not take advantage of the fact that a single target example is available at the time of inference. Motivated by this, we propose a method that effectively uses the target sample during inference beyond mere classification. Our method has three components - (i) A label-preserving feature or metric transformation on source data such that the source samples are clustered in accordance with their class irrespective of their domain (ii) A generative model trained on the these features (iii) A label-preserving projection of the target point on the source-feature manifold during inference via solving an optimization problem on the input space of the generative model using the learned metric. Finally, the projected target is used in the classifier. Since the projected target feature comes from the source manifold and has the same label as the real target by design, the classifier is expected to perform better on it than the true target. We demonstrate that our method outperforms the state-of-the-art Domain Generalization methods on multiple datasets and tasks.
Centralized active tracking of a Markov chain with unknown dynamics
Oct 30, 2020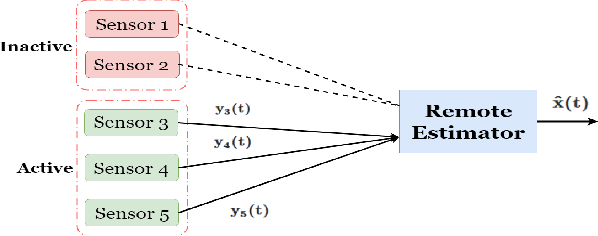
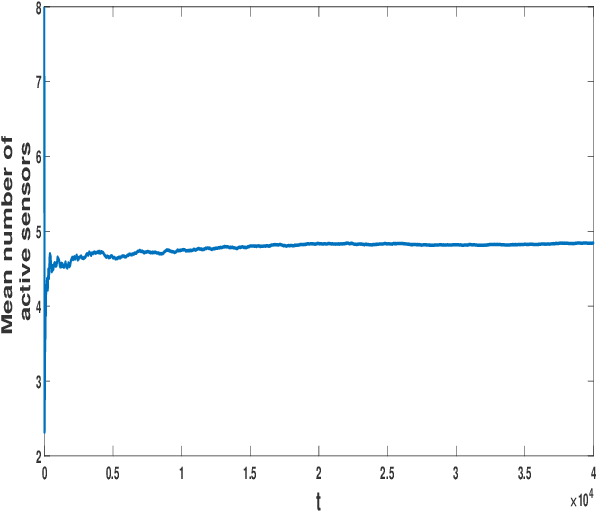
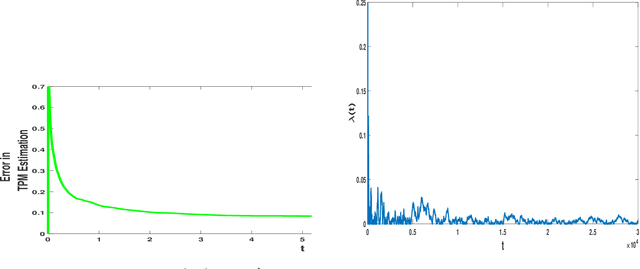
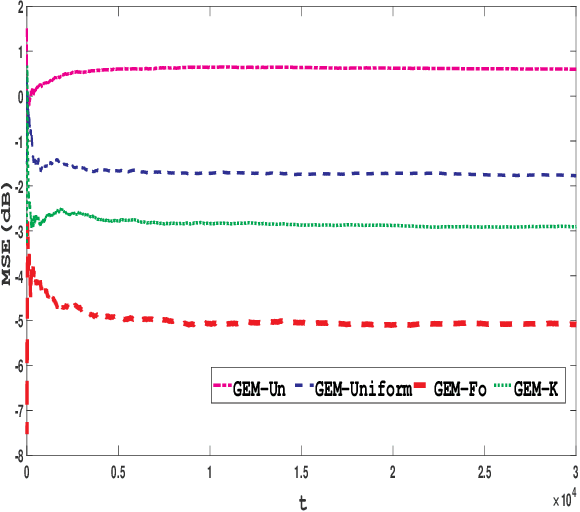
In this paper, selection of an active sensor subset for tracking a discrete time, finite state Markov chain having an unknown transition probability matrix (TPM) is considered. A total of N sensors are available for making observations of the Markov chain, out of which a subset of sensors are activated each time in order to perform reliable estimation of the process. The trade-off is between activating more sensors to gather more observations for the remote estimation, and restricting sensor usage in order to save energy and bandwidth consumption. The problem is formulated as a constrained minimization problem, where the objective is the long-run averaged mean-squared error (MSE) in estimation, and the constraint is on sensor activation rate. A Lagrangian relaxation of the problem is solved by an artful blending of two tools: Gibbs sampling for MSE minimization and an on-line version of expectation maximization (EM) to estimate the unknown TPM. Finally, the Lagrange multiplier is updated using slower timescale stochastic approximation in order to satisfy the sensor activation rate constraint. The on-line EM algorithm, though adapted from literature, can estimate vector-valued parameters even under time-varying dimension of the sensor observations. Numerical results demonstrate approximately 1 dB better error performance than uniform sensor sampling and comparable error performance (within 2 dB bound) against complete sensor observation. This makes the proposed algorithm amenable to practical implementation.
Learning Contextualized Knowledge Structures for Commonsense Reasoning
Oct 24, 2020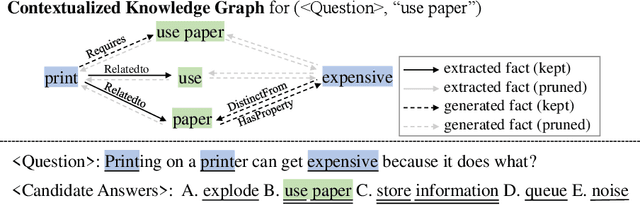
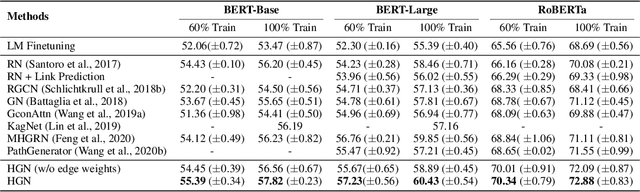
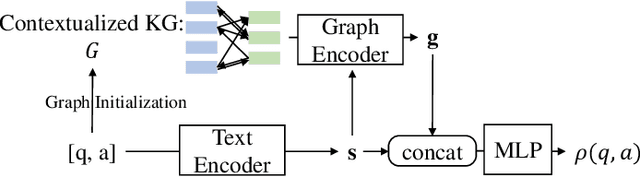
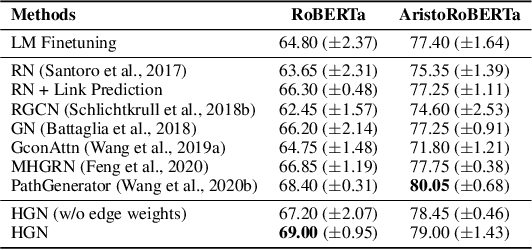
Recently, neural-symbolic architectures have achieved success on commonsense reasoning through effectively encoding relational structures retrieved from external knowledge graphs (KGs) and obtained state-of-the-art results in tasks such as (commonsense) question answering and natural language inference. However, these methods rely on quality and contextualized knowledge structures (i.e., fact triples) that are retrieved at the pre-processing stage but overlook challenges caused by incompleteness of a KG, limited expressiveness of its relations, and retrieved facts irrelevant to the reasoning context. In this paper, we present a novel neural-symbolic model, named Hybrid Graph Network (HGN), which jointly generates feature representations for new triples (as a complement to existing edges in the KG), determines the relevance of the triples to the reasoning context, and learns graph module parameters for encoding the relational information. Our model learns a compact graph structure (comprising both extracted and generated edges) through filtering edges that are unhelpful to the reasoning process. We show marked improvement on three commonsense reasoning benchmarks and demonstrate the superiority of the learned graph structures with user studies.
Learning to Deceive Knowledge Graph Augmented Models via Targeted Perturbation
Oct 24, 2020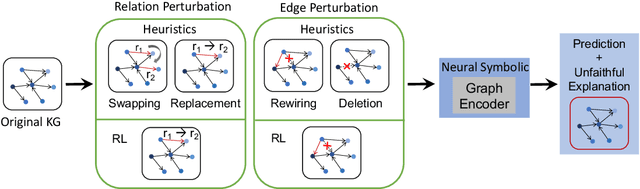
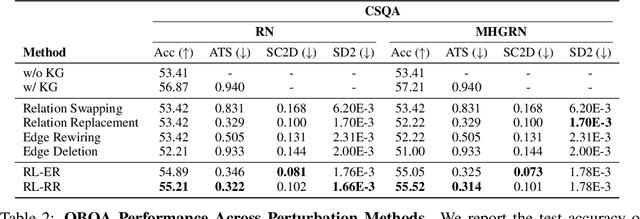
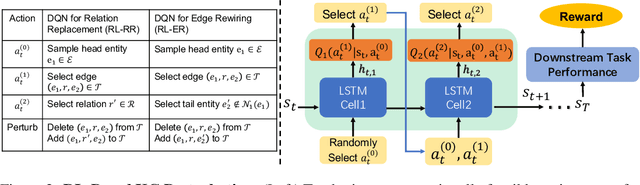
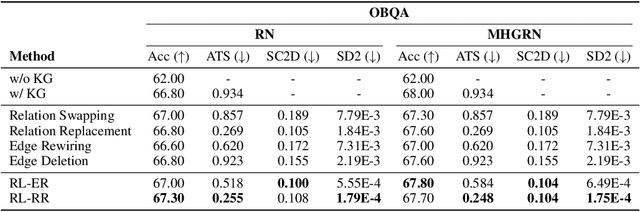
Symbolic knowledge (e.g., entities, relations, and facts in a knowledge graph) has become an increasingly popular component of neural-symbolic models applied to machine learning tasks, such as question answering and recommender systems. Besides improving downstream performance, these symbolic structures (and their associated attention weights) are often used to help explain the model's predictions and provide "insights" to practitioners. In this paper, we question the faithfulness of such symbolic explanations. We demonstrate that, through a learned strategy (or even simple heuristics), one can produce deceptively perturbed symbolic structures which maintain the downstream performance of the original structure while significantly deviating from the original semantics. In particular, we train a reinforcement learning policy to manipulate relation types or edge connections in a knowledge graph, such that the resulting downstream performance is maximally preserved. Across multiple models and tasks, our approach drastically alters knowledge graphs with little to no drop in performance. These results raise doubts about the faithfulness of explanations provided by learned symbolic structures and the reliability of current neural-symbolic models in leveraging symbolic knowledge.
Discrepancy Minimization in Domain Generalization with Generative Nearest Neighbors
Jul 28, 2020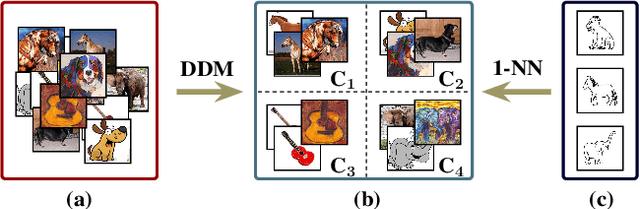
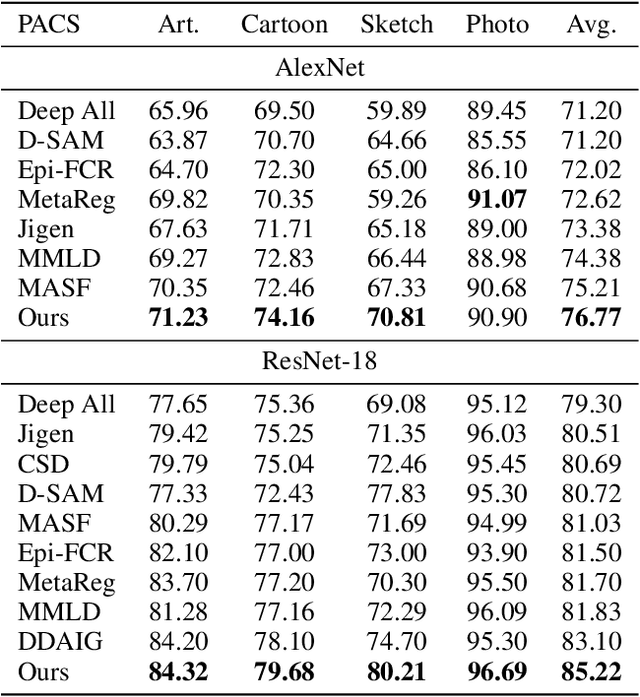

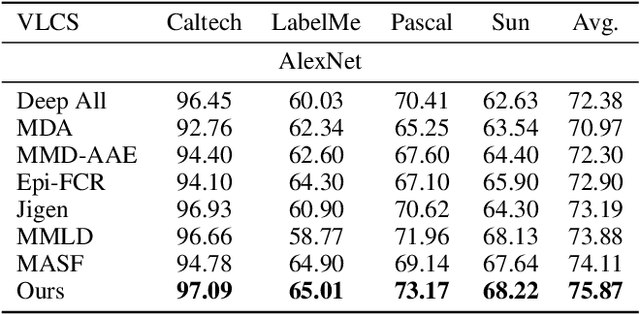
Domain generalization (DG) deals with the problem of domain shift where a machine learning model trained on multiple-source domains fail to generalize well on a target domain with different statistics. Multiple approaches have been proposed to solve the problem of domain generalization by learning domain invariant representations across the source domains that fail to guarantee generalization on the shifted target domain. We propose a Generative Nearest Neighbor based Discrepancy Minimization (GNNDM) method which provides a theoretical guarantee that is upper bounded by the error in the labeling process of the target. We employ a Domain Discrepancy Minimization Network (DDMN) that learns domain agnostic features to produce a single source domain while preserving the class labels of the data points. Features extracted from this source domain are learned using a generative model whose latent space is used as a sampler to retrieve the nearest neighbors for the target data points. The proposed method does not require access to the domain labels (a more realistic scenario) as opposed to the existing approaches. Empirically, we show the efficacy of our method on two datasets: PACS and VLCS. Through extensive experimentation, we demonstrate the effectiveness of the proposed method that outperforms several state-of-the-art DG methods.