 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Segmentation under Joint Nonstationarity
May 19, 2026Evolving data streams induce joint nonstationarity in continual semantic segmentation, where semantic classes, input distributions, and supervision availability change simultaneously over time. This setting reflects practical structured prediction systems, yet remains largely unexplored in prior continual learning work, which typically studies these factors in isolation. We formalize continual segmentation under coupled class, domain, and label shifts and investigate learning in heterogeneous dense prediction environments with limited annotations and abundant unlabeled data. To address instability and overfitting arising from few-shot supervision under distribution drift, we introduce gradient-adaptive stabilization, a parameter-wise regularization mechanism implemented via gradient-scaled stochastic perturbations that promotes a principled stability-plasticity tradeoff. We further leverage unlabeled data through semi-supervised learning and introduce prototype anchored supervision that validates pseudo-labels via joint confidence and prototype consistency. Together, these mechanisms enable learning under joint nonstationarity in continual segmentation. Extensive empirical evaluation across class-incremental, domain-incremental, and few-shot regimes demonstrates consistent improvements over prior methods in heterogeneous structured prediction settings. Our results expose fundamental failure modes of existing continual segmentation approaches and provide insight into learning robust dense predictors in dynamically evolving environments.
GPU-Accelerated ANNS: Quantized for Speed, Built for Change
Jan 15, 2026Approximate nearest neighbor search (ANNS) is a core problem in machine learning and information retrieval applications. GPUs offer a promising path to high-performance ANNS: they provide massive parallelism for distance computations, are readily available, and can co-locate with downstream applications. Despite these advantages, current GPU-accelerated ANNS systems face three key limitations. First, real-world applications operate on evolving datasets that require fast batch updates, yet most GPU indices must be rebuilt from scratch when new data arrives. Second, high-dimensional vectors strain memory bandwidth, but current GPU systems lack efficient quantization techniques that reduce data movement without introducing costly random memory accesses. Third, the data-dependent memory accesses inherent to greedy search make overlapping compute and memory difficult, leading to reduced performance. We present Jasper, a GPU-native ANNS system with both high query throughput and updatability. Jasper builds on the Vamana graph index and overcomes existing bottlenecks via three contributions: (1) a CUDA batch-parallel construction algorithm that enables lock-free streaming insertions, (2) a GPU-efficient implementation of RaBitQ quantization that reduces memory footprint up to 8x without the random access penalties, and (3) an optimized greedy search kernel that increases compute utilization, resulting in better latency hiding and higher throughput. Our evaluation across five datasets shows that Jasper achieves up to 1.93x higher query throughput than CAGRA and achieves up to 80% peak utilization as measured by the roofline model. Jasper's construction scales efficiently and constructs indices an average of 2.4x faster than CAGRA while providing updatability that CAGRA lacks. Compared to BANG, the previous fastest GPU Vamana implementation, Jasper delivers 19-131x faster queries.
Jasper: ANNS Quantized for Speed, Built for Change on GPU
Jan 11, 2026Approximate nearest neighbor search (ANNS) is a core problem in machine learning and information retrieval applications. GPUs offer a promising path to high-performance ANNS: they provide massive parallelism for distance computations, are readily available, and can co-locate with downstream applications. Despite these advantages, current GPU-accelerated ANNS systems face three key limitations. First, real-world applications operate on evolving datasets that require fast batch updates, yet most GPU indices must be rebuilt from scratch when new data arrives. Second, high-dimensional vectors strain memory bandwidth, but current GPU systems lack efficient quantization techniques that reduce data movement without introducing costly random memory accesses. Third, the data-dependent memory accesses inherent to greedy search make overlapping compute and memory difficult, leading to reduced performance. We present Jasper, a GPU-native ANNS system with both high query throughput and updatability. Jasper builds on the Vamana graph index and overcomes existing bottlenecks via three contributions: (1) a CUDA batch-parallel construction algorithm that enables lock-free streaming insertions, (2) a GPU-efficient implementation of RaBitQ quantization that reduces memory footprint up to 8x without the random access penalties, and (3) an optimized greedy search kernel that increases compute utilization, resulting in better latency hiding and higher throughput. Our evaluation across five datasets shows that Jasper achieves up to 1.93x higher query throughput than CAGRA and achieves up to 80% peak utilization as measured by the roofline model. Jasper's construction scales efficiently and constructs indices an average of 2.4x faster than CAGRA while providing updatability that CAGRA lacks. Compared to BANG, the previous fastest GPU Vamana implementation, Jasper delivers 19-131x faster queries.
A Language-Guided Benchmark for Weakly Supervised Open Vocabulary Semantic Segmentation
Feb 27, 2023Increasing attention is being diverted to data-efficient problem settings like Open Vocabulary Semantic Segmentation (OVSS) which deals with segmenting an arbitrary object that may or may not be seen during training. The closest standard problems related to OVSS are Zero-Shot and Few-Shot Segmentation (ZSS, FSS) and their Cross-dataset variants where zero to few annotations are needed to segment novel classes. The existing FSS and ZSS methods utilize fully supervised pixel-labelled seen classes to segment unseen classes. Pixel-level labels are hard to obtain, and using weak supervision in the form of inexpensive image-level labels is often more practical. To this end, we propose a novel unified weakly supervised OVSS pipeline that can perform ZSS, FSS and Cross-dataset segmentation on novel classes without using pixel-level labels for either the base (seen) or the novel (unseen) classes in an inductive setting. We propose Weakly-Supervised Language-Guided Segmentation Network (WLSegNet), a novel language-guided segmentation pipeline that i) learns generalizable context vectors with batch aggregates (mean) to map class prompts to image features using frozen CLIP (a vision-language model) and ii) decouples weak ZSS/FSS into weak semantic segmentation and Zero-Shot segmentation. The learned context vectors avoid overfitting on seen classes during training and transfer better to novel classes during testing. WLSegNet avoids fine-tuning and the use of external datasets during training. The proposed pipeline beats existing methods for weak generalized Zero-Shot and weak Few-Shot semantic segmentation by 39 and 3 mIOU points respectively on PASCAL VOC and weak Few-Shot semantic segmentation by 5 mIOU points on MS COCO. On a harder setting of 2-way 1-shot weak FSS, WLSegNet beats the baselines by 13 and 22 mIOU points on PASCAL VOC and MS COCO, respectively.
Adversarially Robust Prototypical Few-shot Segmentation with Neural-ODEs
Oct 07, 2022Few-shot Learning (FSL) methods are being adopted in settings where data is not abundantly available. This is especially seen in medical domains where the annotations are expensive to obtain. Deep Neural Networks have been shown to be vulnerable to adversarial attacks. This is even more severe in the case of FSL due to the lack of a large number of training examples. In this paper, we provide a framework to make few-shot segmentation models adversarially robust in the medical domain where such attacks can severely impact the decisions made by clinicians who use them. We propose a novel robust few-shot segmentation framework, Prototypical Neural Ordinary Differential Equation (PNODE), that provides defense against gradient-based adversarial attacks. We show that our framework is more robust compared to traditional adversarial defense mechanisms such as adversarial training. Adversarial training involves increased training time and shows robustness to limited types of attacks depending on the type of adversarial examples seen during training. Our proposed framework generalises well to common adversarial attacks like FGSM, PGD and SMIA while having the model parameters comparable to the existing few-shot segmentation models. We show the effectiveness of our proposed approach on three publicly available multi-organ segmentation datasets in both in-domain and cross-domain settings by attacking the support and query sets without the need for ad-hoc adversarial training.
Robust Prototypical Few-Shot Organ Segmentation with Regularized Neural-ODEs
Aug 26, 2022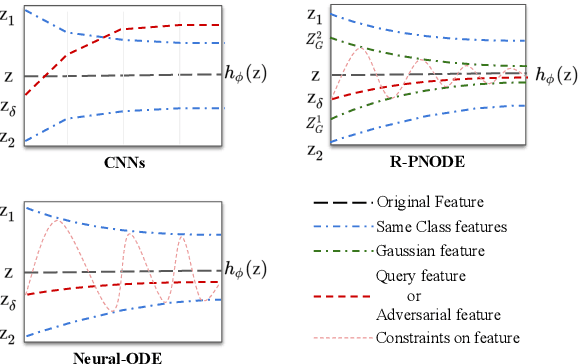
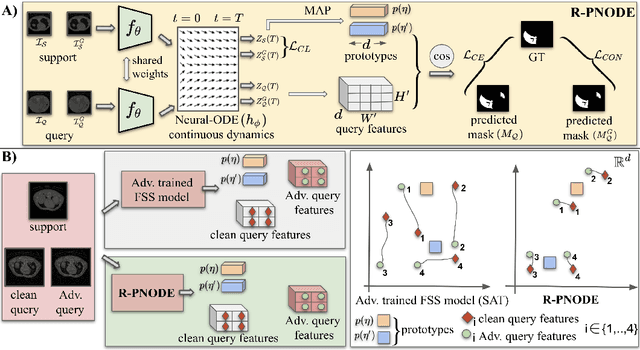


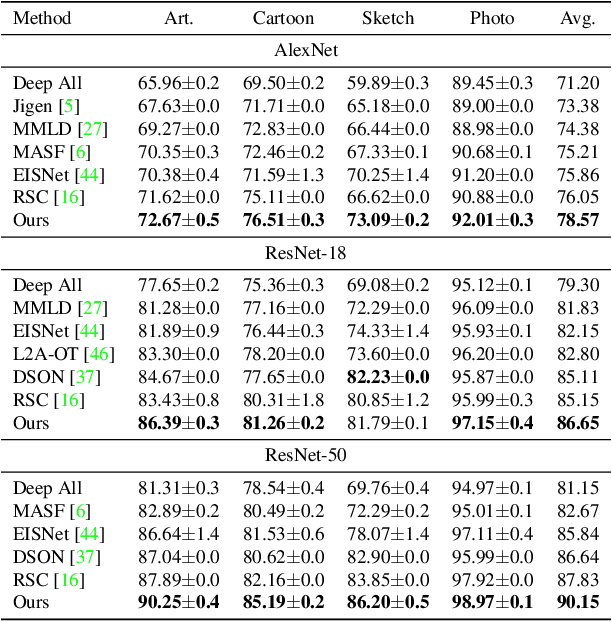
Despite the tremendous progress made by deep learning models in image semantic segmentation, they typically require large annotated examples, and increasing attention is being diverted to problem settings like Few-Shot Learning (FSL) where only a small amount of annotation is needed for generalisation to novel classes. This is especially seen in medical domains where dense pixel-level annotations are expensive to obtain. In this paper, we propose Regularized Prototypical Neural Ordinary Differential Equation (R-PNODE), a method that leverages intrinsic properties of Neural-ODEs, assisted and enhanced by additional cluster and consistency losses to perform Few-Shot Segmentation (FSS) of organs. R-PNODE constrains support and query features from the same classes to lie closer in the representation space thereby improving the performance over the existing Convolutional Neural Network (CNN) based FSS methods. We further demonstrate that while many existing Deep CNN based methods tend to be extremely vulnerable to adversarial attacks, R-PNODE exhibits increased adversarial robustness for a wide array of these attacks. We experiment with three publicly available multi-organ segmentation datasets in both in-domain and cross-domain FSS settings to demonstrate the efficacy of our method. In addition, we perform experiments with seven commonly used adversarial attacks in various settings to demonstrate R-PNODE's robustness. R-PNODE outperforms the baselines for FSS by significant margins and also shows superior performance for a wide array of attacks varying in intensity and design.
Contrastive Semi-Supervised Learning for 2D Medical Image Segmentation
Jul 10, 2021



Contrastive Learning (CL) is a recent representation learning approach, which encourages inter-class separability and intra-class compactness in learned image representations. Since medical images often contain multiple semantic classes in an image, using CL to learn representations of local features (as opposed to global) is important. In this work, we present a novel semi-supervised 2D medical segmentation solution that applies CL on image patches, instead of full images. These patches are meaningfully constructed using the semantic information of different classes obtained via pseudo labeling. We also propose a novel consistency regularization (CR) scheme, which works in synergy with CL. It addresses the problem of confirmation bias, and encourages better clustering in the feature space. We evaluate our method on four public medical segmentation datasets and a novel histopathology dataset that we introduce. Our method obtains consistent improvements over state-of-the-art semi-supervised segmentation approaches for all datasets.
Domain Generalization via Inference-time Label-Preserving Target Projections
Mar 01, 2021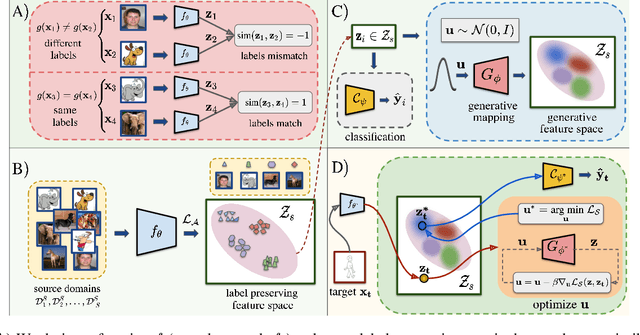
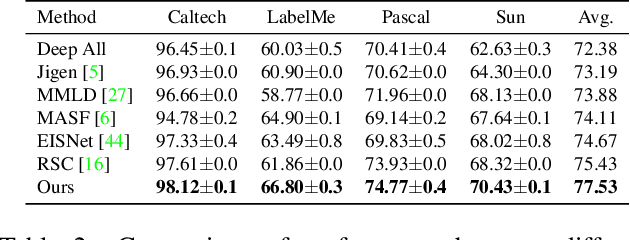
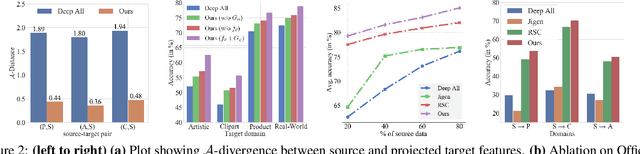
Generalization of machine learning models trained on a set of source domains on unseen target domains with different statistics, is a challenging problem. While many approaches have been proposed to solve this problem, they only utilize source data during training but do not take advantage of the fact that a single target example is available at the time of inference. Motivated by this, we propose a method that effectively uses the target sample during inference beyond mere classification. Our method has three components - (i) A label-preserving feature or metric transformation on source data such that the source samples are clustered in accordance with their class irrespective of their domain (ii) A generative model trained on the these features (iii) A label-preserving projection of the target point on the source-feature manifold during inference via solving an optimization problem on the input space of the generative model using the learned metric. Finally, the projected target is used in the classifier. Since the projected target feature comes from the source manifold and has the same label as the real target by design, the classifier is expected to perform better on it than the true target. We demonstrate that our method outperforms the state-of-the-art Domain Generalization methods on multiple datasets and tasks.
Discrepancy Minimization in Domain Generalization with Generative Nearest Neighbors
Jul 28, 2020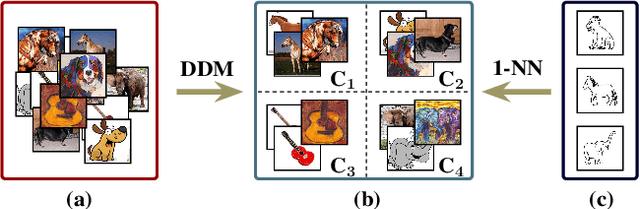
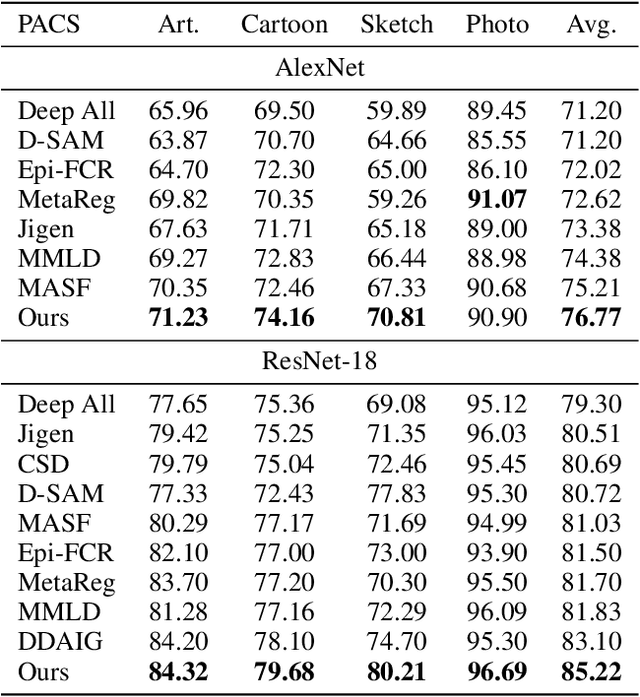

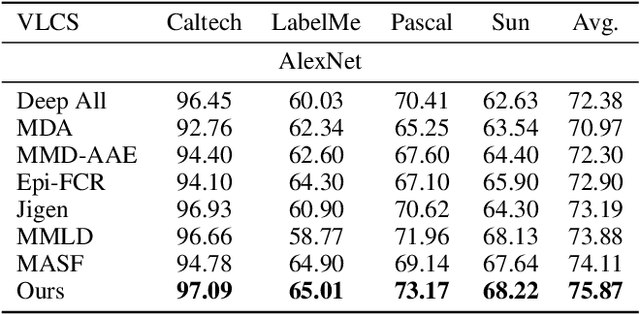
Domain generalization (DG) deals with the problem of domain shift where a machine learning model trained on multiple-source domains fail to generalize well on a target domain with different statistics. Multiple approaches have been proposed to solve the problem of domain generalization by learning domain invariant representations across the source domains that fail to guarantee generalization on the shifted target domain. We propose a Generative Nearest Neighbor based Discrepancy Minimization (GNNDM) method which provides a theoretical guarantee that is upper bounded by the error in the labeling process of the target. We employ a Domain Discrepancy Minimization Network (DDMN) that learns domain agnostic features to produce a single source domain while preserving the class labels of the data points. Features extracted from this source domain are learned using a generative model whose latent space is used as a sampler to retrieve the nearest neighbors for the target data points. The proposed method does not require access to the domain labels (a more realistic scenario) as opposed to the existing approaches. Empirically, we show the efficacy of our method on two datasets: PACS and VLCS. Through extensive experimentation, we demonstrate the effectiveness of the proposed method that outperforms several state-of-the-art DG methods.
Unsupervised Domain Adaptation for Semantic Segmentation of NIR Images through Generative Latent Search
Jul 17, 2020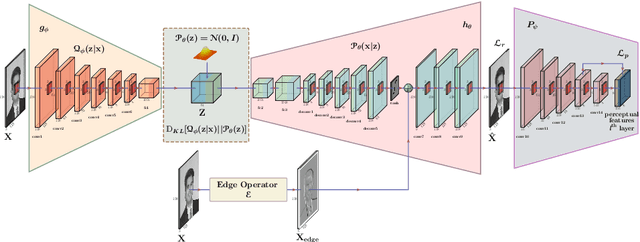
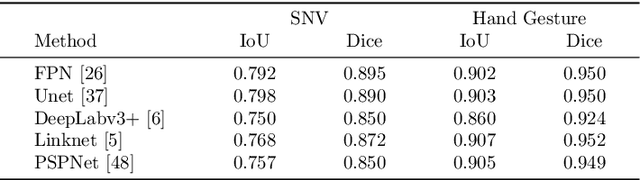

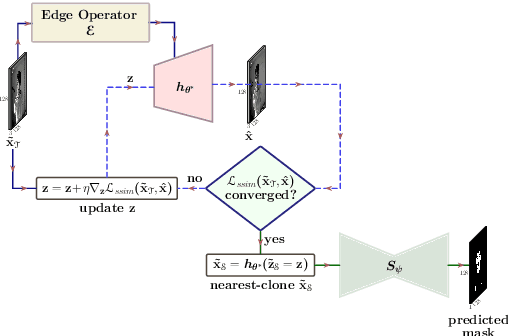
Segmentation of the pixels corresponding to human skin is an essential first step in multiple applications ranging from surveillance to heart-rate estimation from remote-photoplethysmography. However, the existing literature considers the problem only in the visible-range of the EM-spectrum which limits their utility in low or no light settings where the criticality of the application is higher. To alleviate this problem, we consider the problem of skin segmentation from the Near-infrared images. However, Deep learning based state-of-the-art segmentation techniques demands large amounts of labelled data that is unavailable for the current problem. Therefore we cast the skin segmentation problem as that of target-independent Unsupervised Domain Adaptation (UDA) where we use the data from the Red-channel of the visible-range to develop skin segmentation algorithm on NIR images. We propose a method for target-independent segmentation where the 'nearest-clone' of a target image in the source domain is searched and used as a proxy in the segmentation network trained only on the source domain. We prove the existence of 'nearest-clone' and propose a method to find it through an optimization algorithm over the latent space of a Deep generative model based on variational inference. We demonstrate the efficacy of the proposed method for NIR skin segmentation over the state-of-the-art UDA segmentation methods on the two newly created skin segmentation datasets in NIR domain despite not having access to the target NIR data. Additionally, we report state-of-the-art results for adaption from Synthia to Cityscapes which is a popular setting in Unsupervised Domain Adaptation for semantic segmentation. The code and datasets are available at https://github.com/ambekarsameer96/GLSS.