 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Minimization without Model Collapse: Mitigating Prediction Bias in Medical Imaging
Jun 01, 2026Entropy minimization (EM) is the dominant objective for test-time adaptation, yet its failure mode, model collapse, remains poorly understood. In this work, we show that distribution shifts can cause feature clusters corresponding to distinct classes in the model's representation space to merge, while the decision boundary remains fixed. This induces a systematic skew in the predicted class distribution, referred to as prediction bias. Prediction bias refers to a shift in the predicted class distribution, with some classes overrepresented and others suppressed. We show that entropy minimization amplifies this prediction bias by tightening the existing clusters, reinforcing the incorrect groupings until all predictions collapse to a trivial solution. Next, to demonstrate the significance of prediction bias and mitigate it, we further propose Distribution Shift Bias Reduction (DSBR), a bias-correcting objective that specifically targets this failure mode by equalizing the contribution of each predicted class to the unsupervised entropy minimization loss. To study this failure mode, we design suitable adaptation settings using four medical-imaging datasets and additionally evaluate on ImageNet-C. We find that DSBR consistently stabilizes test-time adaptation, prevents model collapse, and matches or outperforms state-of-the-art methods. Moreover, DSBR operates solely at test-time.
The Mean is the Mirage: Entropy-Adaptive Model Merging under Heterogeneous Domain Shifts in Medical Imaging
Feb 24, 2026Model merging under unseen test-time distribution shifts often renders naive strategies, such as mean averaging unreliable. This challenge is especially acute in medical imaging, where models are fine-tuned locally at clinics on private data, producing domain-specific models that differ by scanner, protocol, and population. When deployed at an unseen clinical site, test cases arrive in unlabeled, non-i.i.d. batches, and the model must adapt immediately without labels. In this work, we introduce an entropy-adaptive, fully online model-merging method that yields a batch-specific merged model via only forward passes, effectively leveraging target information. We further demonstrate why mean merging is prone to failure and misaligned under heterogeneous domain shifts. Next, we mitigate encoder classifier mismatch by decoupling the encoder and classification head, merging with separate merging coefficients. We extensively evaluate our method with state-of-the-art baselines using two backbones across nine medical and natural-domain generalization image classification datasets, showing consistent gains across standard evaluation and challenging scenarios. These performance gains are achieved while retaining single-model inference at test-time, thereby demonstrating the effectiveness of our method.
Selective Test-Time Adaptation for Unsupervised Anomaly Detection using Neural Implicit Representations
Oct 04, 2024



Deep learning models in medical imaging often encounter challenges when adapting to new clinical settings unseen during training. Test-time adaptation offers a promising approach to optimize models for these unseen domains, yet its application in anomaly detection (AD) remains largely unexplored. AD aims to efficiently identify deviations from normative distributions; however, full adaptation, including pathological shifts, may inadvertently learn the anomalies it intends to detect. We introduce a novel concept of \emph{selective} test-time adaptation that utilizes the inherent characteristics of deep pre-trained features to adapt \emph{selectively} in a zero-shot manner to any test image from an unseen domain. This approach employs a model-agnostic, lightweight multi-layer perceptron for neural implicit representations, enabling the adaptation of outputs from any reconstruction-based AD method without altering the source-trained model. Rigorous validation in brain AD demonstrated that our strategy substantially enhances detection accuracy for multiple conditions and different target distributions. Specifically, our method improves the detection rates by up to 78\% for enlarged ventricles and 24\% for edemas.
Learning Variational Neighbor Labels for Test-Time Domain Generalization
Jul 08, 2023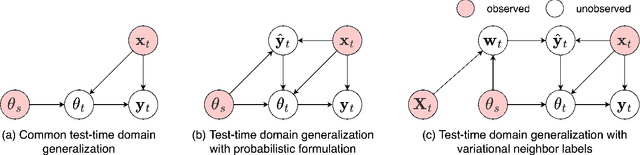
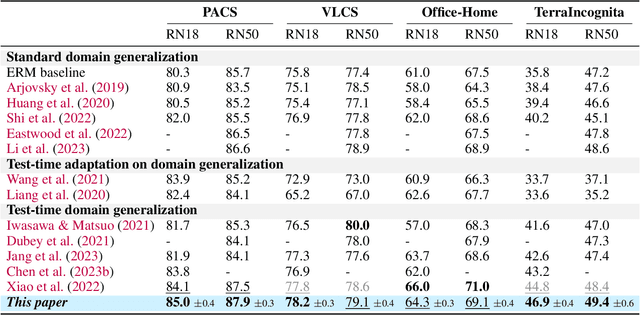

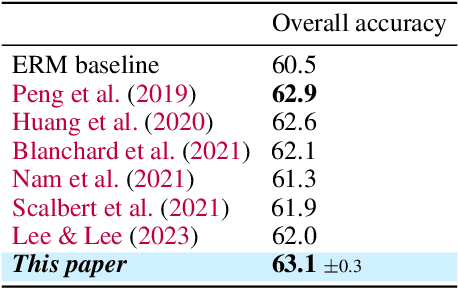
This paper strives for domain generalization, where models are trained exclusively on source domains before being deployed at unseen target domains. We follow the strict separation of source training and target testing but exploit the value of the unlabeled target data itself during inference. We make three contributions. First, we propose probabilistic pseudo-labeling of target samples to generalize the source-trained model to the target domain at test time. We formulate the generalization at test time as a variational inference problem by modeling pseudo labels as distributions to consider the uncertainty during generalization and alleviate the misleading signal of inaccurate pseudo labels. Second, we learn variational neighbor labels that incorporate the information of neighboring target samples to generate more robust pseudo labels. Third, to learn the ability to incorporate more representative target information and generate more precise and robust variational neighbor labels, we introduce a meta-generalization stage during training to simulate the generalization procedure. Experiments on six widely-used datasets demonstrate the benefits, abilities, and effectiveness of our proposal.
SKDCGN: Source-free Knowledge Distillation of Counterfactual Generative Networks using cGANs
Aug 10, 2022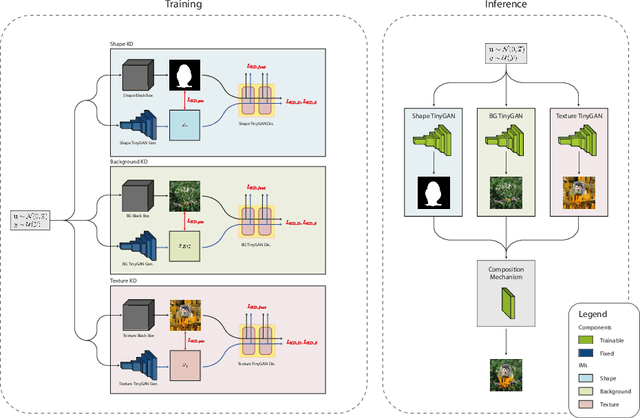


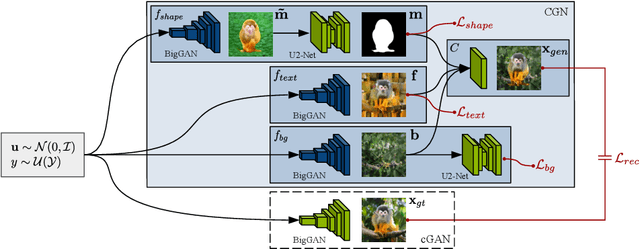
With the usage of appropriate inductive biases, Counterfactual Generative Networks (CGNs) can generate novel images from random combinations of shape, texture, and background manifolds. These images can be utilized to train an invariant classifier, avoiding the wide spread problem of deep architectures learning spurious correlations rather than meaningful ones. As a consequence, out-of-domain robustness is improved. However, the CGN architecture comprises multiple over parameterized networks, namely BigGAN and U2-Net. Training these networks requires appropriate background knowledge and extensive computation. Since one does not always have access to the precise training details, nor do they always possess the necessary knowledge of counterfactuals, our work addresses the following question: Can we use the knowledge embedded in pre-trained CGNs to train a lower-capacity model, assuming black-box access (i.e., only access to the pretrained CGN model) to the components of the architecture? In this direction, we propose a novel work named SKDCGN that attempts knowledge transfer using Knowledge Distillation (KD). In our proposed architecture, each independent mechanism (shape, texture, background) is represented by a student 'TinyGAN' that learns from the pretrained teacher 'BigGAN'. We demonstrate the efficacy of the proposed method using state-of-the-art datasets such as ImageNet, and MNIST by using KD and appropriate loss functions. Moreover, as an additional contribution, our paper conducts a thorough study on the composition mechanism of the CGNs, to gain a better understanding of how each mechanism influences the classification accuracy of an invariant classifier. Code available at: https://github.com/ambekarsameer96/SKDCGN
Twin Augmented Architectures for Robust Classification of COVID-19 Chest X-Ray Images
Feb 16, 2021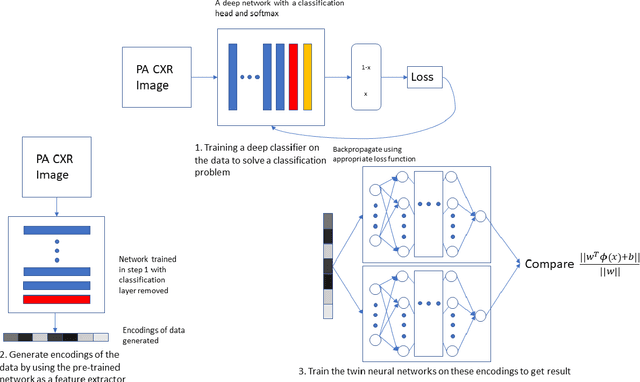
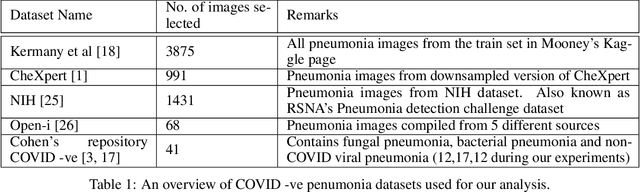
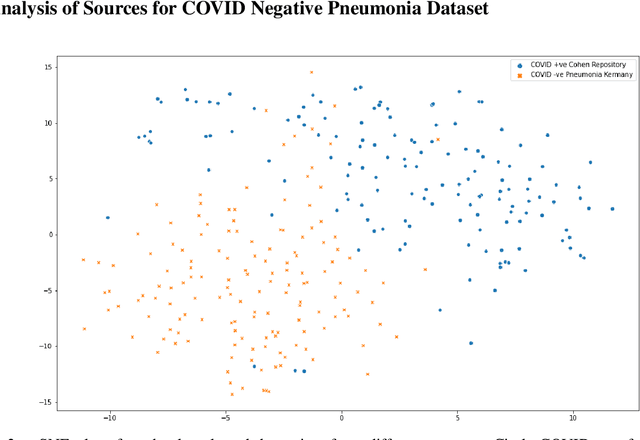
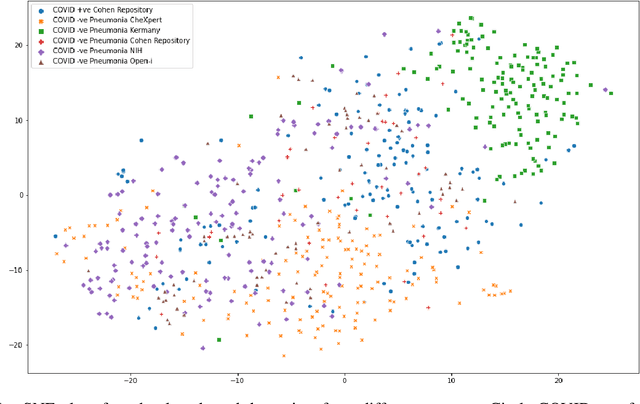
The gold standard for COVID-19 is RT-PCR, testing facilities for which are limited and not always optimally distributed. Test results are delayed, which impacts treatment. Expert radiologists, one of whom is a co-author, are able to diagnose COVID-19 positivity from Chest X-Rays (CXR) and CT scans, that can facilitate timely treatment. Such diagnosis is particularly valuable in locations lacking radiologists with sufficient expertise and familiarity with COVID-19 patients. This paper has two contributions. One, we analyse literature on CXR based COVID-19 diagnosis. We show that popular choices of dataset selection suffer from data homogeneity, leading to misleading results. We compile and analyse a viable benchmark dataset from multiple existing heterogeneous sources. Such a benchmark is important for realistically testing models. Our second contribution relates to learning from imbalanced data. Datasets for COVID X-Ray classification face severe class imbalance, since most subjects are COVID -ve. Twin Support Vector Machines (Twin SVM) and Twin Neural Networks (Twin NN) have, in recent years, emerged as effective ways of handling skewed data. We introduce a state-of-the-art technique, termed as Twin Augmentation, for modifying popular pre-trained deep learning models. Twin Augmentation boosts the performance of a pre-trained deep neural network without requiring re-training. Experiments show, that across a multitude of classifiers, Twin Augmentation is very effective in boosting the performance of given pre-trained model for classification in imbalanced settings.
Unsupervised Domain Adaptation for Semantic Segmentation of NIR Images through Generative Latent Search
Jul 17, 2020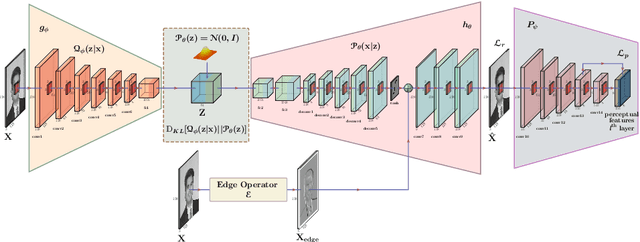
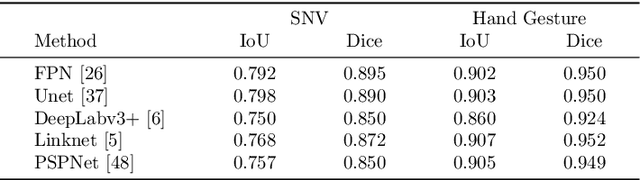

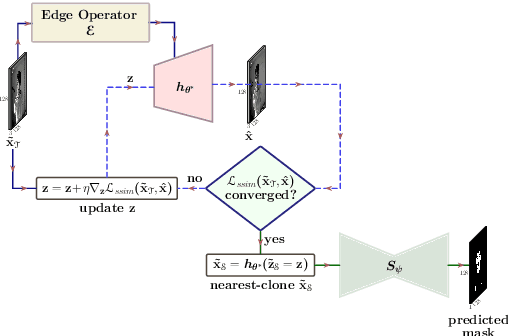
Segmentation of the pixels corresponding to human skin is an essential first step in multiple applications ranging from surveillance to heart-rate estimation from remote-photoplethysmography. However, the existing literature considers the problem only in the visible-range of the EM-spectrum which limits their utility in low or no light settings where the criticality of the application is higher. To alleviate this problem, we consider the problem of skin segmentation from the Near-infrared images. However, Deep learning based state-of-the-art segmentation techniques demands large amounts of labelled data that is unavailable for the current problem. Therefore we cast the skin segmentation problem as that of target-independent Unsupervised Domain Adaptation (UDA) where we use the data from the Red-channel of the visible-range to develop skin segmentation algorithm on NIR images. We propose a method for target-independent segmentation where the 'nearest-clone' of a target image in the source domain is searched and used as a proxy in the segmentation network trained only on the source domain. We prove the existence of 'nearest-clone' and propose a method to find it through an optimization algorithm over the latent space of a Deep generative model based on variational inference. We demonstrate the efficacy of the proposed method for NIR skin segmentation over the state-of-the-art UDA segmentation methods on the two newly created skin segmentation datasets in NIR domain despite not having access to the target NIR data. Additionally, we report state-of-the-art results for adaption from Synthia to Cityscapes which is a popular setting in Unsupervised Domain Adaptation for semantic segmentation. The code and datasets are available at https://github.com/ambekarsameer96/GLSS.